
- 「MoreThanJava」 宣揚的是 「學習,不止 CODE」,本系列 Java 基礎教程是自己在結合各方面的知識之后,對 Java 基礎的一個總回顧,旨在 「幫助新朋友快速高質量的學習」。
- 當然 不論新老朋友 我相信您都可以 從中獲益。如果覺得 「不錯」 的朋友,歡迎 「關注 + 留言 + 分享」,文末有完整的獲取鏈接,您的支持是我前進的最大的動力!
特性總覽
以下是 Java 7 中引入的部分新特性,關於 Java 7 更詳細的介紹可參考官方文檔。
-
java.lang包- Java 7 多線程下自定義類加載器的優化
-
Java 語言特性
- 改進的類型推斷;
- 使用
try-with-resources進行自動資源管理 switch支持String;catch多個異常;- 數字格式增強(允許數字字面量下划線分割);
- 二進制字面量;
- 增強的文件系統;
Fork/Join框架;
-
Java 虛擬機 (JVM)
- 提供新的 G1 收集器;
- 加強對動態調用的支持;
- 新增分層編譯支持;
- 壓縮 Oops;
- 其他優化;
-
其他;
多線程下自定義類加載器的優化
在 Java 7 之前,某些情況下的自定義類加載器容易出現死鎖問題。下面👇來簡單分析演示一下官方給的例子 (下面用中文偽代碼還原了一下):
// 類的繼承情況:
class A extends B
class C extends D
// 類加載器:
Custom Classloader CL1:
直接加載類 A
委托 CL2 加載類 B
Custom Classloader CL2:
直接加載類 C
委托 CL1 加載類 D
// 多線程下的情況:
Thread 1:
使用 CL1 加載類 A
→ 定義類 A 的時候會觸發 loadClass(B),這時會嘗試 鎖住🔐 CL2
Thread 2:
使用 CL2 加載類 C
→ 定義 C 的時候會觸發 loadClass(D),這時會嘗試 鎖住🔐 CL1
➡️ 造成 死鎖☠️
造成死鎖的重要原因出在 JDK 默認的 java.lang.ClassLoader.loadClass() 方法上:

可以看到,JDK 6 及之前的 loadClass() 的 synchronized 關鍵字是加在方法級別的,那么這就意味加載類時獲取到的是一個 ClassLoader 級別的鎖。
我們來描述一下死鎖產生的情況:
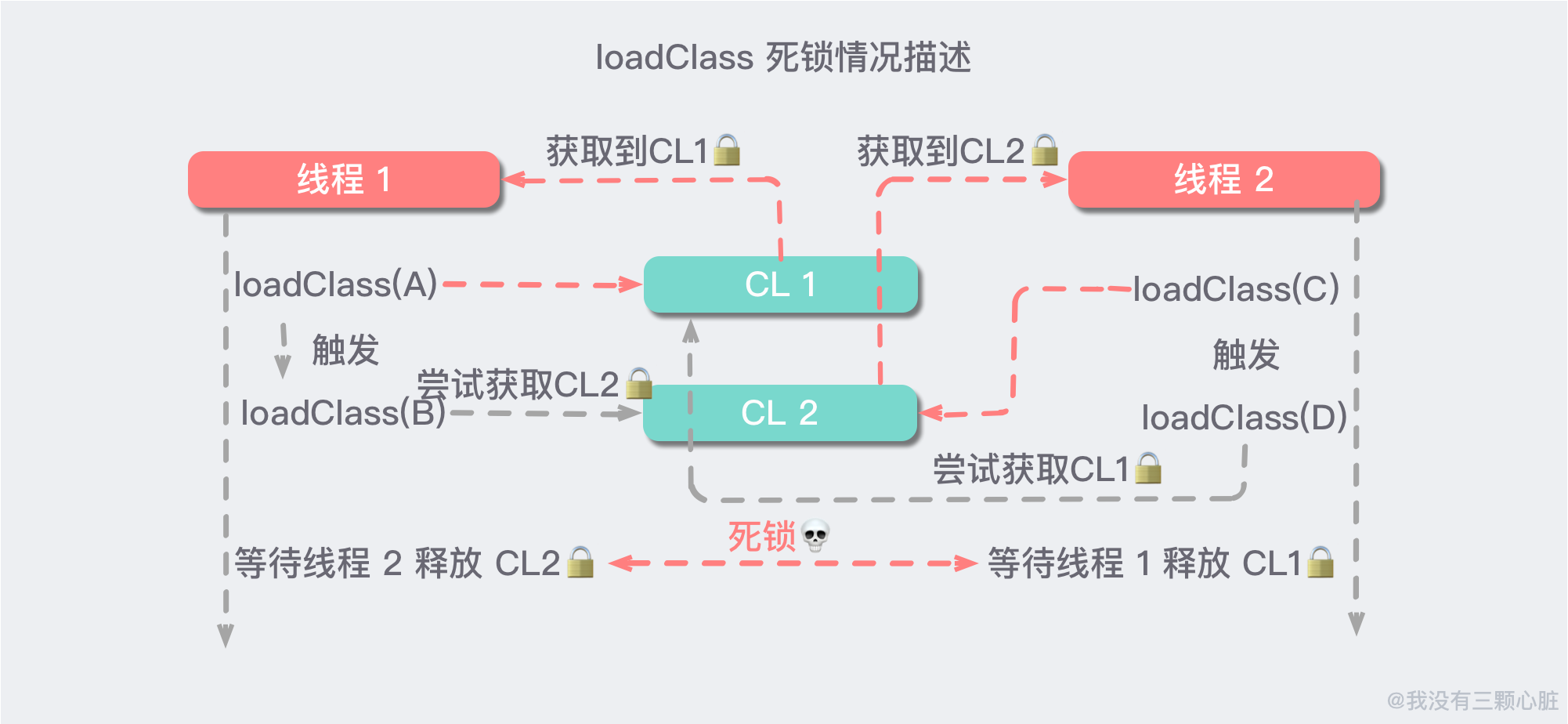
文字版的描述如下:
- 線程1:CL1 去
loadClass(A)獲取到了 CL1 對象鎖,因為 A 繼承了類 B,defineClass(A)會觸發loadClass(B),嘗試獲取 CL2 對象鎖; - 線程2:CL2 去
loadClass(C)獲取到了 CL2 對象鎖,因為 C 繼承了類 D,defineClass(C)會觸發loadClass(D),嘗試獲取 CL1 對象鎖 - 線程1 嘗試獲取 CL2 對象鎖的時候,CL2 對象鎖已經被 線程2 拿到了,那么 線程1 等待 線程2 釋放 CL2 對象鎖。
- 線程2 嘗試獲取 CL1 對像鎖的時候,CL1 對像鎖已經被 線程1 拿到了,那么 線程2 等待 線程1 釋放 CL1 對像鎖。
- 然后兩個線程一直在互相等中…從而產生了死鎖現象...
究其原因就是因為 ClassLoader 的鎖太粗粒度了。在 Java 7 中,在使用具有並行功能的類加載器的時候,將專門用一個帶有 類加載器和類名稱組合的對象 用於進行同步操作。(感興趣可以看一下 loadClass() 內部的 getClassLoadingLock(name) 方法)
Java 7 之后,之前線程死鎖的情況將不存在:
線程1:
使用CL1加載類A(鎖定CL1 + A)
defineClass A觸發
loadClass B(鎖定CL2 + B)
線程2:
使用CL2加載類C(鎖定CL2 + C)
defineClass C觸發
loadClass D(鎖定CL1 + D)
改進的類型推斷
在 Java 7 之前,使用泛型時,您必須為變量類型及其實際類型提供類型參數:
Map<String, List<String>> map = new HashMap<String, List<String>>();
在 Java 7 之后,編譯器可以通過識別空白菱形推斷出在聲明在左側定義的類型:
Map<String, List<String>> map = new HashMap<>();
自動資源管理
在 Java 7 之前,我們必須使用 finally 塊來清理資源,但防止系統崩壞的清理資源的操作並不是強制性的。在 Java 7 中,我們無需顯式的資源清理,它允許我們使用 try-with-resrouces 語句來借由 JVM 自動完成清理工作。
Java 7 之前:
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader(path));
return br.readLine();
} catch (Exception e) {
log.error("BufferedReader Exception", e);
} finally {
if (br != null) {
try {
br.close();
} catch (Exception e) {
log.error("BufferedReader close Exception", e);
}
}
}
Java 7 及之后的寫法:
try (BufferedReader br = new BufferedReader(new FileReader(path)) {
return br.readLine();
} catch (Exception e) {
log.error("BufferedReader Exception", e);
}
switch 支持 String
switch 在 Java 7 中能夠接受 String 類型的參數,實例如下:
String s = ...
switch(s) {
case "condition1":
processCondition1(s);
break;
case "condition2":
processCondition2(s);
break;
default:
processDefault(s);
break;
}
catch 多個異常
自Java 7開始,catch 中可以一次性捕捉多個異常做統一處理。示例如下:
public void handle() {
ExceptionThrower thrower = new ExceptionThrower();
try {
thrower.manyExceptions();
} catch (ExceptionA | ExceptionB ab) {
System.out.println(ab.getClass());
} catch (ExceptionC c) {
System.out.println(c.getClass());
}
}
請注意:如果
catch塊處理多個異常類型,則catch參數隱式為final類型,這意味着,您不能在catch塊中為其分配任何值。
數字格式增強
為了解決長數字可讀性不好的問題,在 Java 7 中支持了使用下划線分割的數字表達形式:
/**
* Supported in int
* */
int improvedInt = 10_00_000;
/**
* Supported in float
* */
float improvedFloat = 10_00_000f;
/**
* Supported in long
* */
float improvedLong = 10_00_000l;
/**
* Supported in double
* */
float improvedDouble = 10_00_000;
二進制字面量
在 Java 7 中,您可以使用整型類型 (byte、short、int、long) 並加上前綴 0b (或 0B) 來創建二進制字面量。這在 Java 7 之前,您只能使用八進制值 (前綴為 0) 或十六進制值 (前綴為 0x 或者 0X) 來創建:
int sameVarOne = 0b01010000101;
int sameVarTwo = 0B01_010_000_101;
byte byteVar = (byte) 0b01010000101;
short shortVar = (short) 0b01010000101
增強的文件系統
Java 7 推出了全新的NIO 2.0 API以此改變針對文件管理的不便,使得在java.nio.file包下使用Path、Paths、Files、WatchService、FileSystem等常用類型可以很好的簡化開發人員對文件管理的編碼工作。
1 - Path 接口 和 Paths 類
Path接口的某些功能其實可以和java.io包下的File類等價,當然這些功能僅限於只讀操作。在實際開發過程中,開發人員可以聯用Path接口和Paths類,從而獲取文件的一系列上下文信息。
int getNameCount(): 獲取當前文件節點數Path getFileName(): 獲取當前文件名稱Path getRoot(): 獲取當前文件根目錄Path getParent(): 獲取當前文件上級關聯目錄
聯用Path接口和Paths類型獲取文件信息:
Path path = Paths.get("G:/test/test.xml");
System.out.println("文件節點數:" + path.getNameCount());
System.out.println("文件名稱:" + path.getFileName());
System.out.println("文件根目錄:" + path.getRoot());
System.out.println("文件上級關聯目錄:" + path.getParent());
2 - Files 類
聯用Path接口和Paths類可以很方便的訪問到目標文件的上下文信息。當然這些操作全都是只讀的,如果開發人員想對文件進行其它非只讀操作,比如文件的創建、修改、刪除等操作,則可以使用Files類型進行操作。
Files類型常用方法如下:
Path createFile(): 在指定的目標目錄創建新文件void delete(): 刪除指定目標路徑的文件或文件夾Path copy(): 將指定目標路徑的文件拷貝到另一個文件中Path move(): 將指定目標路徑的文件轉移到其他路徑下,並刪除源文件
使用Files類型復制、粘貼文件示例:
Files.copy(Paths.get("/test/src.xml"), Paths.get("/test/target.xml"));
使用 Files 類型來管理文件,相對於傳統的 I/O 方式來說更加方便和簡單。因為具體的操作實現將全部移交給 NIO 2.0 API,開發人員則無需關注。
3 - WatchService
Java 7 還為開發人員提供了一套全新的文件系統功能,那就是文件監測。 在此或許有很多朋友並不知曉文件監測有何意義及目,那么請大家回想下調試成熱發布功能后的 Web 容器。當項目迭代后並重新部署時,開發人員無需對其進行手動重啟,因為 Web 容器一旦監測到文件發生改變后,便會自動去適應這些“變化”並重新進行內部裝載。Web 容器的熱發布功能同樣也是基於文件監測功能,所以不得不承認,文件監測功能的出現對於 Java 文件系統來說是具有重大意義的。
文件監測是基於事件驅動的,事件觸發是作為監測的先決條件。開發人員可以使用java.nio.file包下的StandardWatchEventKinds類型提供的3種字面常量來定義監測事件類型,值得注意的是監測事件需要和WatchService實例一起進行注冊。
StandardWatchEventKinds類型提供的監測事件:
ENTRY_CREATE:文件或文件夾新建事件;ENTRY_DELETE:文件或文件夾刪除事件;ENTRY_MODIFY:文件或文件夾粘貼事件;
使用WatchService類實現文件監控完整示例:
public static void testWatch() {
/* 監控目標路徑 */
Path path = Paths.get("G:/");
try {
/* 創建文件監控對象. */
WatchService watchService = FileSystems.getDefault().newWatchService();
/* 注冊文件監控的所有事件類型. */
path.register(watchService, StandardWatchEventKinds.ENTRY_CREATE, StandardWatchEventKinds.ENTRY_DELETE,
StandardWatchEventKinds.ENTRY_MODIFY);
/* 循環監測文件. */
while (true) {
WatchKey watchKey = watchService.take();
/* 迭代觸發事件的所有文件 */
for (WatchEvent<?> event : watchKey.pollEvents()) {
System.out.println(event.context().toString() + " 事件類型:" + event.kind());
}
if (!watchKey.reset()) {
return;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
通過上述程序示例我們可以看出,使用WatchService接口進行文件監控非常簡單和方便。首先我們需要定義好目標監控路徑,然后調用FileSystems類型的newWatchService()方法創建WatchService對象。接下來我們還需使用Path接口的register()方法注冊WatchService實例及監控事件。當這些基礎作業層全部准備好后,我們再編寫外圍實時監測循環。最后迭代WatchKey來獲取所有觸發監控事件的文件即可。
Fork/ Join 框架
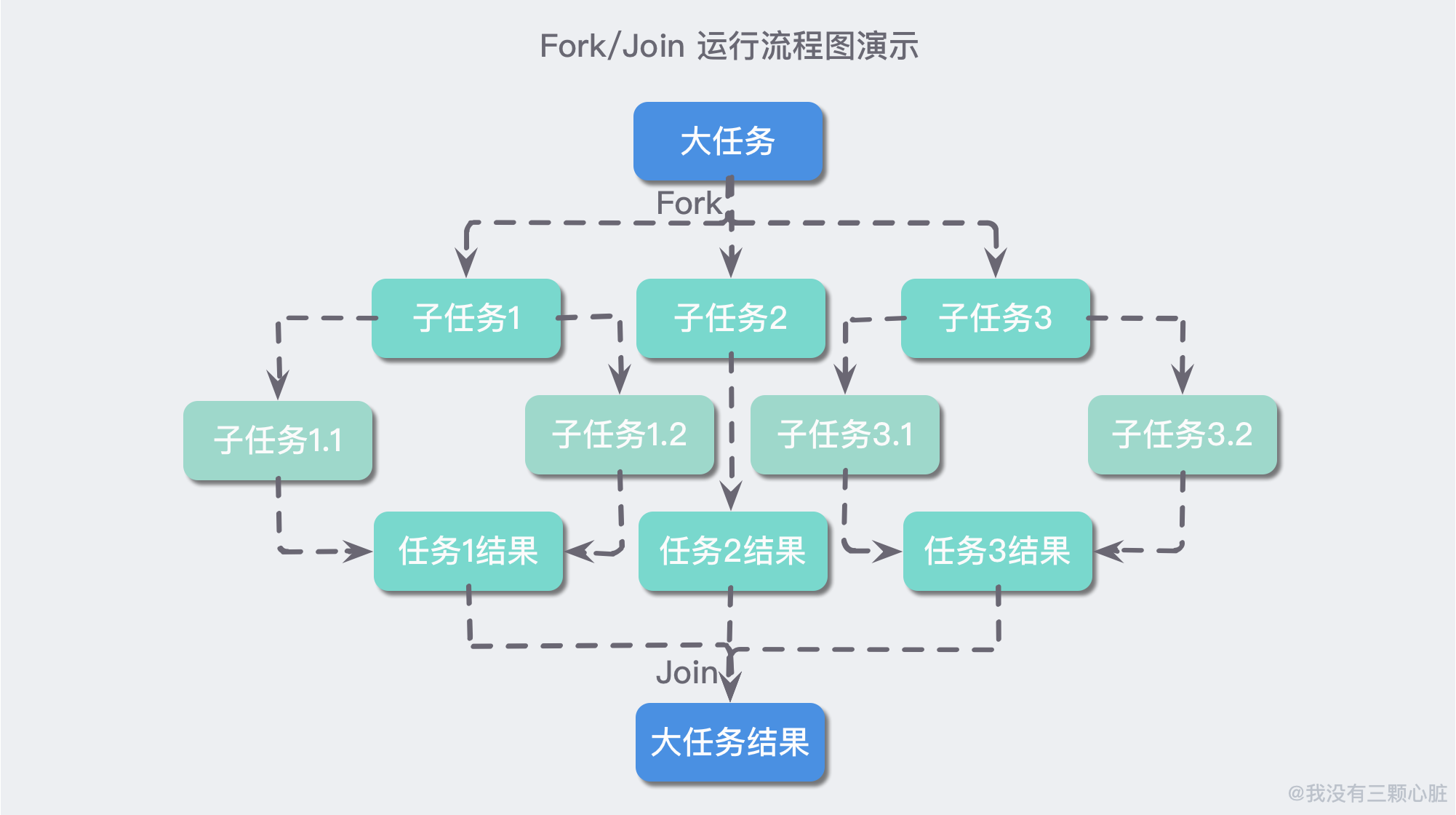
1 - 什么是 Fork/ Join 框架
Java 7 提供的一個用於並行執行任務的框架,是一個把大任務分割成若干個小任務,最終匯總每個小任務結果后得到大任務結果的框架。比如我們要計算 1 + 2 + .....+ 10000,就可以分割成 10 個子任務,讓每個子任務分別對 1000 個數進行運算,最終匯總這 10 個子任務的結果。
Fork/Join 的運行流程圖如下:
2 - 工作竊取算法
工作竊取 (work-stealing) 算法是指某個線程從其他隊列里竊取任務來執行。核心思想是:自己的活干完了去看看別人有沒有沒有干完的活兒,如果有就拿過來幫他干。
工作竊取的運行流程圖如下:
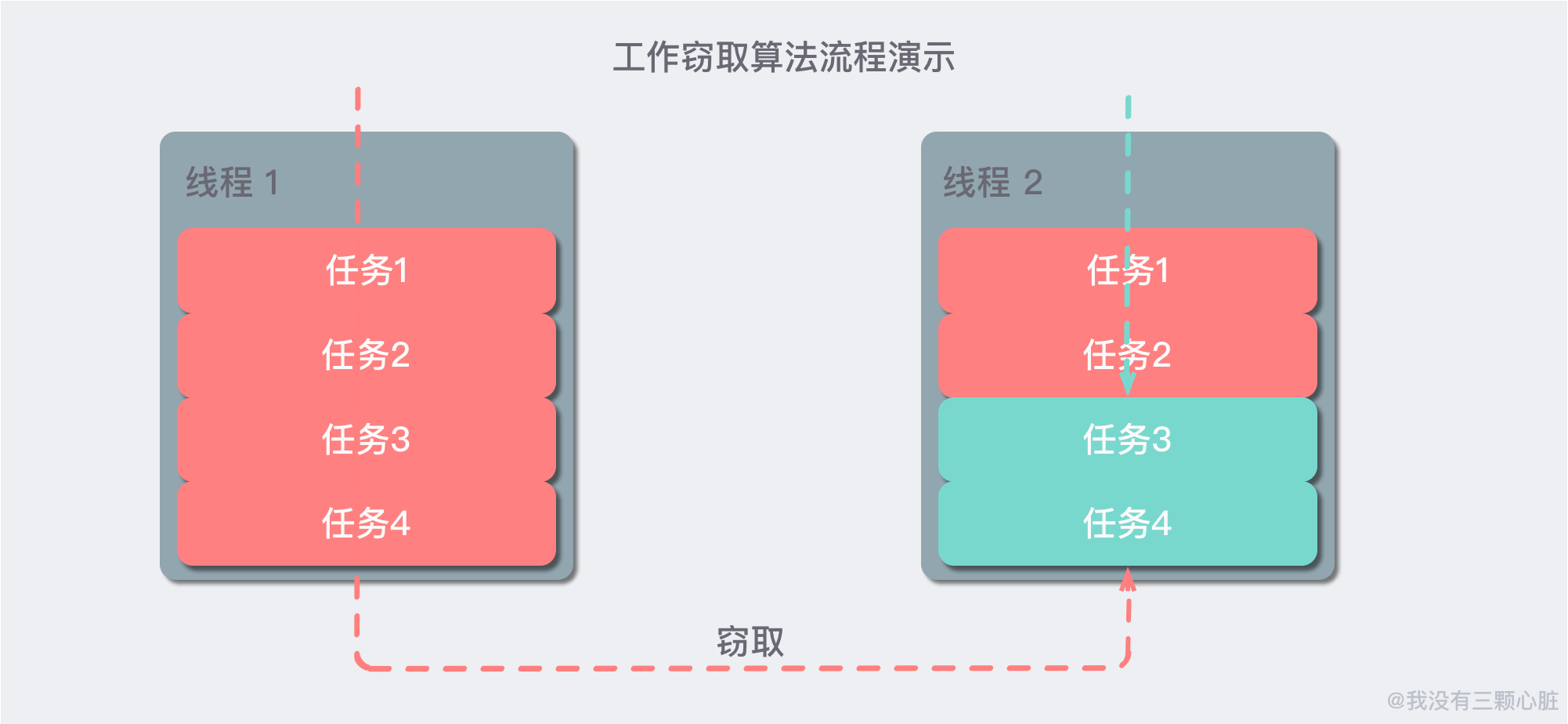
工作竊取算法的優點是充分利用線程進行並行計算,並減少了線程間的競爭,其缺點是在某些情況下還是存在競爭,比如雙端隊列里只有一個任務時。並且消耗了更多的系統資源,比如創建多個線程和多個雙端隊列。
3 - 簡單示例
讓我們通過一個簡單的需求來使用下Fork/Join框架,需求是:計算1 + 2 + 3 + 4的結果。
使用Fork/Join框架首先要考慮到的是如何分割任務,如果我們希望每個子任務最多執行兩個數的相加,那么我們設置分割的閾值是2,由於是4個數字相加,所以Fork/Join框架會把這個任務fork成兩個子任務,子任務一負責計算1 + 2,子任務二負責計算3 + 4,然后再join兩個子任務的結果。
因為是有結果的任務,所以必須繼承RecursiveTask,實現代碼如下:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* CountTask.
*
* @author blinkfox on 2018-01-03.
* @originalRef http://blinkfox.com/2018/11/12/hou-duan/java/java7-xin-te-xing-ji-shi-yong/#toc-heading-5
*/
public class CountTask extends RecursiveTask<Integer> {
/** 閾值. */
public static final int THRESHOLD = 2;
/** 計算的開始值. */
private int start;
/** 計算的結束值. */
private int end;
/**
* 構造方法.
*
* @param start 計算的開始值
* @param end 計算的結束值
*/
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
/**
* 執行計算的方法.
*
* @return int型結果
*/
@Override
protected Integer compute() {
int sum = 0;
// 如果任務足夠小就計算任務.
if ((end - start) <= THRESHOLD) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任務大於閾值,就分裂成兩個子任務來計算.
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 等待子任務執行完,並得到結果,再合並執行結果.
leftTask.fork();
rightTask.fork();
sum = leftTask.join() + rightTask.join();
}
return sum;
}
/**
* main方法.
*
* @param args 數組參數
*/
public static void main(String[] args) throws ExecutionException, InterruptedException {
ForkJoinPool fkPool = new ForkJoinPool();
CountTask task = new CountTask(1, 4);
Future<Integer> result = fkPool.submit(task);
System.out.println("result:" + result.get());
}
}
虛擬機增強
Oracle 官網介紹:https://docs.oracle.com/javase/7/docs/technotes/guides/vm/enhancements-7.html
1 - 提供新的 G1 收集器
Java 7 引入了一個被稱為 Garbage-First (G1) 的垃圾收集器。G1 是服務器式的垃圾收集器 (設計初衷是盡量縮短處理超大堆——大於 4GB——時產生的停頓),適用於具有大內存多處理器的計算機。
與之前收集器不同的是 G1 沒有使用 Java 7 之前連續的內存模型:

而是將整個 堆空間 划分為了多個大小相等的獨立區域 (Region),雖然還保留有新生代和老年代的概念,但新生代和老年代不再是物理隔閡了,它們都是一部分 (可以不連續) Region的集合:
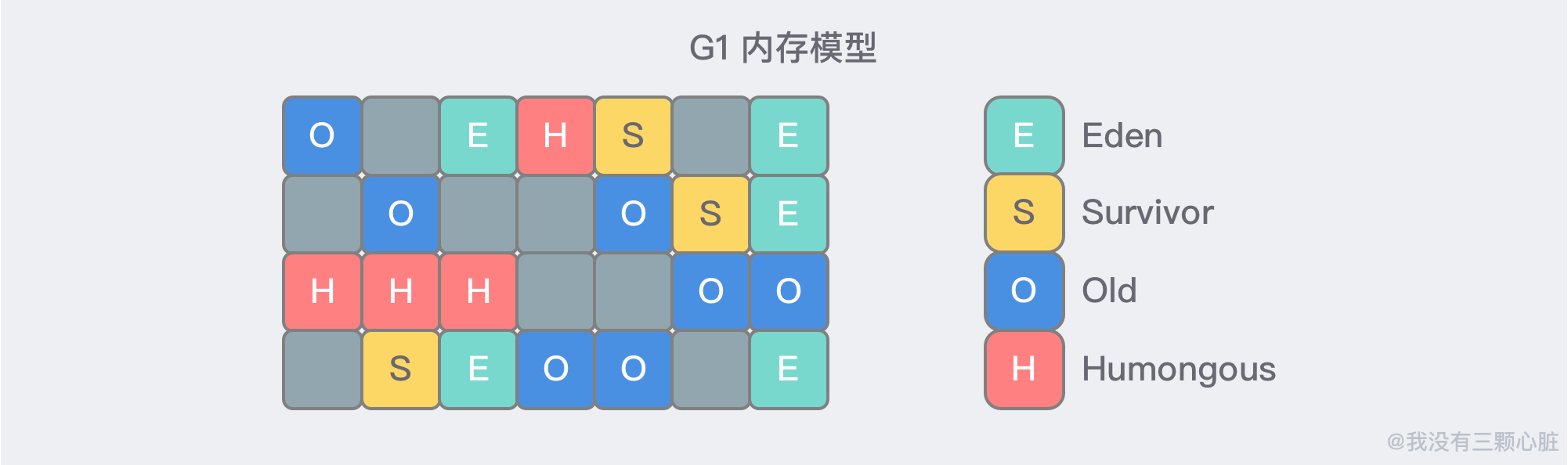
G1 完全可以預測停頓時間,並且可以為內存密集型應用程序提供更高的吞吐量。
⚠️ 對於 G1 和垃圾收集器不熟悉的同學趕緊來這里補課啦!!!
2 - 加強對動態調用的支持
Java 7 之前字節碼指令集中,四條方法調用指令 (invokevirtual、invokespeicial、invokestatic、invokeinterface) 的第一個參數都是 被調用方法的符號引用,但動態類型的語言只有在 運行期 才能確定接受的參數類型。這樣,在 Java 虛擬機上實現的動態類型語言就不得不使用“曲線救國”的方式 (如編譯時留個占位符類型,運行時動態生成字節碼實現具體類型到占位符類型的適配) 來實現,這樣勢必讓動態類型語言實現的復雜度增加,也可能帶來額外的性能或者內存開銷。
為了從 JVM 底層解決這個問題 (早在 1997 年出版的《Java 虛擬機規范》第一版中就規划了這樣一個願景:“在未來,我們會對 Java 虛擬機進行適當的擴展,以便更好的支持其他語言運行於 Java 虛擬機之上”), Java 7 新引入了 invokedynamic 指令以及 java.lang.invoke 包。
想進一步了解可以閱讀:
3 - 分層編譯
Java 7 中引入的 分層編譯 為服務器 VM 帶來了客戶端一般的啟動速度。通常,服務器 VM 使用 解釋器 來收集有關「提供給 編譯器 的方法」的分析信息。在分層模式中,除了 解釋器 之外,客戶端編譯器 還用於生成方法的編譯版本,這些方法收集關於自身的分析信息。由於編譯后的代碼比 解釋器 要快得多,程序在分析階段執行時會有更好的性能。在許多情況下,可以實現比客戶機 VM 更快的啟動,因為服務器編譯器生成的最終代碼可能在應用程序初始化的早期階段就已經可用了。分層模式還可以獲得比常規服務器 VM 更好的峰值性能,因為更快的分析階段允許更長的分析周期,這可能產生更好的優化。(ps: 官方文檔如是說...)
支持 32 位和 64 位模式,以及壓縮 Oops。在 java 命令中使用 -XX:+TieredCompilation 標志來啟用分層編譯。
(ps: 這在 Java 8 是默認開啟的)
4 - 壓縮 Oops (CompressOops)
HotSpot JVM 使用名為 oops 或 Ordinary Object Pointers 的數據結構來表示對象。這些 oops 等同於本地C指針。 instanceOops 是一種特殊的 oop,表示 Java 中的對象實例。
在 32 位的系統中,對象頭指針占 4 字節,只能引用 4 GB 的內存,在 64 位系統中,對象頭指針占 8 字節。更大的指針尺寸帶來了問題:
- 更容易 GC,因為占用空間更大了;
- 降低了 CPU 緩存命中率,因為一條
cache line中能存放的指針數變少了;
為了能夠保持 32 位的性能,oop 必須保留 32 位。那么,如何用 32 位 oop 來引用更大的堆內存呢?答案是——壓縮指針 (CompressedOops)。JVM 被設計為硬件友好,對象都是按照 8 字節對齊填充的,這意味着使用指針時的偏移量只會是 8 的倍數,而不會是下面中的 1-7,只會是 0 或者 8:
mem: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
^ ^
這就允許了我們不再保留所有的引用,而是每隔 8 個字節保存一個引用:
mem: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
^ ^
| ___________________________|
| |
heap: | 0 | 1 |
CompressedOops,可以讓跑在 64 位平台下的 JVM,不需要因為更寬的尋址,而付出 Heap 容量損失的代價 (其中還涉及零基壓縮優化——Zero-Based Compressed OOPs 技術)。 不過它的實現方式是在機器碼中植入壓縮與解壓指令,可能會給 JVM 增加額外的開銷。
想要了解更多戳這里:
- JVM 中的壓縮 OOP | Baeldung - https://www.baeldung.com/jvm-compressed-oops
- 官方文檔 - https://docs.oracle.com/javase/7/docs/technotes/guides/vm/performance-enhancements-7.html
其他優化
將 interned 字符串移出 perm gen
在 JDK 7 中,interned 字符串不再在 Java 堆的永久生成中分配,而是在 Java 堆的主要部分 (稱為年輕代和年老代) 中分配,與應用程序創建的其他對象一起分配。這一更改將導致駐留在主 Java 堆中的數據更多,而駐留在永久生成中的數據更少,因此可能需要調整堆大小。由於這一變化,大多數應用程序在堆使用方面只會看到相對較小的差異,但加載許多類或大量使用 String.intern() 方法的較大應用程序將看到更顯著的差異。
(ps: String.intern() 方法是運行期擴展方法區常量池的一種手段)
NUMA 收集器增強
Java 7 對 Parallel Scavenger 垃圾收集器進行了擴展,以利用具有 NUMA (非統一內存訪問) 體系結構的計算機的優勢。大多數現代計算機都基於 NUMA 架構,在這種架構中,訪問內存的不同部分需要花費不同的時間。通常,系統中的每個處理器都具有提供低訪問延遲和高帶寬的本地內存,以及訪問速度相當慢的遠程內存。
在 Java HotSpot 虛擬機中,已實現了 NUMA 感知的分配器,以利用此類系統並為 Java 應用程序提供自動內存放置優化。分配器控制堆的年輕代的 eden 空間,在其中創建大多數新對象。分配器將空間划分為多個區域,每個區域都放置在特定節點的內存中。分配器基於以下假設:分配對象的線程將最有可能使用該對象。為了確保最快地訪問新對象,分配器將其放置在分配線程本地的區域中。可以動態調整區域的大小,以反映在不同節點上運行的應用程序線程的分配率。這甚至可以提高單線程應用程序的性能。另外,年輕一代,老一代和永久一代的“從”和“到”幸存者空間為其打開了頁面交錯。這樣可以確保所有線程平均平均具有對這些空間的相等的訪問延遲。
版本號大於 50 的類文件必須使用 typechecker 進行驗證
從 Java 6 開始,Oracle 的編譯器使用 StackMapTable 制作類文件。基本思想是,編譯器可以顯式指定對象的類型,而不是讓運行時執行此操作。這樣可以在運行時提供極小的加速,以換取編譯期間的一些額外時間和已編譯的類文件 (前面提到的 StackMapTable) 中的某些復雜性。
作為一項實驗功能,Java 6 編譯器默認未啟用它。 如果不存在 StackMapTable,則運行時默認會驗證對象類型本身。
版本號為 51 的類文件 (也就是 Java 7 的類文件) 是使用類型檢查驗證程序專門驗證的,因此,方法在適當時必須具有 StackMapTable 屬性。對於版本 50 的類文件,如果文件中的堆棧映射丟失或不正確,則 HotSpot JVM 將故障轉移到類型推斷驗證程序。對於版本為 51 (JDK 7 默認版本) 的類文件,不會發生此故障轉移行為。
參考資料
- Oracle 官方文檔 - https://www.oracle.com/java/technologies/javase/jdk7-relnotes.html
- 閃爍之狐 - Java7新特性及使用 - http://blinkfox.com/2018/11/12/hou-duan/java/java7-xin-te-xing-ji-shi-yong/#toc-heading-5
- JVM - 指針壓縮 - https://chanjarster.github.io/post/jvm/oop-compress/
- 本文已收錄至我的 Github 程序員成長系列 【More Than Java】,學習,不止 Code,歡迎 star:https://github.com/wmyskxz/MoreThanJava
- 個人公眾號 :wmyskxz,個人獨立域名博客:wmyskxz.com,堅持原創輸出,下方掃碼關注,2020,與您共同成長!

非常感謝各位人才能 看到這里,如果覺得本篇文章寫得不錯,覺得 「我沒有三顆心臟」有點東西 的話,求點贊,求關注,求分享,求留言!
創作不易,各位的支持和認可,就是我創作的最大動力,我們下篇文章見!