Python 操作 Excel
常用工具
數據處理是 Python 的一大應用場景,而 Excel 又是當前最流行的數據處理軟件。因此用 Python 進行數據處理時,很容易會和 Excel 打起交道。得益於前人的辛勤勞作,Python 處理 Excel 已有很多現成的輪子,比如 xlrd & xlwt & xlutils 、 XlsxWriter 、 OpenPyXL ,而在 Windows 平台上可以直接調用 Microsoft Excel 的開放接口,這些都是比較常用的工具,還有其他一些優秀的工具這里就不一一介紹,接下來我們通過一個表格展示各工具之間的特點:
| 類型 | xlrd&xlwt&xlutils | XlsxWriter | OpenPyXL | Excel開放接口 |
|---|---|---|---|---|
| 讀取 | 支持 | 不支持 | 支持 | 支持 |
| 寫入 | 支持 | 支持 | 支持 | 支持 |
| 修改 | 支持 | 不支持 | 支持 | 支持 |
| xls | 支持 | 不支持 | 不支持 | 支持 |
| xlsx | 高版本 | 支持 | 支持 | 支持 |
| 大文件 | 不支持 | 支持 | 支持 | 不支持 |
| 效率 | 快 | 快 | 快 | 超慢 |
| 功能 | 較弱 | 強大 | 一般 | 超強大 |
以上可以根據需求不同,選擇合適的工具,現在為大家主要介紹下最常用的 xlrd & xlwt & xlutils 系列工具的使用。
xlrd & xlwt & xlutils 介紹
xlrd&xlwt&xlutils 是由以下三個庫組成:
xlrd:用於讀取 Excel 文件;xlwt:用於寫入 Excel 文件;xlutils:用於操作 Excel 文件的實用工具,比如復制、分割、篩選等;
安裝庫
安裝比較簡單,直接用 pip 工具安裝三個庫即可,安裝命令如下:
$ pip install xlrd xlwt xlutils
1
復制代碼


寫入 Excel
接下來我們就從寫入 Excel 開始,話不多說直接看代碼如下:
# 導入 xlwt 庫
import xlwt
# 創建 xls 文件對象
wb = xlwt.Workbook()
# 新增兩個表單頁
sh1 = wb.add_sheet('成績')
sh2 = wb.add_sheet('匯總')
# 然后按照位置來添加數據,第一個參數是行,第二個參數是列
# 寫入第一個sheet
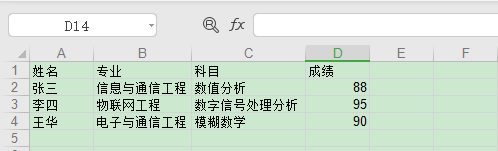
sh1.write(0, 0, '姓名')
sh1.write(0, 1, '專業')
sh1.write(0, 2, '科目')
sh1.write(0, 3, '成績')
sh1.write(1, 0, '張三')
sh1.write(1, 1, '信息與通信工程')
sh1.write(1, 2, '數值分析')
sh1.write(1, 3, 88)
sh1.write(2, 0, '李四')
sh1.write(2, 1, '物聯網工程')
sh1.write(2, 2, '數字信號處理分析')
sh1.write(2, 3, 95)
sh1.write(3, 0, '王華')
sh1.write(3, 1, '電子與通信工程')
sh1.write(3, 2, '模糊數學')
sh1.write(3, 3, 90)
# 寫入第二個sheet
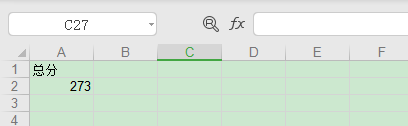
sh2.write(0, 0, '總分')
sh2.write(1, 0, 273)
# 最后保存文件即可
wb.save('test.xls')
復制代碼運行代碼,結果會看到生成名為 test.xls 的 Excel 文件,打開文件查看如下圖所示:
以上就是寫入 Excel 的代碼,是不是很簡單,下面我們再來看下讀取 Excel 該如何操作。
讀取 Excel
讀取 Excel 其實也不難,請看如下代碼:
# 導入 xlrd 庫
import xlrd
# 打開剛才我們寫入的 test_w.xls 文件
wb = xlrd.open_workbook("test_w.xls")
# 獲取並打印 sheet 數量
print( "sheet 數量:", wb.nsheets)
# 獲取並打印 sheet 名稱
print( "sheet 名稱:", wb.sheet_names())
# 根據 sheet 索引獲取內容
sh1 = wb.sheet_by_index(0)
# 或者
# 也可根據 sheet 名稱獲取內容
# sh = wb.sheet_by_name('成績')
# 獲取並打印該 sheet 行數和列數
print( u"sheet %s 共 %d 行 %d 列" % (sh1.name, sh1.nrows, sh1.ncols))
# 獲取並打印某個單元格的值
print( "第一行第二列的值為:", sh1.cell_value(0, 1))
# 獲取整行或整列的值
rows = sh1.row_values(0) # 獲取第一行內容
cols = sh1.col_values(1) # 獲取第二列內容
# 打印獲取的行列值
print( "第一行的值為:", rows)
print( "第二列的值為:", cols)
# 獲取單元格內容的數據類型
print( "第二行第一列的值類型為:", sh1.cell(1, 0).ctype)
# 遍歷所有表單內容
for sh in wb.sheets():
for r in range(sh.nrows):
# 輸出指定行
print( sh.row(r))
復制代碼輸出如下結果:

細心的朋友可能注意到,這里我們可以獲取到 單元格的類型,上面我們讀取類型時獲取的是
數字1,那1表示什么類型,又都有什么類型呢?別急下面我們通過一個表格展示下:
| 數值 | 類型 | 說明 |
|---|---|---|
| 0 | empty | 空 |
| 1 | string | 字符串 |
| 2 | number | 數字 |
| 3 | date | 日期 |
| 4 | boolean | 布爾值 |
| 5 | error | 錯誤 |
通過上面表格,我們可以知道剛獲取單元格類型返回的數字1對應的就是字符串類型。
修改 excel
上面說了寫入和讀取 Excel 內容,接下來我們就說下更新修改 Excel 該如何操作,修改時就需要用到 xlutils 中的方法了。直接上代碼,來看下最簡單的修改操作:
# 導入相應模塊
import xlrd
from xlutils.copy import copy
# 打開 excel 文件
readbook = xlrd.open_workbook("test_w.xls")
# 復制一份
wb = copy(readbook)
# 選取第一個表單
sh1 = wb.get_sheet(0)
# 在第五行新增寫入數據
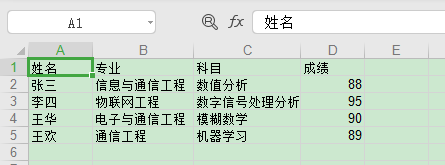
sh1.write(4, 0, '王歡')
sh1.write(4, 1, '通信工程')
sh1.write(4, 2, '機器學習')
sh1.write(4, 3, 89)
# 選取第二個表單
sh1 = wb.get_sheet(1)
# 替換總成績數據
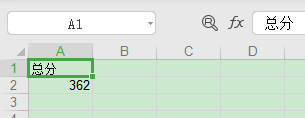
sh1.write(1, 0, 362)
# 保存
wb.save('test.xls')
復制代碼從上面代碼可以看出,這里的修改 Excel 是通過 xlutils 庫的 copy 方法將原來的 Excel 整個復制一份,然后再做修改操作,最后再保存。 看下修改結果如下:
格式轉換操作
在平時我們使用 Excel 時會對數據進行一下格式化,或者樣式設置,在這里把上面介紹寫入的代碼簡單修改下,使輸出的格式稍微改變一下,代碼如下:
# 導入 xlwt 庫
import xlwt
# 設置寫出格式字體紅色加粗
styleBR = xlwt.easyxf('font: name Times New Roman, color-index red, bold on')
# 設置數字型格式為小數點后保留兩位
styleNum = xlwt.easyxf(num_format_str='#,##0.00')
# 設置日期型格式顯示為YYYY-MM-DD
styleDate = xlwt.easyxf(num_format_str='YYYY-MM-DD')
# 創建 xls 文件對象
wb = xlwt.Workbook()
# 新增兩個表單頁
sh1 = wb.add_sheet('成績')
sh2 = wb.add_sheet('匯總')
# 然后按照位置來添加數據,第一個參數是行,第二個參數是列
sh1.write(0, 0, '姓名', styleBR) # 設置表頭字體為紅色加粗
sh1.write(0, 1, '日期', styleBR) # 設置表頭字體為紅色加粗
sh1.write(0, 2, '成績', styleBR) # 設置表頭字體為紅色加粗
# 插入數據
sh1.write(1, 0, '張三',)
sh1.write(1, 1, '2020-07-01', styleDate)
sh1.write(1, 2, 90, styleNum)
sh1.write(2, 0, '李四')
sh1.write(2, 1, '2020-08-02')
sh1.write(2, 2, 95, styleNum)
# 設置單元格內容居中的格式
alignment = xlwt.Alignment()
alignment.horz = xlwt.Alignment.HORZ_CENTER
style = xlwt.XFStyle()
style.alignment = alignment
# 合並A4,B4單元格,並將內容設置為居中
sh1.write_merge(3, 3, 0, 1, '總分', style)
# 通過公式,計算C2+C3單元格的和
sh1.write(3, 2, xlwt.Formula("C2+C3"))
# 對 sheet2 寫入數據
sh2.write(0, 0, '總分', styleBR)
sh2.write(1, 0, 185)
# 最后保存文件即可
wb.save('test.xls')
復制代碼輸出結果:
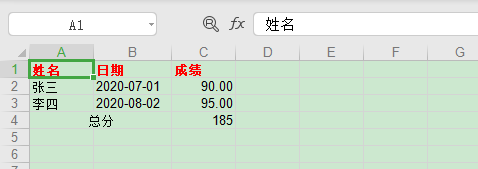
可以看出,使用代碼我們可以對字體,顏色、對齊、合並等平時 Excel 的操作進行設置,也可以格式化日期和數字類型的數據。當然了這里只是介紹了部分功能,不過這已經足夠我們日常使用了,想了解更多功能操作可以參考官網。
python-excel官網:www.python-excel.org/
Python 操作 Word
安裝 python-docx
處理 Word 需要用到 python-docx 庫,目前版本為 0.8.10 ,執行如下安裝命令:
$ pip install python-docx
################# 運行結果 ################
C:\Users\Y>pip install python-docx
Looking in indexes: https://pypi.doubanio.com/simple
Collecting python-docx
Downloading https://pypi.doubanio.com/packages/e4/83/c66a1934ed5ed8ab1dbb9931f1779079f8bca0f6bbc5793c06c4b5e7d671/python-docx-0.8.10.tar.gz (5.5MB)
|████████████████████████████████| 5.5MB 3.2MB/s
Requirement already satisfied: lxml>=2.3.2 in c:\users\y\appdata\local\programs\python\python37\lib\site-packages (from python-docx) (4.5.0)
Building wheels for collected packages: python-docx
Building wheel for python-docx (setup.py) ... done
Created wheel for python-docx: filename=python_docx-0.8.10-cp37-none-any.whl size=184496 sha256=7ac76d3eec848a255b4f197d07e7b78ab33598c814d536d9b3c90b5a3e2a57fb
Stored in directory: C:\Users\Y\AppData\Local\pip\Cache\wheels\05\7d\71\bb534b75918095724d0342119154c3d0fc035cedfe2f6c9a6c
Successfully built python-docx
Installing collected packages: python-docx
Successfully installed python-docx-0.8.10
復制代碼OK,如果提示以上信息則安裝成功。
寫入 Word
平時我們在操作 Word 寫文檔的時候,一般分為幾部分:標題、章節、段落、圖片、表格、引用以及項目符號編號等。下面我們就按這幾部分如何用 Python 操作來一一介紹。
標題
文檔標題創建比較簡單,通過 Document() 創建出一個空白文檔,只要調用 add_heading 方法就能創建標題。
# 導入庫
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
# 新建空白文檔
doc1 = Document()
# 新增文檔標題
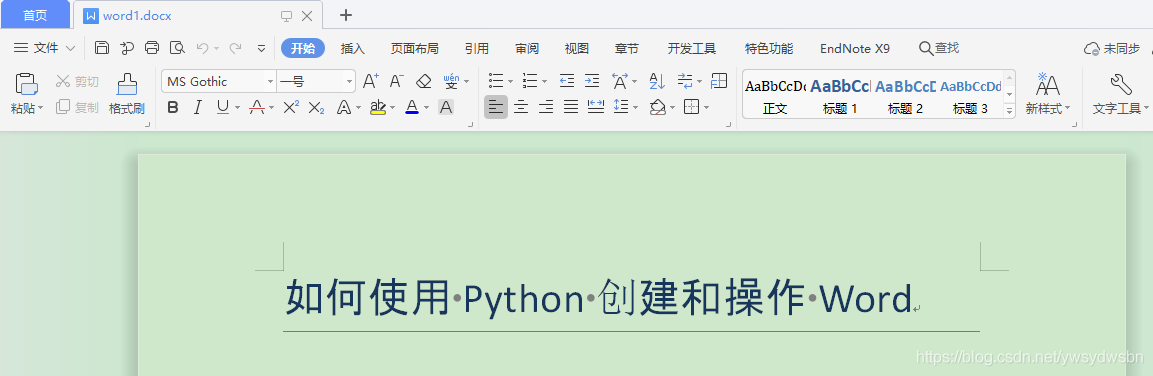
doc1.add_heading('如何使用 Python 創建和操作 Word',0)
# 保存文件
doc1.save('word1.docx')
復制代碼這樣就完成了創建文檔和文章標題的操作,下面運行程序,會生成名為 word1.docx 的文檔,打開文章顯示如下圖所示:
章節與段落
有了文章標題,下面我們來看章節和段落是怎么操作的,在上面代碼后面增加章節和段落操作的代碼如下:
# 導入庫
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
# 新建空白文檔
doc1 = Document()
# 新增文檔標題
doc1.add_heading('如何使用 Python 創建和操作 Word',0)
# 創建段落描述
doc1.add_paragraph(' Word 文檔在我們現在的生活和工作中都用的比較多,我們平時都使用 wps 或者 office 來對 Word 進行處理,可能沒想過它可以用 Python 生成,下面我們就介紹具體如何操作……')
# 創建一級標題
doc1.add_heading('安裝 python-docx 庫',1)
# 創建段落描述
doc1.add_paragraph('現在開始我們來介紹如何安裝 python-docx 庫,具體需要以下兩步操作:')
# 創建二級標題
doc1.add_heading('第一步:安裝 Python',2)
# 創建段落描述
doc1.add_paragraph('在python官網下載python安裝包進行安裝。')
# 創建三級標題
doc1.add_heading('第二步:安裝 python-docx 庫',3)
# 創建段落描述
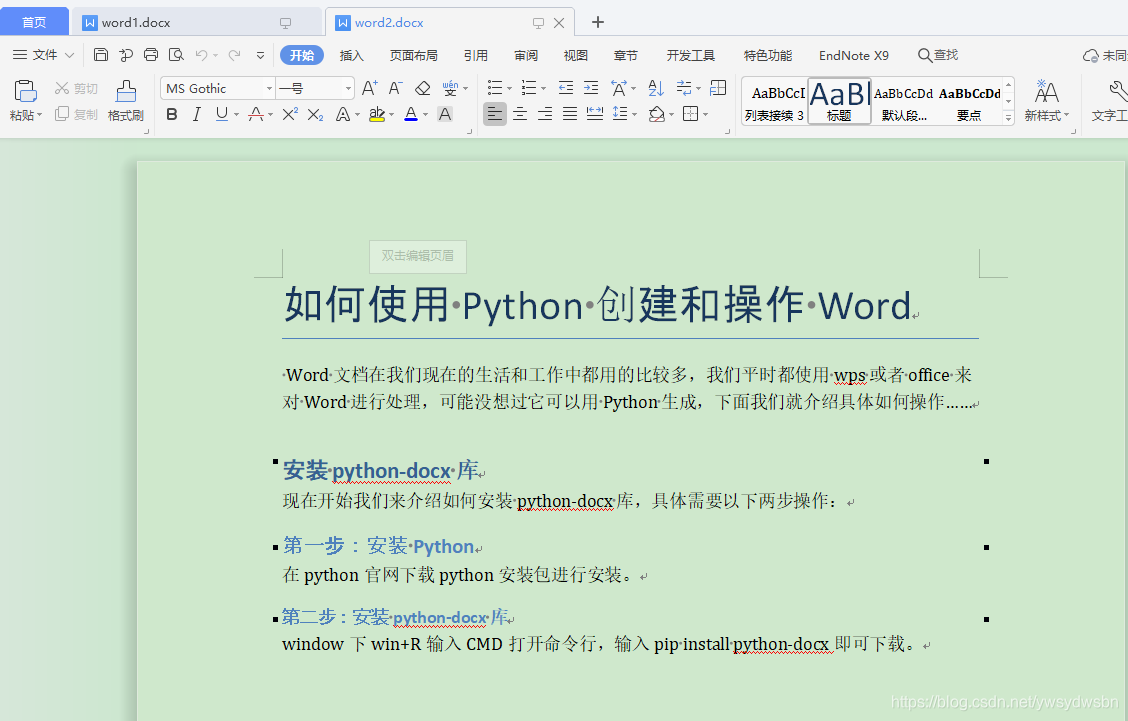
doc1.add_paragraph('window下win+R輸入CMD打開命令行,輸入pip install python-docx即可下載。')
# 保存文件
doc1.save('word2.docx')
復制代碼上面我們說了 add_heading 方法用來增加文章標題,不過通過上面代碼我們能知道,這個方法的第二個參數為數字,其實這個就是用來標示幾級標題的,在我們平時就用來標示章節。add_paragraph 方法則是用來在文章中增加段落的, 運行程序看下效果:
字體和引用
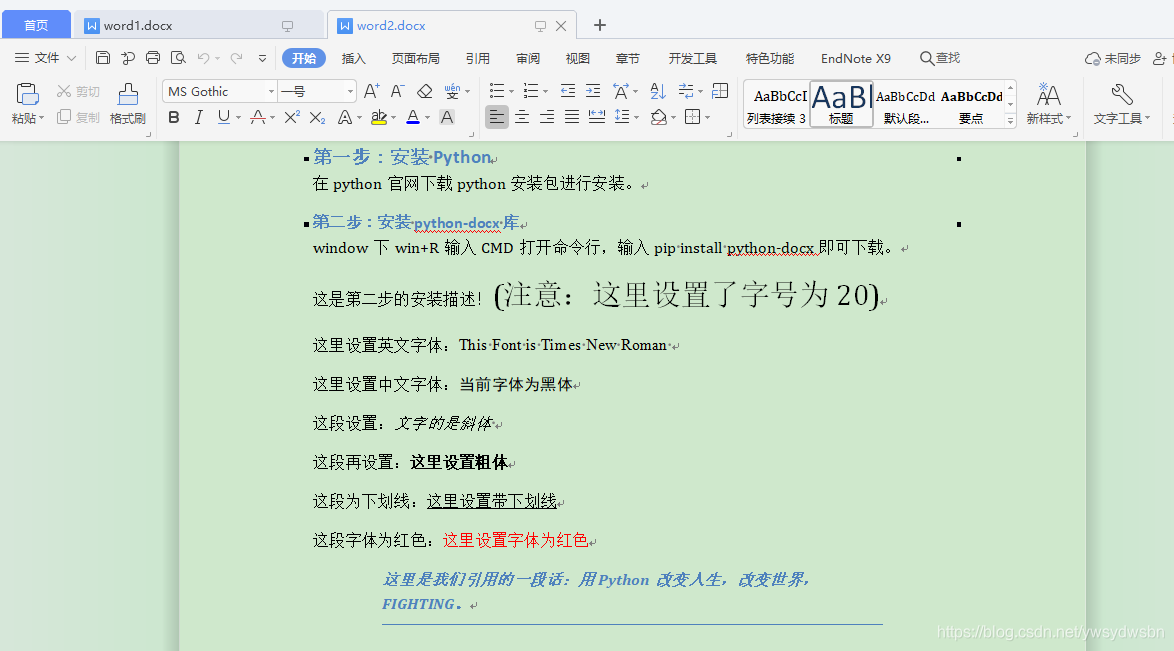
前面我們通過 add_paragraph 方法增加了三個段落,現在我們就看下如何對段落中字體如何操作,以及引用段落的操作。繼續修改以上代碼,增加對文章字體字號、加粗、傾斜等操作,具體代碼如下:
# 導入庫
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.shared import RGBColor
# 新建空白文檔
doc1 = Document()
# 新增文檔標題
doc1.add_heading('如何使用 Python 創建和操作 Word',0)
# 創建段落描述
doc1.add_paragraph(' Word 文檔在我們現在的生活和工作中都用的比較多,我們平時都使用 wps 或者 office 來對 Word 進行處理,可能沒想過它可以用 Python 生成,下面我們就介紹具體如何操作……')
# 創建一級標題
doc1.add_heading('安裝 python-docx 庫',1)
# 創建段落描述
doc1.add_paragraph('現在開始我們來介紹如何安裝 python-docx 庫,具體需要以下兩步操作:')
# 創建二級標題
doc1.add_heading('第一步:安裝 Python',2)
# 創建段落描述
doc1.add_paragraph('在python官網下載python安裝包進行安裝。')
# 創建三級標題
doc1.add_heading('第二步:安裝 python-docx 庫',3)
# 創建段落描述
doc1.add_paragraph('window下win+R輸入CMD打開命令行,輸入pip install python-docx即可下載。')
# 創建段落,添加文檔內容
paragraph = doc1.add_paragraph('這是第二步的安裝描述!')
# 段落中增加文字,並設置字體字號
run = paragraph.add_run('(注意:這里設置了字號為20)')
run.font.size = Pt(20)
# 設置英文字體
run = doc1.add_paragraph('這里設置英文字體:').add_run('This Font is Times New Roman ')
run.font.name = 'Times New Roman'
# 設置中文字體
run = doc1.add_paragraph('這里設置中文字體:').add_run('當前字體為黑體')
run.font.name='黑體'
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑體')
# 設置斜體
run = doc1.add_paragraph('這段設置:').add_run('文字的是斜體 ')
run.italic = True
# 設置粗體
run = doc1.add_paragraph('這段再設置:').add_run('這里設置粗體').bold = True
# 設置字體帶下划線
run = doc1.add_paragraph('這段為下划線:').add_run('這里設置帶下划線').underline = True
# 設置字體顏色
run = doc1.add_paragraph('這段字體為紅色:').add_run('這里設置字體為紅色')
run.font.color.rgb = RGBColor(0xFF, 0x00, 0x00)
# 增加引用
doc1.add_paragraph('這里是我們引用的一段話:用Python改變人生,改變世界,FIGHTING。', style='Intense Quote')
# 保存文件
doc1.save('word2.docx')
復制代碼上面代碼主要是針對段落字體的各種設置,每段代碼都標有注釋應該比較容易理解, 運行程序看下效果:
項目列表
我們平時在使用 Word 時,為了能展示更清晰,會用到項目符號和編號,將內容通過列表的方式展示出來,下面我們新建一個文件 word1.py 並編寫如下代碼:
# 導入庫
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
# 新建文檔
doc2 = Document()
doc2.add_paragraph('哪個不是動物:')
# 增加無序列表
doc2.add_paragraph(
'蘋果', style='List Bullet'
)
doc2.add_paragraph(
'喜洋洋', style='List Bullet'
)
doc2.add_paragraph(
'懶洋洋', style='List Bullet'
)
doc2.add_paragraph(
'沸洋洋', style='List Bullet'
)
doc2.add_paragraph(
'灰太狼', style='List Bullet'
)
doc2.add_paragraph('2020年度計划:')
# 增加有序列表
doc2.add_paragraph(
'CSDN達到博客專家', style='List Number'
)
doc2.add_paragraph(
'每周健身三天', style='List Number'
)
doc2.add_paragraph(
'每天學習一個新知識點', style='List Number'
)
doc2.add_paragraph(
'學習50本書', style='List Number'
)
doc2.add_paragraph(
'減少加班時間', style='List Number'
)
# 保存文件
doc2.save('word1.docx')
復制代碼

圖片和表格
我們平時編輯文章時,插入圖片和表格也是經常使用到的,那用 Python 該如何操作插入圖片和表格?首先我們隨便找了個圖片,我這用了 Python的logo 標志圖,文件名為 python-logo.png,利用add_picture添加圖片;利用add_table添加表格,然后在 word1.py 文件中增加如下代碼:
# 導入庫
from docx import Document
from docx.shared import Pt
from docx.shared import Inches
from docx.oxml.ns import qn
# 新建文檔
doc2 = Document()
doc2.add_paragraph('哪個不是動物:')
# 增加無序列表
doc2.add_paragraph(
'蘋果', style='List Bullet'
)
doc2.add_paragraph(
'喜洋洋', style='List Bullet'
)
doc2.add_paragraph(
'懶洋洋', style='List Bullet'
)
doc2.add_paragraph(
'沸洋洋', style='List Bullet'
)
doc2.add_paragraph(
'灰太狼', style='List Bullet'
)
doc2.add_paragraph('2020年度計划:')
# 增加有序列表
doc2.add_paragraph(
'CSDN達到博客專家', style='List Number'
)
doc2.add_paragraph(
'每周健身三天', style='List Number'
)
doc2.add_paragraph(
'每天學習一個新知識點', style='List Number'
)
doc2.add_paragraph(
'學習50本書', style='List Number'
)
doc2.add_paragraph(
'減少加班時間', style='List Number'
)
doc2.add_heading('圖片',2)
# 增加圖像
doc2.add_picture('C:/Users/Y/Pictures/python-logo.png', width=Inches(5.5))
doc2.add_heading('表格',2)
# 增加表格,這是表格頭
table = doc2.add_table(rows=1, cols=4)
hdr_cells = table.rows[0].cells
hdr_cells[0].text = '編號'
hdr_cells[1].text = '姓名'
hdr_cells[2].text = '職業'
# 這是表格數據
records = (
(1, '張三', '電工'),
(2, '張五', '老板'),
(3, '馬六', 'IT'),
(4, '李四', '工程師')
)
# 遍歷數據並展示
for id, name, work in records:
row_cells = table.add_row().cells
row_cells[0].text = str(id)
row_cells[1].text = name
row_cells[2].text = work
# 手動增加分頁
doc2.add_page_break()
# 保存文件
doc2.save('word1.docx')
復制代碼

讀取 Word 文件
上面寫了很多用 Python 創建空白 Word 文件格式化字體並保存到文件中,接下來我們再簡單介紹下如何讀取已有的 Word 文件,請看如下代碼:
# 引入庫
from docx import Document
# 打開文檔1
doc1 = Document('word1.docx')
# 讀取每段內容
pl = [ paragraph.text for paragraph in doc1.paragraphs]
print('###### 輸出word1文章的內容 ######')
# 輸出讀取到的內容
for i in pl:
print(i)
# 打開文檔2
doc2 = Document('word2.docx')
print('\n###### 輸出word2文章內容 ######')
pl2 = [ paragraph.text for paragraph in doc2.paragraphs]
# 輸出讀取到的內容
for j in pl2:
print(j)
# 讀取表格材料,並輸出結果
tables = [table for table in doc2.tables]
for table in tables:
for row in table.rows:
for cell in row.cells:
print (cell.text,end=' ')
print()
print('\n')
復制代碼以上代碼是將之前我們輸出的兩個文檔內容都讀取出來,當然這里只是打印到控制台,並沒有做其他處理。現在我們執行看下結果:

Python 操作 CSV
簡介
CSV
CSV 全稱 Comma-Separated Values,中文叫逗號分隔值或字符分隔值,它以純文本形式存儲表格數據(數字和文本),其本質就是一個字符序列,可以由任意數目的記錄組成,記錄之間以某種換行符分隔,每條記錄由字段組成,通常所有記錄具有完全相同的字段序列,字段間常用逗號或制表符進行分隔。CSV 文件格式簡單、通用,在現實中有着廣泛的應用,其中使用最多的是在程序之間轉移表格數據。
CSV 與 Excel
因為 CSV 文件與 Excel 文件默認都是用 Excel 工具打開,那他們有什么區別呢?我們通過下表簡單了解一下。
| CSV | Excel |
|---|---|
| 文件后綴為 .csv | 文件后綴為 .xls 或 .xlsx |
| 純文本文件 | 二進制文件 |
| 存儲數據不包含格式、公式等 | 不僅可以存儲數據,還可以對數據進行操作 |
| 可以通過 Excel 工具打開,也可以通過文本編輯器打開 | 只能通過 Excel 工具打開 |
| 只能編寫一次列標題 | 每一行中的每一列都有一個開始標記和結束標記 |
| 導入數據時消耗內存較少 | 數據時消耗內存較多 |
基本使用
Python 通過 csv 模塊來實現 CSV 格式文件中數據的讀寫,該模塊提供了兼容 Excel 方式輸出、讀取數據文件的功能,這樣我們無需知道 Excel 所采用 CSV 格式的細節,同樣的它還可以定義其他應用程序可用的或特定需求的 CSV 格式。
csv 模塊中使用 reader 類和 writer 類讀寫序列化的數據,使用 DictReader 類和 DictWriter 類以字典的形式讀寫數據,下面來詳細看一下相應功能。首先來看一下 csv 模塊常量信息,如下所示:
| 屬性 | 說明 |
|---|---|
| QUOTE_ALL | 指示 writer 對象給所有字段加上引號 |
| QUOTE_MINIMAL | 指示 writer 對象僅為包含特殊字符(如:定界符、引號字符、行結束符等)的字段加上引號 |
| QUOTE_NONNUMERIC | 指示 writer 對象為所有非數字字段加上引號 |
| QUOTE_NONE | 指示 writer 對象不使用引號引出字段 |
writer(csvfile, dialect=’excel’, **fmtparams)
返回一個 writer 對象,該對象負責將用戶的數據在給定的文件類對象上轉換為帶分隔符的字符串。
csvfile可以是具有 write() 方法的任何對象,如果 csvfile 是文件對象,則使用 newline=’’ 打開;- 可選參數
dialect 是用於不同的 CSV 變種的特定參數組; - 可選關鍵字參數
fmtparams可以覆寫當前變種格式中的單個格式設置。
看下示例:
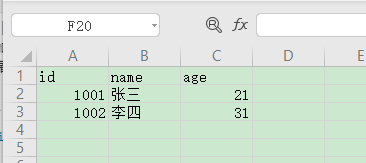
import csv
with open('test.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
# 寫入多行
data = [('1001', '張三', '21'), ('1002', '李四', '31')]
writer.writerows(data)
復制代碼
reader(csvfile, dialect=’excel’, **fmtparams)
返回一個 reader 對象,該對象將逐行遍歷 csvfile,csvfile 可以是文件對象和列表對象,如果是文件對象要使用 newline=’’ 打開。看下示例:
import csv
with open('test.csv', newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=' ')
for row in reader:
print(', '.join(row))
復制代碼

Sniffer 類
用於推斷 CSV 文件的格式,該類提供了如下兩個方法:
sniff(sample, delimiters=None)
分析給定的 sample,如果給出可選的 delimiters 參數,則該參數會被解釋為字符串,該字符串包含了可能的有效定界符。
has_header(sample)
分析示例文本(假定為 CSV 格式),如果第一行很可能是一系列列標題,則返回 True。
該類及方法使用較少,了解即可,下面通過一個示例簡單了解一下。
import csv
with open('test.csv', newline='') as csvfile:
dialect = csv.Sniffer().sniff(csvfile.read(1024))
csvfile.seek(0)
reader = csv.reader(csvfile, dialect)
for row in reader:
print(row)
復制代碼Reader 對象
Reader 對象指 DictReader 實例和 reader() 函數返回的對象,下面看一下其公開屬性和方法。
next()
返回 reader 的可迭代對象的下一行,返回值可能是列表或字典。
dialect
dialect 描述,只讀,供解析器使用。
line_num
源迭代器已經讀取了的行數。
fieldnames
字段名稱,該屬性為 DictReader 對象屬性。
Writer 對象
Writer 對象指 DictWriter 實例和 writer() 函數返回的對象,下面看一下其公開屬性和方法。
writerow(row)
將參數 row 寫入 writer 的文件對象。
writerows(rows)
將 rows(即能迭代出多個上述 row 對象的迭代器)中的所有元素寫入 writer 的文件對象。
writeheader()
在 writer 的文件對象中,寫入一行字段名稱,該方法為 DictWriter 對象方法。
dialect
dialect 描述,只讀,供 writer 使用。
寫讀追加狀態
'r':讀
'w':寫
'a':追加
'r+' == r+w(可讀可寫,文件若不存在就報錯(IOError))
'w+' == w+r(可讀可寫,文件若不存在就創建)
'a+' ==a+r(可追加可寫,文件若不存在就創建)
對應的,如果是二進制文件,就都加一個b就好啦:
'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'