Kuberntes 目前在實際業務部署時,有兩個流派:一派推崇小集群,一個或數個業務共享小集群,全公司有數百上千個小集群組成;另一派推崇大集群,每個AZ(可用區)一個或數個大集群,各個業務通過Namespace的方式進行隔離。
兩者各有優劣,但是從資源利用率提升和維護成本的角度,大集群的優勢更加突出。但同時大集群也帶來相當多的安全、可用性、性能的挑戰和維護管理成本。
本文屬於Kubernetes多租戶大集群實踐的一部分,用來解決多租戶場景下,如何實現傳統的物理隊列隔離。
物理隊列並不是一個通用的業界名詞,它來源於一種集群資源管理模型,該模型簡化下如下:
- 邏輯隊列(Logical Queue):邏輯隊列是虛擬資源分配的最小單元,將虛擬資源配額(Quota)配置在邏輯隊列上(如CPU 200 標准核、內存 800GB等)
- 邏輯隊列對應Kubernetes的Namespace概念。參考Resource Quotas
- 不同的邏輯隊列之間可以設置Qos優先級,實現優先級調度。參考Limit Priority Class consumption by default可以限制每個Namespace下Pod的優先級選擇
- 配額分兩種:Requests(提供保障的資源)和Limits(資源的最大限制),其中僅Requests才能算Quota,Limits 由管理員視情況選擇
- 物理隊列(Physical Queue):物理隊列對應底層物理機資源,同一台物理機僅能從屬於同一個物理隊列。物理隊列的資源總額就是其下物理機可提供的資源的總和。
- 物理隊列當前在Kubernetes下缺乏概念映射
- 邏輯隊列和物理隊列是多對多綁定的關系,即同一個邏輯隊列可以跨多個物理隊列。
- 邏輯隊列的配額總和 / 物理隊列的資源總和 = 全局超售比
- 租戶:租戶可以綁定多個邏輯隊列,對應關系僅影響往對應的Namespace中部署Pod的權限。
資源結構如圖所示:
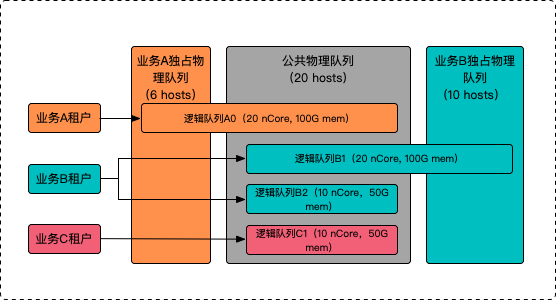
1、原理
物理隊列實現:
- 給節點配置Label和Taint,Label用於選擇,Taint用於拒絕非該物理隊列的Pod部署。
和Namespace的自動綁定的原理:
- 配置兩個
Admission Controller:PodNodeSelector和PodTolerationRestriction,參考Admission Controllers - 給
Namespace增加默認的NodeSelector和Tolerations策略,並自動應用到該 Namespace 下的全部新增 Pod 上,從而自動將Pod綁定到物理隊列上。
2、配置
2.1 集群開啟Admission Controller: PodNodeSelector,PodTolerationRestriction
我是在已經運行的k8s集群開啟PodNodeSelector,PodTolerationRestriction准入控制的,不能直接使用kubectl edit命令編輯kube-apiserver這個pod,直接加保存時報錯,需要修改修改 /etc/kubernetes/manifests/kube-apiserver.yaml配置文件
- --enable-admission-plugins=NodeRestriction,PodNodeSelector,PodTolerationRestriction
修改配置文件后立刻生效,之后查看kube-apiserver這個pod被重啟了,這樣就修改完成了。

2.2 創建 Namespace
apiVersion: v1
kind: Namespace
metadata:
name: public
annotations:
scheduler.alpha.kubernetes.io/node-selector: "node-restriction.kubernetes.io/physical_queue=public-phy"
scheduler.alpha.kubernetes.io/defaultTolerations: '[{"operator": "Equal", "effect": "NoSchedule", "key": "node-restriction.kubernetes.io/physical_queue", "value": "public-phy"}]'
# scheduler.alpha.kubernetes.io/tolerationsWhitelist: '[{"operator": "Equal", "effect": "NoSchedule", "key": "node-restriction.kubernetes.io/physical_queue", "value": "public-phy"}]'
此處要點:
- 文檔有問題,toleration 配置是一個list,配置錯誤在部署時會提示解析JSON錯誤
- tolerationsWhitelist配置后,就算配置有defaultTolerations且相同,也需要在Pod中指定對應的toleration,所以不能配置
- NoSchedule 已經足夠限制,無需 NoExecute,Node配置的時候同樣配置,此處可根據需求進行選擇。
- 物理隊列的前綴建議為
node-restriction.kubernetes.io/physical_queue,此處是根據文檔的建議,后續可以配合NodeRestriction admission plugin限制kubelet自定配置 - 目前Namespace尚不能綁定多個物理隊列:
- NodeSelector 無法支持in語法,見 4
- defaultTolerations 可以配置多個 Torleration
2.3 給Node綁定物理隊列
kubectl label node node7 node-restriction.kubernetes.io/physical_queue=public-phy kubectl taint nodes node7 node-restriction.kubernetes.io/physical_queue=public-phy:NoSchedule

3、測試
3.1 測試的Deployment如下
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
3.2 驗證提交到指定物理隊列中的Pod默認增加NodeSelector和Toleration
kubectl apply -f nginx_deployment.yaml --namespace public

kubectl describe pod nginx-deployment-574b87c764-khmd7 -n=public

3.3 驗證和物理隊列中指定的NodeSelector沖突的Pod無法提交
kubectl delete deployment nginx-deployment --namespace public
# 修改nginx_deployment.yaml ,增加spec.template.spec.nodeSelector
nodeSelector:
node-restriction.kubernetes.io/physical_queue: second-phy
# 驗證能否部署
kubectl apply -f nginx_deployment.yaml --namespace public
# 查看deployments
kubectl describe replicaset nginx-deployment-585fcd8d7d --namespace public
Warning FailedCreate 49s (x15 over 2m11s) replicaset-controller Error creating: pods is forbidden: pod node label selector conflicts with its namespace node label selector
4、相關問題
Q: NodeSelector無法使用Set-based語法,導致邏輯隊列(NameSpace)無法綁定多個物理隊列
后續考慮使用Node Affinity配置節點親和性。但是目前並沒有現成的Adminssion Controller去給Namespace綁定默認的節點親和性,如有需求需要自己開發。
NodeSelector 和 Toleration 的功能,可以被 Node Affinity 進行替代,且后者提供更高級的調度功能,后續嘗試是否基於此進行資源調度的整體設計。
此外Node Affinity還可以實現一個邏輯隊列綁定多個物理隊列的情況下,配置物理隊列的調度權重的功能,即優先部署到某個物理隊列。
參考:https://github.com/ninehills/ninehills.github.io/issues/77