- 《SystemVerilog驗證-測試平台編寫指南》學習 - 第2章 數據類型
《SystemVerilog驗證-測試平台編寫指南》學習 - 第2章 數據類型
SystemVerilog引進了一些新的數據類型,它們具有如下優點:
(1)雙狀態數據類型:更好的性能,更低的內存消耗;
(2)隊列、動態和關聯數組:減少內存消耗,自帶搜索和分類功能;
(3)類和結構:支持抽象數據結構;
(4)聯合和合並結構:允許對同一數據有多種視圖(view);
(5)字符串:支持內建的字符序列;
(6)枚舉類型:方便代碼編寫,增加可讀性;
2.1 內建數據類型
logic類型不能有多個結構性的驅動,在雙向總線建模的時候要使用線網類型。
logic類型只能有一個驅動,否則編譯報錯,所以logic可以用來查找頂層多驅動的錯誤。
雙狀態數據類型
最簡單的雙狀態數據類型是bit,它是無符號的。另外4種帶有符號的雙狀態數據類型是byte、shortint、int和longint,如下所示:
bit b ; // 雙狀態,單比特無符號
bit [31:0] b32 ; // 雙狀態,32比特無符號整數
int unsigned ui ; // 雙狀態,32比特無符號整數
int i ; // 雙狀態,32比特有符號整數
byte b8 ; // 雙狀態,8 比特有符號整數
shortint s ; // 雙狀態,16比特有符號整數
longint l ; // 雙狀態,64比特有符號整數
integer i4 ; // 四狀態,32比特有符號整數
time t ; // 四狀態,64比特無符號整數
real r ; // 雙狀態,雙精度浮點數
記:integer和time是四狀態數據類型,integer是32位有符號,time是64位無符號。
注:
你可能會樂意用byte數據類型代替logic[7:0]的聲明,以使得程序更加簡潔。但是需要注意的是這些新的數據類型是帶符號的,所以byte變量的最大值只有127(取值范圍-128 ~ 127)。可以使用byte unsigned,但這其實比使用bit[7:0]還要麻煩。在進行隨機化時,帶符號變量可能會造成意想不到的結果。
若把雙狀態變量連接到待測設計,務必小心,如果待測設計產生了X或者Z,這些值會被轉換為雙狀態值,而測試代碼可能永遠也察覺不了。這些值被轉換為了0還是1並不重要,重要的是要隨時檢查未知值的傳播。使用 $isunknown 操作符,可以在表達式的任意位出現X或者Z時返回1,如下例所示:
if ($isunknown(iport) == 1)
$display("@%0t: 4-state value detected on iport %b", $time, iport);
2.2 定寬數組
2.2.1 聲明
SystemVerilog允許只給出數組寬度的便捷聲明方式,和C語言類似。
可以通過在變量名后面指定維度的方式來創建多維數組。緊湊型聲明方式是SystemVerilog特有的。
int lo_hi [0:15] ; // 16個整數[0]...[15]
int c_style [16] ; // 便捷聲明,16個整數[0]...[15]
int array2 [0:7][0:3] ; // 完整的聲明
int array3 [8][4] ; // 緊湊的聲明
array2[7][3] = 1 ; // 設置最后一個元素為1
若代碼中試圖從一個越界的地址中讀取數據,那么SystemVerilog將返回數組元素的缺省值。比如,四狀態logic返回X,雙狀態int或bit則返回0。這適用於所有數組類型,包括定寬數組、動態數組、關聯數組和隊列,也同時適用於地址中包含有X和Z的情況。線網在沒有驅動時輸出是Z。
對於非壓縮數組(非合並數組),很多SystemVerilog仿真器存放數組元素時使用32bit的字符邊界,所以byte、shortint和int都是存放在相同長度的一個字中,而longint則存放到兩個字中。例如:
bit [7:0] b_unpack [3] ; // 定義3個8位的非壓縮數組

注:非壓縮數組(非合並數組) 占用更多的內存空間。
2.2.2 常量數組
使用:一個單引號加大括號來初始化數組。
可以部分賦值;可以重復次數賦值;可以為那些沒有顯式賦值的元素指定一個缺省值。如下所示:
int ascend [4] = '{0, 1, 2, 3} ; // 對4個元素進行初始化
int descend [5] ;
descend = '{4, 3, 2, 1, 0} ; // 為5個元素賦值
descend [0:2] = '{5, 6, 7} ; // 為前3個元素賦值
ascend = '{4{8}} ; // 4個值全部為8
descend = '{9, 8, default:1} ; // {9, 8, 1, 1, 1}
2.2.3 基本的數組操作 -- for和foreach
操作數組最常見的方式是使用 for 或者 foreach 循環。
$size函數返回數組的寬度。
在 foreach 循環中,只需要指定數組名並在后面的方括號中給出索引變量,SystemVerilog便會自動遍歷數組中的元素,索引變量將自動聲明,並只在循環內有效。
// 在數組操作中使用 for 和 foreach 循環
initial begin
bit [31:0] src [5] ; // 聲明5個32位整數
bit [31:0] dst [5] ; // 聲明5個32位整數
//bit [31:0] src[5], dst[5] ;
for (int i = 0; i < $size(src); i++)
src[i] = i ;
foreach (dst[j])
dst[j] = src[j] * 2 ; // dst的值是srcd的2倍
end
// 初始化並遍歷多維數組
int md[2][3] = '{'{0, 1, 2}, '{3, 4, 5}} ; // 定義常量數組
initial begin
$display ("Initial Value:") ;
foreach (md[i, j]) // 正確語法格式
$display ("md[%0d][%0d]=%0d", i, j, md[i][j]) ;
$display ("New Value:") ;
// 對最后3個元素重復賦值5
md = '{'{9, 8, 7}, '{3{32'd5}}} ;
foreach (md[i, j]) // 正確語法格式
$display ("md[%0d][%0d]=%0d", i, j, md[i][j]) ;
end
打印結果:
Initial Value:
md[0][0]=0
md[0][1]=1
md[0][2]=2
md[1][0]=3
md[1][1]=4
md[1][2]=5
New Value:
md[0][0]=9
md[0][1]=8
md[0][2]=7
md[1][0]=5
md[1][1]=5
md[1][2]=5
注意:foreach 的使用。
如果不需要遍歷數組中的所有維度,可以在 foreach 循環里忽略掉它們。看下面的例子,把一個二維數組打印成一個方形的陣列。它在外層循環遍歷一個維度,然后在內層循環遍歷第二個維度。
// 打印一個多維數組
initial begin
byte twoD [4][6] ; //
foreach (twoD[i, j])
twoD [i][j] = i * 10 + j ; //賦初值
foreach (twoD[i]) begin
$write ("%2d: ", i) ;
foreach (twoD[, j])
$write ("%3d", twoD[i][j]) ;
$display ;
end
end
打印結果如下:
0: 0 1 2 3 4 5
1: 10 11 12 13 14 15
2: 20 21 22 23 24 25
3: 30 31 32 33 34 35
補充:foreach 循環會遍歷原始聲明中的數組范圍。如,
數組 f[5]等同於f[0:4],而 foreach (f[i]) 等同於 for (int i = 0; i <= 4; i++)。
數組 rev[6:2]來說,foreach (rev[i]) 等同於 for (int i=6; i >= 2; i--)。
2.2.4 基本的數組操作 -- 復制和比較
你可以在不使用循環的情況下對數組進行聚合比較和復制(聚合操作適用於整個數組而不是單個元素),其中比較只限於等於或不等於比較。
// 數組的復制和比較操作
initial begin
bit [31:0] src [5] = '{0, 1, 2, 3, 4} ,
dst [5] = '{5, 4, 3, 2, 1} ;
// 兩個數組的聚合比較
if (src == dst)
$display ("src == dst") ;
else
$display ("src != dst") ;
// 把 src 所有元素復制給 dst
dst = src ;
// 只改變一個元素的值
src[0] = 5 ;
// 所有元素的值是否相等(否!)
$display("src %s dst", (src == dst) ? "==" : "!=") ;
// 使用數組片段對第 1-4 個元素進行比較
$display ("src[1:4] %s dst[1:4]", (src[1:4] == dst[1:4]) ? "==" : "!=") ;
end
對數組的算術運算不能使用聚合操作,而應該使用循環;
對於邏輯運算只能使用循環;
2.2.6 合並數組(壓縮數組)
聲明合並數組時,合並的位和數組大小作為數據類型的一部分必須在變量名前面指定。數組大小定義的格式必須是 [msb:lsb] ,而不是 [size]
// 合並數組的聲明和用法
bit [3:0] [7:0] bytes ; // 4個字節組裝成32bit
bytes = 32'hCafe_Dada ;
$displayh (bytes, // 顯示所有的 32bit
bytes[3], // 最高字節 “Ca"
bytes[3][7]); // 最高bit位 “1”

合並和非合並數組可以混合使用。你可能會使用數組來表示存儲單元,這些單元可以按 比特、字節、長字節 的方式進行存取。
// 合並/非合並混合數組的聲明
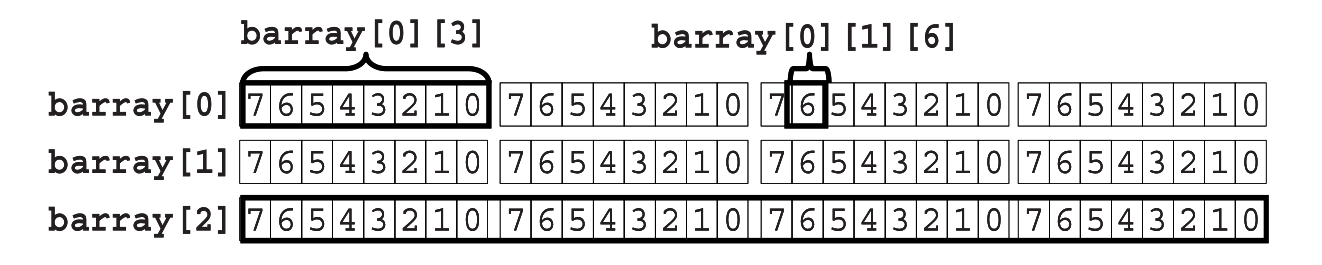
bit [3:0] [7:0] barray [3] ; // 合並:3x32 bit
bit [31:0] lw = 32'h0123_4567 ; // 字
bit [7:0] [3:0] nibbles ; // 合並數組
barray[0] = lw ;
barray[0][3] = 8'h01 ;
barray[0][1][6] = 1'b1 ;
nibbles = barray[0] ; // 復制合並數組的元素值
2.2.8 合並數組和非合並數組的選擇
-
當需要和標量進行相互轉換時,使用合並數組會較方便;
比如你需要以字節或字為單位進行操作,上例 barray 可滿足要求。 -
任何數組類型都可以合並,包括動態數組、隊列和關聯數組;
-
需要等待數組中的變化,則必須使用合並數組;
當測試平台需要通過存儲器的變化來喚醒時,你會想到使用@操作符,但是這個操作符只能用於標量或者合並數組。在上例中,lw 和 barray[0] 可以用做敏感信號,但是整個 barray 不行,除非擴展: @(barray[0] or barray[1] or barray[2])。
2.3 動態數組
SystemVerilog提供了動態數組類型,可以在仿真時分配或調整寬度,這樣在仿真中就可以使用最小的存儲量。
動態數組在聲明時使用空的下標 [] 。數組在最開始的時候是空的,所以你必須調用 new[] 操作符來分配空間,同時在方括號中傳遞數組寬度。可以吧數組名傳遞給 new[] 構造符,並把已有數組值賦值到新數組里。
// 使用動態數組
int dyn[], d2[] ; // 聲明動態數組
initial begin
dyn = new[5] ; // A: 分配5個元素
foreach (dyn[j])
dyn[j] = j; // B: 對元素進行初始化
d2 = dyn ; // C: 復制一個動態數組
d2[0] = 5 ; // D: 修改復制值
$display (dyn[0], d2[0]) ; // E: 顯示數值(0和5)
dyn = new[20](dyn) ; // F: 分配20個整數值並進行復制
dyn = new[100] ; // G: 分配100個新的整數值,舊值不復存在
dyn.delete() ; // H: 刪除所有元素,刪除 dyn 數組
end
// 使用動態數組來保存元素數量不定的列表
bit [7:0] mask [] = '{8'b0000_0000, 8'b0000_0001,
8'b0000_0011, 8'b0000_0111,
8'b0000_1111, 8'b0001_1111,
8'b0011_1111, 8'b0111_1111,
8'b1111_1111
} ;
只要基本數據類型相同,定寬數組和動態數組之間就尅相互賦值,在元素數目相同的情況下,可以把動態數組的值復制到定寬數組。
2.4 隊列
隊列,結合了鏈表和數組的優點。
隊列和鏈表相似,可以在一個隊列中的任何地方增加或刪除元素,這類操作在性能上的損失比動態數組小的多,因為動態數組需要分配新的數組並復制所有元素的值。
隊列與數組相似,可以通過索引實現對任一元素的訪問,而不需要像鏈表那樣去遍歷目標元素之前的所有元素。
隊列的聲明使用帶美元符號的下標:[$]。隊列元素的編號從0到$。 使用方法(method)在隊列中增加和刪除元素。
注意隊列的常量(literal)賦值是沒有單引號的大括號。不要對隊列使用構造函數 new[]。
// 隊列的操作
int j = 1 ,
q2[$] = {3, 4} , // 隊列的常量不需要使用“'”
q[$] = {0, 2, 5} ; // {0, 2, 5}
initial begin
q.insert (1, j) ; // {0, 1, 2, 5} 在2之前插入1
q.insert (3, q2) ; // {0, 1, 2, 3, 4, 5}在q中插入一個隊列
q.delete (1) ; // {0, 2, 3, 4, 5} 刪除第1個元素
// 下面的操作執行速度很快
q.push_front (6) ; // {6, 0, 2, 3, 4, 5}在隊列前插入
j = q.pop_back ; // {6, 0, 2, 3, 4} j = 5
q.push_back (8) ; // {6, 0, 2, 3, 4, 8}在隊列尾插入
j = q.pop_front ; // {0, 2, 3, 4, 8} j = 6
foreach (q[i])
$display (q[i]) ; // 打印整個隊列
q.delete () ; // {} 刪除整個隊列
end
可以使用下標字符串來替代方法。如果把 $ 放到一個范圍表達式的左邊,那么 $ 將代表最小值,如 [$:2] 代表 [0:2]。如果把 $ 放到一個表達式的右邊,那么 $ 將代表最大值,如 [1:$] 代表 [0:max_num]。
// 隊列操作
int j = 1 ,
q2[$] = {3, 4} ,
q[$] = {0, 2, 5} ; // {0, 2, 5}
initial begin
q = {q[0], j, q[1:$]} ; // {0, 1, 2, 5} 在2之前插入1
q = {q[0:2], q2, q[3:$]} ; // {0, 1, 2, 3, 4, 5} 在q中傳入一個隊列
q = {q[0], q[2:$]} ; // {0, 2, 3, 4, 5} 刪除第1個元素
// 下面的操作執行速度很快
q = {6, q} ; // {6, 0, 2, 3, 4, 5} 在隊列前面插入
j = q[$] ; // j = 5
q = q[0:$-1] ; // {6, 0, 2, 3, 4} 在隊列末尾取走數據
q = {q, 8} ; // {6, 0, 2, 3, 4, 8} 在隊列末尾插入
j = q[0] ; // j = 6
q = q[1:$] ; // {0, 2, 3, 4, 8} 從隊列前面取走數據
q = {} ; // {} 刪除整個隊列
end
隊列中元素是連續存放的,所以在隊列的前面或后面存取整數非常方便,無論隊列有多大,這種操作所消耗的時間是一樣的。
在隊列中間增加或刪除元素需要對已經存在的數據進行搬移以便騰出空間,相應操作所消耗的時間會隨着隊列的大小線性增加。
2.5 關聯數組
如果你需要超大容量的數據存放,假設你正在對一個有着幾個G字節尋址范圍的處理器進行建模。在典型的測試中,這個處理器可能只訪問了用來存放可執行代碼和數據的幾百或幾千個字節,這種情況下對幾個G字節的存儲空間進行分配和初始化顯然是浪費的。
關聯數組類型可以用來保存稀疏矩陣元素。這意味着當你對一個非常大的地址空間進行尋址時,SystemVerilog只為實際寫入的元素分配空間。如下圖所示,關聯數組只保留0...3、42、1000、4521和200000等位置上的值。

仿真器可以采用樹或哈希表的形式存放關聯數組,但有一定的額外開銷。
關聯數組采用在方括號中放置數據類型的形式進行聲明。
// 關聯數組的聲明、初始化和使用
initial begin
bit [63:0] assoc[bit [63:0]] , // 關聯數組聲明
idx = 1 ;
// 對稀疏分布的元素進行初始化
repeat (64) begin
assoc[idx] = idx ;
idx = idx << 1 ;
end
// 使用 foreach 遍歷數組
foreach (assoc[i])
$display ("assoc[%h] = %h", i, assoc[i]) ;
//使用函數遍歷數組
if (assoc.first (idx)) begin
do // 得到第一個索引
$display ("assoc[%h] = %h", idx, assoc[idx]) ;
while (assoc.next (idx)) ; // 得到下一個索引
end
// 找到並刪除第一個元素
assoc.first (idx) ;
assoc.delete (idx) ;
$display ("The array now has %0d elements", assoc.num) ;
end
對於關聯數組,簡單的for循環並不能遍歷數組,需要使用 foreach 循環遍歷數組。如果你想控制的更好,可以在 do...while 循環中使用 first 和 next 函數。這些函數可以修改索引參數的值,然后根據數組是否為空返回 0 或 1。
關聯數組也可以使用字符串索引進行尋址。下例使用字符串索引讀取文件,並建立關聯數組switch,以實現從字符串到數字的映射。可以使用函數 exists() 來檢查元素是否存在。
// 使用帶字符串索引的關聯數組
/*
輸入文件的內容如下:
42 min_address
1492 max_address
*/
int switch [string],
min_address ,
max_address ;
initial begin
int i, r, file ;
string s ;
file = $open("switch.txt", "r") ;
while (! $feof (file)) begin // 當讀到文件末尾時 $feof (<文件句柄>) != 0 ,否則為0
r = $fscanf (file, "%d %s", i, s) ; // $fscanf 一行一行讀取數據
switch [s] = i ;
end
$fclose (file) ;
// 獲取最小地址值,缺省為0
min_address = switch ["min_address"] ;
// 獲取最大地址值,缺省為1000
if (switchl.exists ("max_address"))
max_address = switch["max_address"] ;
else
max_address = 1000 ;
// 打印數組的所有元素
foreach (switch[s])
$display ("switch['%s'] = %0d", s, switch[s]) ;
end
2.7 數組的方法
SystemVerilog提供了很多數組的方法,可用於任何一個非合並的數組類型,包括定寬數組、動態數組、隊列和關聯數組。如果不帶參數,則方法中的圓括號可以省略。
2.7.1 數組的縮減方法
基本的數組縮減方法是把一個數組縮減成一個值。
// 數組求和
bit on[10] ; // 單比特數組
int total ;
initial begin
foreach (on[i])
on[i] = i ; // 注意, on[i] 的值為 0/1
// 打印出單比特和
$display ("on.sum = %0d", on.sum) ; // on.sum = 1
// 打印出32比特和
$display ("on.sum = %0d", on.sum + 32'd0) ; // on.sum = 5
// 由於total是32比特變量,所以數組和也是32比特
total = on.sum ;
$display ("total = %0d", total) ; // total = 5
// 將數組和與一個32比特數進行比較
if (on.sum >= 32'd5) // 條件成立
$display ("sum has 5 or more 1's") ;
// 使用帶32比特有符號運算的with表達式
$display ("int sum = %0d", on.sum with (int '(item))) ;
end
其它數組縮減方法還有 product(積),and(與),or(或),xor(異或)。
SystemVerilog沒有提供專門從數組里隨機選取一個元素的方法。所以對於定寬數組、隊列、動態數組和關聯數組可以使用 $urandom_range ($size (array) - 1) ,而對於隊列和動態數組還可以使用 $urandom_range (array, size () - 1)。
如果想從一個關聯數組中隨機選取一個元素,你需要逐個訪問它之前的元素,原因是沒有辦法能夠直接訪問到第 N 個元素。
int aa [int] ,
rand_idx ,
element ,
count ;
element = $urandom_range (aa, size () - 1) ;
foreach (aa[i])
if (count++ == element) begin
rand_idx = i ; // 保存關聯數組的索引
break ; // 並退出
end
$display ("%0d element aa[%0d] = %0d", element, rand_idx, aa[rand_idx]) ;
2.7.2 數組的定位方法
查找數組最大值、特定值,在非合並(非壓縮)數組中可以使用數組定位方法,這些方法的返回值通常是一個隊列。
方法 作用 max() 找出數組中的最大值 min() 找出數組中的最小值 unique() 返回數組中具有唯一值的隊列(即去重) find 可結合with使用 find_index 可結合with使用,找出索引值 find_first 可結合with使用,找出第一個匹配值 find_first_index 可結合with使用,找出第一個匹配的索引 find_last 可結合with使用,找出最后一個匹配值 find_last_index 可結合with使用,找出最后一個匹配的索引 sum 求出滿足條件的和,即條件表達式為真的次數
// 數組定位方法:min、max、unique
int f [6] = '{1, 6, 2, 6, 8, 6} ;
int d [] = '{2, 4, 6, 8, 10} ;
int q [$] = {1, 3, 5, 7}, tq[$] ;
tq = q.min() ; // {1}
tq = d.max() ; // {10}
tq = f.unique() ; // {1, 6, 2, 8}
使用 foreach 循環固然可以實現數組的完全搜索,但如果使用SystemVerilog的定位方法,則只需要一個操作便可以完成。表達式with可以指示SystemVerilog如何進行搜索。
// 數組定位方法:find
int d [] = '{9, 1, 8, 3, 4, 4} ,
tq [$] ;
// 找出所有大於3的元素
tq = d.find with (item > 3) ; // {9, 8, 4, 4}
// 等效代碼
tq.delete() ;
foreach (d[i])
if (d[i] > 3)
tq.push_back (d[i]) ;
tq = d.find_index with (item > 3) ; // {0, 2, 4, 5}
tq = d.find_first with (item > 99) ; // {} 沒有找到
tq = d.find_first_index with (item == 8) ; // {2} d[2]=8
tq = d.find_last with (item == 4) ; // {4}
tq = d.find_last_index with (item == 4) ; // {5} d[5]=4
在條件語句with中,item被稱為重復參數,它代表了數組中一個單獨元素。item是缺省的名字,也可以指定其他名稱,只要在數組方法的參數列表中列出來就可以了。
// 重復參數的聲明
tq = d.find_first with (item == 4) ; // 本例4個語句等價
tq = d.find_first () with (item == 4) ;
tq = d.find_first (item) with (item == 4) ;
tq = d.find_first (x) with (x == 4) ;
// 數組定位方法
int count,
total,
d[] = '{9, 1, 8, 3, 4, 4} ;
// 第一次求和(total)是先把元素值和7進行比較,比較表達式返回1(為真)或0(為假),然后再把返回結果與對應元素相乘
count = d.sum with (item > 7) ; // 2: {9, 8}
total = d.sum with ((item > 7) * item) ; // 17=9+8
count = d.sum with (item < 8) ; // 4: {1, 3, 4, 4}
total = d.sum with (item < 8 ? item : 0) ; // 12=1+3+4+4
count = d.sum with (item == 4) ; // 2: {4, 4}
當吧數組縮減方法與條件語句with結合使用時,sum操作符的結果是條件表達式位真的次數。
返回值為索引的數組定位方法,其返回的隊列類型是int而非integer,例如 find_index 方法。
2.7.3 數組的排序
數組的定位方法是新建一個隊列來保存返回值,而數組的排序方法則改變了原始數據。
// 對數組排序
int d [] = '{9, 1, 8, 3, 4, 4} ;
d.reverse () ; // '{4, 4, 3, 8, 1, 9}
d.sort () ; // '{1, 3, 4, 4, 8, 9}
d.rsort () ; // '{9, 8, 4, 4, 3, 1}
d.shuffle () ; // '{9, 4, 3, 8, 1, 4}
注意:reverse 和 shuffle 方法不能帶 with 條件語句,所以它們的作用范圍是整個數組。
下例示范了如何使用子域對一個結構進行排序:
// 對數組結構進行排序
struct packed {byte red, green, blue;} c[] ;
initial begin
c = new [100] ; // 分配100個像素
foreach (c[i])
c[i] = $urandom ; // 填上隨機數
c.sort with (item, red) ; // 只對紅色像素進行排序
// 先對綠色像素后對藍色像素進行排序
c.sort (x) with ({x.green, x.blue}) ;
end
2.7.4 使用數組定位方法建立計分板
數組定位方法可以用來建立計分板。下例定義了一個包結構(Packet),然后建立了一個由包結構隊列組成的計分板。
下例中的 check_addr () 函數在計分板里尋找和參數匹配的地址。find_index () 方法返回一個 int 隊列。如果該隊列為空 (size == 0),則說明沒有匹配。如果該隊列有一個成員 (size == 1),則說明有一個匹配,該匹配隨后被刪除。如果該隊列有多個成員 (size > 1),則說明計分板里有多個包地址和目標匹配。
對於包信息的存儲,更好的方式是采用類。
// 帶數組方法的計分板
typedef struct packed
{bit [7:0] addr ;
bit [7:0] pr ;
bit [15:0] data; } Packet ;
Packet scb [$] ;
function void check_addr (bit [7:0] addr) ;
int intq [$] ;
intq = scb.find_index () with (item.addr == addr) ;
case (intq.size())
0: $display ("Addr %h not found in scoreboard", addr) ;
1: scb.delete (intq[0]) ;
default: $display ("Error: Multiple hits for addr %h", addr) ;
endcase
endfunction : check_addr
2.8 選擇存儲類型
介紹基於靈活性、存儲用量、速度和排序要求正確選擇存儲類型的一些准則。這些准則只是一些經驗法則,其結果可能隨仿真器的不同而不同。
2.8.1 靈活性
如果數組的索引是連續的非負整數,則應使用定寬數組或動態數組。當數組的寬度在編譯時已經確定則選擇定寬數組,如果要等到程序運行時才知道數組寬度則選擇動態數組。
例如長度可變的的數據包使用動態數組存儲會很方便。
當你編寫處理數組的子程序時,最好使用動態數組,因為只要在元素類型(如int、string)匹配的情況下,同一個子程序可以處理不同寬度的數組。同樣地,只要元素類型匹配,任意長度的隊列都可以傳遞給子程序。關聯數組也可以作為參數傳遞,而不需要考慮數組寬度的問題。相比之下,帶定寬數組參數的子程序則只能接受指定寬度的數組。
對於那些在仿真過程中元素數目變化很大的數組,例如保存預期值的計分板,隊列是一個很好的選擇。
2.8.2 存儲器用量
使用雙狀態類型可以減少仿真時的存儲用量。為了避免浪費空間,應盡量選擇32bit的整數倍作為數據位寬。仿真器通常會把位寬小於32bit的數據存放到32bit的字里。使用合並數組有助於節省存儲空間。
因為需要額外的指針,隊列的存取效率比定寬數組或動態數組稍差。但是,如果你把一個長度經常變化的數據集存放到動態數組里,那么你需要手工調用 new[] 來分配和復制內存。這個操作的代價會很高,可能會抵消動態數組所帶來的全部好處。
對兆字節量級的存儲器建模應該使用關聯數組。注意,因為指針帶來的額外開銷,關聯數組里每個元素所占用的空間可能會比定寬數組或動態數組占用的空間大好幾倍。
2.8.3 速度
因為定寬數組和動態數組都是被存放在連續的存儲空間里,所以訪問其中的任何元素耗時都相同,而與數組的大小無關。
隊列的讀寫速度與定寬或動態數組基本相當。隊列的首位元素的存取幾乎沒有任何開銷,而在隊列中間插入或刪除元素則需要對很多其他元素進行搬移以便騰出空間。當你需要在一個很長的隊列里插入新元素是,你的測試程序可能會變得很慢,這時最好考慮改變新元素的存儲方式。
對關聯數組進行讀寫時,仿真器必須在存儲器里進行搜索。所以關聯數組的存取速度是最慢的。
2.8.5 選擇最優的數據結構
以下是針對數據結構選擇的一些建議:
- 網絡數據包。特點:長度固定,順序存取。針對長度固定或可變的數據包可分別采用定寬數組或動態數組。
- 保存期望值的計分板。特點:仿真前長度未知,按值存取,長度經常變化。一般情況下可使用隊列,這樣方便在仿真期間連續增加和刪除元素。
- 有序結構。如果數據按照可預見的順序輸出,那么可以使用隊列;如果輸出順序不確定,則使用關聯數組。如果不用對計分板進行搜索,那么只需要把預期的數值存入信箱(mailbox)。
- 對超過百萬個條目的特大容量存儲器進行建模。如果你不需要用到所有的存儲空間,可以使用關聯數組實現稀疏存儲。
2.9 使用 typedef 創建新的類型
typedef 語句可以用來創建新的類型。
// Verilog 中用戶自定義的類型宏,只進行文本替換
// 老的Verilog風格
`define OPSIZE 8
`define OPREG reg [`OPSIZE-1:0]
`OPREG op_a, op_b ;
// SystemVerilog中用戶自定義類型
// 新的SystemVerilog風格
parameter OPSIZE = 8 ;
typedef reg [OPSIZE-1:0] opreg_t ;
opreg_t op_a, op_b ;
一般來說,即時數據位寬不匹配,SystemVerilog都允許在這些基本類型之間進行賦值而不會給出警告。
用戶自定義的最有用的類型是雙狀態的32bit無符號整型。如下例定義:
// uint 的定義
typedef bit [31:0] uint ; // 32bit雙狀態無符號數
typedef int unsigned uint ; // 32bit雙狀態無符號數,和上面的等效
2.10 創建用戶自定義結構
Verilog最大的缺陷之一就是沒有數據結構。在SystemVerilog中可以使用struct語句創建結構,跟C語言類似。但是struct功能比類少,所以還不如直接在測試平台使用類。類里面包含數據和程序,以便於重用,struct只是把數據組織到一起,所以只解決了一半問題。
由於struct只是一個數據的集合,所以它是可綜合的。
2.10.1 使用struct創建新類型
下例中創建了一個名為pixel的結構,它有3個無符號的字節變量,分別代表紅綠藍。
// 創建一個pixel類型
struct {bit [7:0] r, g, b ;} pixel ;
上例中的聲明只是創建了一個pixel變量。要想在端口和程序中共享它,則必須創建一個新的類型,如下所示:
// pixel 結構
typedef struct {bit [7:0] r, g, b ;} pixel_s ;
pixel_s my_pixel ;
2.10.2 對結構進行初始化
如同數組賦值一樣,賦值時把數值放到帶單引號的大括號中。
// 對struct類型進行初始化
initial begin
typedef struct {
int a ;
byte b ;
shortint c ;
int d ;
} my_struct_s ;
my_struct_s st = '{
32'haaaa_aaaad,
8'hbb,
16'hcccc,
32'hdddd_dddd
}
$display ("str = %x %x %x %x ", st.a, st.b, st.c, st.d) ;
end
2.10.3 創建可容納不同類型的聯合
在硬件中,寄存器里的某些位的含義可能與其他位的值有關。下例把整數i和實數f存放到同一位置上。
// 使用typedef創建聯合
typedef union { int i; real f; } num_u ;
num_u un ;
un.f = 0.0 ; // 把數值設為浮點形式
如果需要以若干個不同的格式對同一寄存器進行頻繁讀寫時,聯合體相當有用。但是不要濫用。
2.10.4 合並結構
合並結構是以連續比特集方式存放的,中間沒有閑置的空間。2.10.1節的pixel結構使用了3個數值,所以它占用了3個長字的存儲空間,即使它實際只需要3個字節。你可以指定把它合並到盡可能小的空間里。
// 例2.40 合並結構
typedef struct packed {bit [7:0] r, g, b; } pixel_p_s ;
pixel_p_s my_pixel ;
2.10.5 合並結構和非合並結構的選擇
必須考慮結構通常的使用方式和元素的對齊方式。
如果對結構的操作很頻繁,例如需要經常對整個結構體進行復制,那么使用合並結構的效率會比較高。但是,如果操作經常是針對結構內的個體成員而非整體,那就應該使用非合並結構。當結構的元素不按字節對齊,或者元素位寬與字節不匹配,又或者元素是處理器的指令字時,使用合並和非合並結構在性能上的差別會更大。對合並結構中尺寸不規則的元素進行讀寫,需要移位和屏蔽操作票,代價很高。
2.11 類型轉換
如果源變量和目標變量的比特分布完全相同,例如整數和枚舉類型(一般枚舉的存儲是int),那么它們之間可以直接相互賦值。
如果源變量和目標變量的比特分布不同,例如字節數組和字數組,則需要使用流操作符對比特分布重新安排。
2.11.1 靜態轉換
靜態轉換操作不對轉換值進行檢查。轉換時指定目標類型,並在需要轉換的表達式前加上單引號即可。注意,Verilog對整數和實數類型,或者不同位寬的向量之間進行隱式轉換。
// 例2.41 在整型和實型之間進行靜態轉換
int i ;
real r ;
i = int '{10.0 - 0.1} ; // 非強制轉換
r = real '{42} ; // 非強制轉換
2.11.2 動態轉換
動態轉換函數 $cast 允許對越界的數值進行檢查。
2.11.3 流操作符
流操作符 << 和 >> 用在賦值表達式的右邊,后邊帶表達式、結構或數組。流操作符用於把其后的數據打包成一個比特流。操作符 >> 把數據從左至右變成流,而 << 則把數據從右至左變成流。不能將比特流的結果直接賦值給非合並數組,而應該在賦值表達式的左邊使用流操作符把比特流拆分到非合並數組中。
// 例2.42 基本的流操作
initial begin
int h ;
bit [7:0] b, g[4], j[4] = '{8'ha, 8'hb, 8'hc, 8'hd} ;
bit [7:0] q, r, s, t ;
h = {>> { j }} ; // 0a0b0c0d 把數組打包成整型
h = {<< { j }} ; // b030d050 位倒序
h = {<< byte { j }} ; // 0d0c0b0a 字節倒序
g = {<< byte { j }} ; // 0d, 0c, 0b, 0a 拆分成數組
b = {<< { 8'b0011_0101 }} ; // 1010_1100 位倒序
b = {<< 4 { 8'b0011_0101 }} ; // 0101_0011 半字節倒序
{>> {q, r, s, t}} = j ; // 把j分散到4個字節變量里
h = {>> {t, s, r, q}} ; // 把字節集中到h里
end
也可以使用很多連接符 {} 來完成同樣的操作,但是流操作符用起來更簡潔並且易於閱讀。
如果需要打包或拆分數組,可以使用流操作符來完成具有不同尺寸元素的數組間的轉換。
// 例 2.43 使用流操作符進行隊列間的轉換
initial begin
bit [15:0] wq [$] = {16'h1234, 16'h5678} ;
bit [7 :0] bq [$] ;
//把字數組轉換成字節數組
bq = {>> { wq }} ; // 12 34 56 78
// 把字節數組轉換成字數組
bq = {8'h98, 8'h76, 8'h54, 8'h32} ;
wq = {>> { bq }} ; // 9876 5432
end
數組下標失配是在數組間進行流操作時常見的錯誤。數組聲明中的下標 [256] 等同於 [0:255]。由於很多數組使用 [high:low] 的下標形式進行聲明,使用流操作把它們的值賦給帶 [size] 下標形式的數組會造成元素倒序。同樣,如果把聲明形式為 bit [7:0] src [255:0] 的非合並數組使用流操作賦值給聲明形式為 bit [7:0] [255:0] dst 的合並數組,則數值的順序會被打亂。對於合並的字節數組,正確的聲明形式應該是 bit [255:0] [7:0] dst。
流操作符也可以用來將結構打包或拆分到字節數組中。下例中,使用流操作符把結構轉換成動態的字節數組,然后字節數組又被反過來轉換成結構。
// 例2.44 使用流操作符在結構和數組間進行轉換
initial begin
typedef struct {
int a ;
byte b ;
shortint c ;
int d ;
} my_struct_s ;
my_struct_s st = '{
32'haaaa_aaaa ,
8'hbb ,
16'hcccc ,
32'hdddd_dddd
} ;
byte b [] ;
// 將結構轉換成字節數組
b = {>> { st }} ; // {aa aa aa aa bb cc cc dd dd dd dd}
// 將字節數組轉換成結構
b = '{
8'h11, 8'h22, 8'h33, 8'h44,
8'h55,
8'h66, 8'h77,
8'h88, 8'h99, 8'haa, 8'hbb
} ;
st = {>> { b }} ; // st = 11223344,55,6677,8899aabb
end
2.12 枚舉類型
在學會使用枚舉類型之前,你只能使用文本宏。宏的作用范圍太大,而且大多數情況下對於調試者是可見的。枚舉創建了一種強大的變量類型,它僅限於一些特定名稱的集合,例如指令中的操作碼或者狀態機中的狀態名。定義常量的另一種方法是使用參數。但參數需要對每個值進行單獨的定義,而枚舉類型卻能夠自動為列表中的每個名稱分配不同的數值。
簡單的枚舉類型聲明包含了一個常量名稱列表以及一個或多個變量。下例中的方式創建的是一個匿名的枚舉類型,它只能用於這個例子中聲明的變量。
// 例2.45 一個簡單的枚舉類型
enum {RED, BLUE, GREEN} color ;
創建一個署名的枚舉類型有利於聲明更多新變量,尤其是當這些變量被用作子程序參數或模塊端口時。你需要首先創建枚舉類型,然后再創建相應的變量。使用內建的 name() 函數,你可以得到枚舉變量值對應的字符串,如下例所示:
// 例2.46 枚舉類型
// 創建代表 0, 1, 2 的數據類型
typedef enum {INIT, DECODE, IDLE} fsmstate_e ;
fsmstate_e pstate, nstate ; // 聲明自定義類型變量
initial begin
case (pstate)
IDLE : nstate = INIT ; // 數據賦值
INIT : nstate = DECODE ;
default : nstate = IDLE ;
endcase
$display ("Next state is %s", nstate.name()) ; // 顯示狀態的符號名
end
2.12.1 定義枚舉值
枚舉值缺省為從 0 開始遞增的整數。你可以定義自己的枚舉值。如下例所示,使用INIT代表缺省值 0,DECODE代表 2,IDLE代表 3。
// 例2.47 指定枚舉值
typedef enum {INIT, DECODE = 2, IDLE} fsmtype_e ;
如果沒有特別指出,枚舉類型會被當成 int 類型存儲。由於int類型的缺省值是0,所以在給枚舉常量賦值時務必小心。在下例中,position 會被初始化為0,這並不是一個合法的 ordinal_e 變量。這種情況是語言本身所規定的,而非工具上的缺陷。因此把0指定給一個枚舉常量可以避免這個錯誤。
// 例2.48 指定枚舉值,不正確
typedef enum {FIRST = 1, SECOND, THIRD} ordinal_e ;
ordinal_e position ;
// 例2.49 指定枚舉值,正確
typedef enum {BAD_O, FIRST = 1, SECOND, THIRD} ordinal_e ;
ordinal_e position ;
2.12.2 枚舉類型的子程序
SystemVerilog提供一些可以遍歷枚舉類型的函數:
| 序號 | 函數名 | 作用 |
|---|---|---|
| 1 | first () | 返回第一個枚舉常量 |
| 2 | last () | 返回最后一個枚舉常量 |
| 3 | next () | 返回下一個枚舉常量 |
| 4 | next (N) | 返回以后第N個枚舉常量 |
| 5 | prev () | 返回前一個枚舉變量 |
| 6 | prev (N) | 返回以前第N個枚舉變量 |
當到達枚舉常量列表的頭或尾時,函數 next 和 prev 會自動以環形的方式繞回。
注意,由於環形繞回特性,用 for 循環變量枚舉類型中所有成員會導致永遠不會退出。此時需要使用 do...while 循環來遍歷所有值,如下例所示。
// 例2.50 遍歷所有枚舉成員
typedef enum {RED, BLUE, GREEN} color_e ;
color_e color ;
color = color.first ;
do
begin
$display ("Color = %0d/%s", color, color.name) ;
color = color.next ;
end
while (color != color.first) ; // 環形繞回時即完成循環
2.12.3 枚舉類型的轉換
枚舉類型的缺省類型位雙狀態 int。可以使用簡單的賦值表達式把枚舉變量的值直接賦給非枚舉變量如 int。但SystemVerilog不允許在沒有顯式類型的情況下把整型變量賦給枚舉變量。SystemVerilog要求顯式類型轉換的目的在於讓你意識到可能存在的數值越界情況。
// 例2.51 整型和枚舉類型之間相互賦值
typedef enum {RED, BLUE, GREEN} COLOR_E ;
COLOR_E color, c2 ;
int c ;
initial begin
color = BLUE ; // 賦一個已知的合法值
c = color ; // 將枚舉類型轉換成整型 (1)
c++ ; // 整型遞增 (2)
if (!$cast(color, c)) // 將整型顯式轉換回枚舉類型
$display ("Cast failed for c = %0d", c) ;
$display ("Color is %0d /%s", color, color.name) ;
c++ ; // 3對於枚舉類型已經越界
c2 = COLOR_E '(c) ; // 靜態類型轉換,不做類型檢查
$display ("c2 is %0d/%s", c2, c2.name) ;
end
在上例中,$cast 被當成函數進行調用,目的在於把其右邊的值賦給左邊的量。如果賦值成功,$cast() 返回 1。如果因為數值越界而導致失敗,則不進行任何賦值,函數返回 0。如果把 $cast 當成任務使用並且操作失敗,則SystemVerilog會打印出錯誤信息。
2.13 常量
SystemVerilog中有好幾種類型的常量。
- 文本宏。它的好處是:宏具有全局作用范圍並且可以用於位段和類型定義。它的缺點同樣是因為宏具有全局作用范圍,在你只需要一個局部常量時可能會引發沖突。此外,宏定義需要使用“`”符號,這樣它才能被編譯器識別和擴展。
- parameter。Verilog中的parameter並沒有嚴格的類型界定,而且其作用范圍僅限於單個模塊里。
- const修飾符。允許在變量聲明時對其進行初始化,但不能在過程代碼中改變其值。
在SystemVerilog中,參數可以在程序包里聲明,因此可以在多個模塊中共同使用。這種方式可以替換掉Verilog中很多用來表示常量的宏。你可以用 typedef 來替換掉那些單調乏味的宏。
// 例2.52 const 變量的聲明
initial begin
const byte colon = ":" ;
...
end
2.14 字符串
SystemVerilog新增的string類型可以用來保存長度可變的字符串。單個字符是byte類型。長度為N的字符串中,元素編號從0到N-1。注意,和C語言不同的是,字符串的結尾並不帶標識符null,所有嘗試使用字符“\0”的操作都會被忽略。字符串使用動態的存儲方式,所以不用擔心存儲空間會被全部用完。
字符串相關的幾種操作:
| 操作 | 說明 |
|---|---|
| getc (N) | 返回位置N上的字節 |
| toupper | 返回一個所有字符大寫的字符串 |
| tolower | 返回一個所有字符小寫的字符串 |
| 大括號 { } | 用於串接字符 |
| putc(M, C) | 把字節C寫到字符串的M位上,M必須介於0和len所給出的長度之間 |
| substr (start, end) | 提取從位置 start 到 end 之間的所有字符 |
// 例2.53 字符串方法
string s ;
initial begin
s = "IEEE " ;
$display (s.getc (0)) ; // 顯示:73 (‘I’)
$display (s.tolower ()) ; // 顯示:ieee
s.putc (s.len() -1, "-"); // 將空格變成‘-’
s = {s, "P1800"} ; // "IEEE-P1800
$display (s.substr (2, 5)) ; // 顯示:EE-P
//創建臨時字符串,注意格式
my_log ($psprintf ("%s %5d", s, 42)) ;
end
task my_log (string message) ;
// 把信息打印到日志里
$display ("@%0t: %s", $time, message) ;
endtask
在上例中,函數 $psprintf () 替代了Verilog-2001 中的函數 $sformat () 。這個新函數返回一個格式化的臨時字符串,並且可以直接傳遞給其他子程序。這樣你就可以不用定義新的臨時字符串並在格式化語句與函數調用過程中傳遞這個字符串。
2.15 表達式位寬
在Verilog中,表達式的位寬是造成行為不可預測的主要源頭之一。下例使用4種不同方式實現 1+1。
方式A,使用2個單比特變量,在這種精度下得到 1+1 = 0。
方式B,由於賦值表達式的左邊有一個8比特的變量,所以其精度是8比特,得到的結果是 1+1 = 2。
方式C,采用一個啞元常數強迫SystemVerilog使用2比特精度。
方式D,第一個值在轉換符的作用下被指定為2比特的值,所以 1+1 = 2。
// 例2.54 表達式位寬依賴於上下文
bit [7:0] b8 ;
bit one = 1'b1 ; // 單比特
$displayb (one + one) ; // A;1+1=0
b8 = one + one ; // B:1+1=2
$displayb (b8) ;
$displayb (one + one + 2'b0) ; // C:1+1=2,使用了常量
$displayb (2'(one) + one) ; // D:1+1=2,使用了靜態類型轉換