問題的發現
前段時間,我們一個基於libbeat開發的日志采集服務經常發生OOM的告警,OOM的排查大都比較簡單,直接查看目標容器的內存變化情況即可。如圖所示
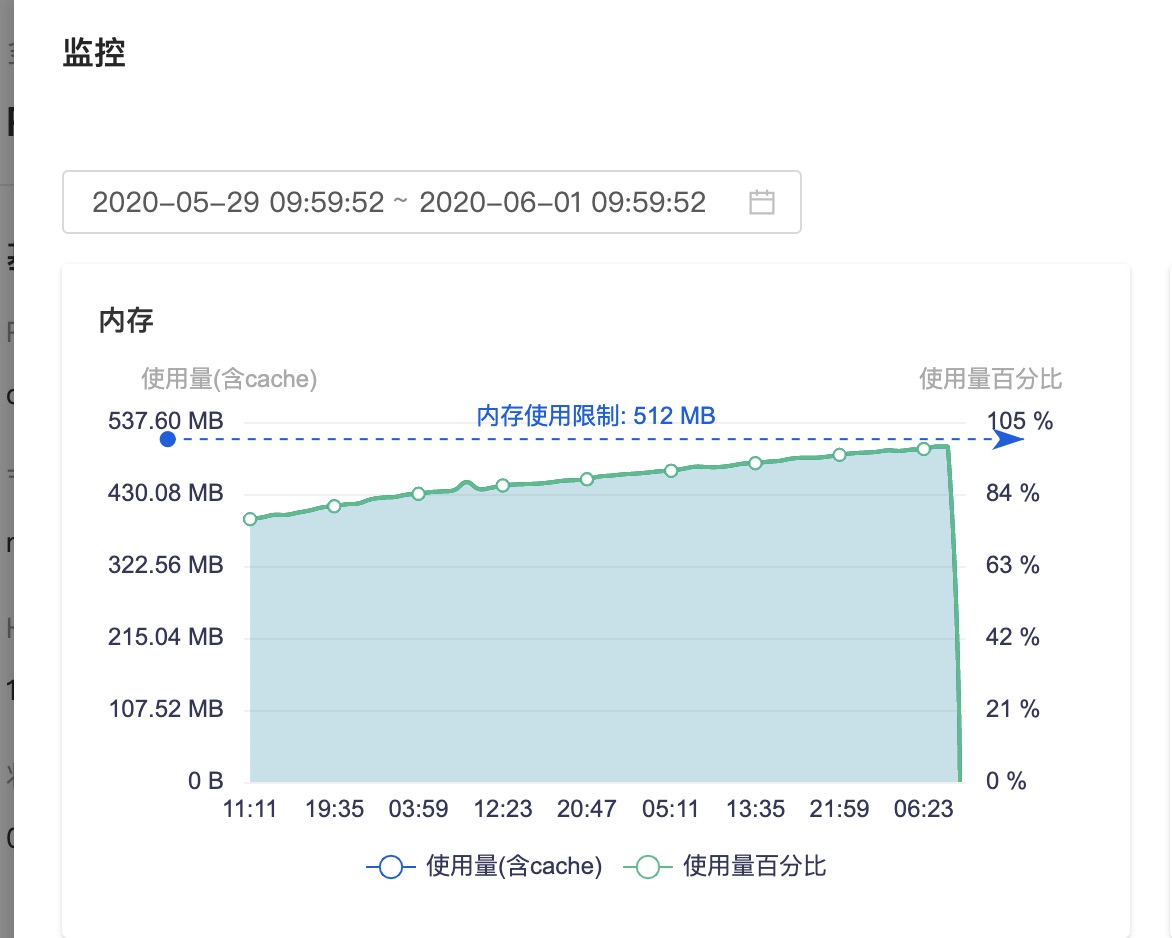
從上圖可以看出,內存隨着時間呈線增長的趨勢,然后在到達閾值之后瞬間降為0,實際上就是OOM了。
相信稍微有點經驗的同學,應該都能大致斷定這是個內存泄露的問題了。而Go程序的內存泄露大部分則都是goroutine泄露導致的。
畫外音
這里,若你的程序並沒有接入監控,那么也可以通過vmstat工具來人工觀察內存的變化情況。不管怎樣,我們需要的是能觀察到內存隨時間的變化情況。
問題代碼段定位
既然知道了問題的大致方向,那自然也就有了排查思路了。
首先,既然是用Go編寫的應用程序,那么很自然,我們就應該想到pprof工具,它會動態跟蹤記錄程序運行過程中的各項參數,並提供各種工具圖表來幫助你定位問題,功能強大又好用。這里,如果你對pprof工具還不熟悉的,建議先行閱讀官方文檔或者Google一些入門教程。
接着,我通過添加啟動參數--pprof,來激活預置的pprof端口服務。通常,我們會預置類似下面代碼塊,以便在出現問題的時候,激活pprof功能。
import _ "net/http/pprof"
...
func main() {
...
if cfg.Pprof {
http.ListenAndServe(":6060", nil)
}
...
}
修改完成后,我重啟了docker容器。並在容器中執行curl http://localhost:6060/debug/pprof/heap > h1.out以及curl http://localhost:6060/debug/pprof/goroutine > g1.out命令獲取heap和goroutine的信息。這里由於是排查內存問題,我就取了heap和goroutine的數據。
在間隔30分鍾后(這個取決於內存的增長速率),我再次執行curl http://localhost:6060/debug/pprof/heap > h2.out以及curl http://localhost:6060/debug/pprof/goroutine > g2.out命令。
這里,我為什么要間隔30分鍾取兩次樣本數據呢?還是因為我們需要的是變化情況,而非當前狀態,這很關鍵。
內存泄露的原因有很多,比如http body未Close,channel阻塞導致goroutine泄露等等。
因此,首先需要排查一下是不是其他非goroutine泄露的原因導致內存泄露,我首先執行go tool pprof --base h1.out h2.out,進入交互界面,然后執行top10、web等命令。很不幸,我並沒有發現什么異常。
隨后,就是需要排查goroutine泄露了,執行go tool pprof --base g1.out g2.out,接着我執行top5命令,發現runtime.gopark積累了很多,然后我使用了traces命令,發現是Next.func1goroutine異常地多,使用list Next.func1發現,在71行有1315個goroutine阻塞了,在通過web檢查也是同樣的情況。很顯然是這快代碼有問題。那么究竟是什么原因導致的呢?

PS
上圖是我后面在本地壓測復現時的圖,當時排查生產環境時未截圖記錄,因此后續大家排查的時候一定要記錄好。方便后續復盤、回顧所用。
根因探究
看似,我們的重點都在問題的發現以及問題代碼段定位上了,然而在我看來熟悉了上面排查思路以及pprof等工具的使用后,還是相對比較容易定位的。
而根因的探究,則需要你對應用程序的源碼很熟悉才行,網上的教程由於用的都是很簡單的demo,因此看起來似乎很容易就解決了,然而實際代碼往往非常的龐大而復雜。因此這一步,需要你對應用程序的源碼比較熟悉,這樣才能快速准確的找到問題背后的原因。
實際上,由於我才接手這一塊,在這一步上也卡了很久。最終,通過反復閱讀源碼和設計文檔,並且與社區深度討論之后,定位到了原因。
簡單來說,這是由於這里的goroutine是依賴於第70行返回的err來判斷並退出的,然而,由於在日志采集相關goroutine在執行關閉操作的過程中,有新的message被采集並發送到r.ch上,而此時從r.ch上消費的邏輯已暫停,從而即便后續關閉操作執行完成,r.reader.Next()返回錯誤,也會阻塞在第71行。具體想了解的可以查閱這個issue。
可以看出,有效可靠地關閉goroutine是多么的重要,稍不留神就泄露了。
文章主要是記錄了一次實際goroutine泄露的發現-排查-根因定位的全過程。對工具的介紹和使用,基本不涉及,你可以通過查閱其他資料學習