基於Tesseract組件的OCR識別
背景以及介紹
欲研究C#端如何進行圖像的基本OCR識別,找到一款開源的OCR識別組件。該組件當前已經已經升級到了4.0版本。和傳統的版本(3.x)比,4.0時代最突出的變化就是基於LSTM神經網絡。Tesseract本身是由C++進行編寫,但為了同時適配不同的語言進行調用,開放調用API並產生了諸如Java、C#、Python等主流語言在內的封裝版本。本次主要研究C#封裝版。
項目結構
Tesseract本身由C++編寫並開源在Github,在3.X版本中,Tesseract的識別模式為字符識別,該種識別方式識別能力較低,所以在后來的4.X版本中,引入了LSTM(Long short-term memory,長短期記憶神經網絡),極大的提升了識別率。為了讓不同的語言均能夠使用Tesseract進行OCR識別,Tesseract也是開放了API並產生了諸如Java、C#、Python等主流語言在內的封裝版本。而本次C#端的封裝版也開源在了Github,目前已知的C#封裝版已發布在nuget上,封裝了對應Tesseract的版本為3.05.02。所以目前的項目結構如下:

Demo實驗
環境准備
文本識別數據包准備
因為圖像識別本身需要文本識別數據進行匹配,所以我們需要下載對應Tesseract官方的文本數據包:
https://tesseract-ocr.github.io/tessdoc/Data-Files
注意,針對不同版本的Tesseract-OCR(3.X和4.X底層的實現方式不同,所以文本識別數據包是不同的),我們需要找到對應的不同的文本訓練數據包,官網為了更好的兼容性,4.X版本的文本數據包是兼容了3.X版本的。
the third set in tessdata is the only one that supports the legacy recognizer. The 4.00 files from November 2016 have both legacy and older LSTM models. The current set of files in tessdata have the legacy models and newer LSTM models (integer versions of 4.00.00 alpha models in tessdata_best).
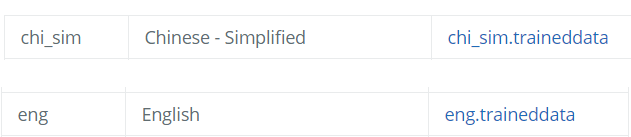
為了Demo,我下載了中文簡體和英文的數據包作為實驗對象
開發環境准備
為了實驗並對比上面兩個封裝版本的識別效果,這里在同一解決方案中創建了兩個項目:
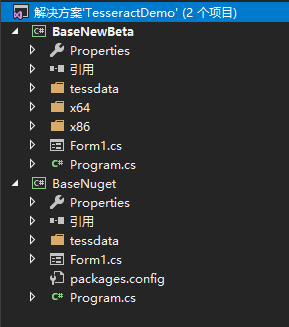
BaseNewBeta使用的是封裝了4.1版本Tesseract的C#封裝版Tesseract.4.1.0-beta1,因為該版本還還沒有上傳只Nuget,所以只能從github上下載,放到本地,然后把對應的C++的底層庫(leptonica-1.78.0.dll,tesseract41.dll)放置到了x86和x64文件夾下面且需要輸出。
BaseNuget是已經上傳至Nuget的封裝了底層庫3.05.20版本的C#封裝版3.3.0.0,因為使用nuget進行組件安裝,所以x64和x86的Tesseract組件會在編譯輸出時候自動輸出到對應的生成目錄。
核心代碼
if (openFileDialog1.ShowDialog() == DialogResult.OK)
{
//PictureBox控件顯示圖片
pictureBox1.Load(openFileDialog1.FileName);
//獲取用戶選擇文件的后綴名
string extension = Path.GetExtension(openFileDialog1.FileName);
//聲明允許的后綴名
string[] str = new string[] { ".jpg", ".png" };
if (!str.Contains(extension))
{
MessageBox.Show("僅能上傳jpg,png格式的圖片!");
}
else
{
//識別圖片文字
Bitmap img = new Bitmap(openFileDialog1.FileName);
// 構建識別引擎
TesseractEngine orcEngine = new TesseractEngine("./tessdata", "eng");
// 識別並獲取文本數據
Page page = orcEngine.Process(img);
richTextBox1.Text = page.GetText();
}
}
最終效果
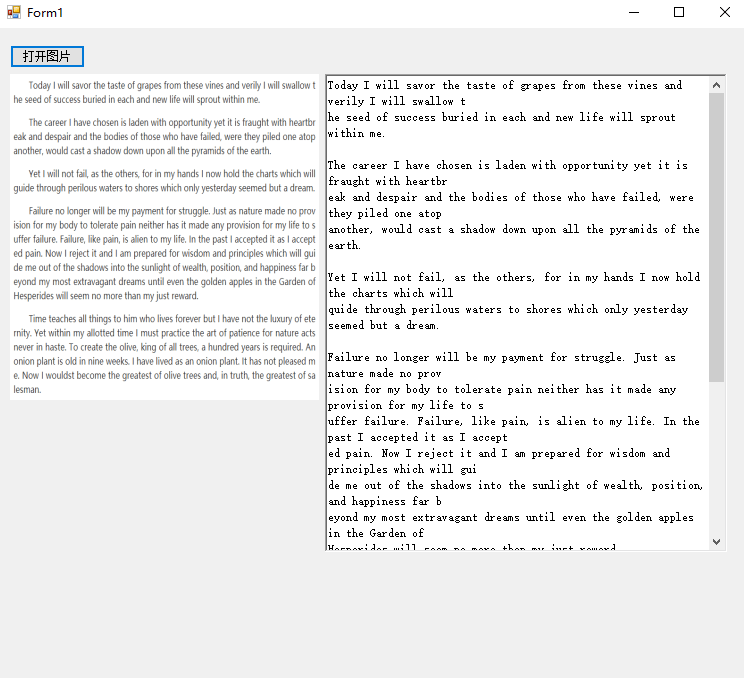
英文識別效果
先是3.X版本識別:

可以看到文本中還有很多識別的錯誤的,特別是把英文字符C識別為了括號(。
而封裝了新版本的識別結果比起之前更好:
中文識別效果
先是3.X版本識別:

然后是封裝的版本:
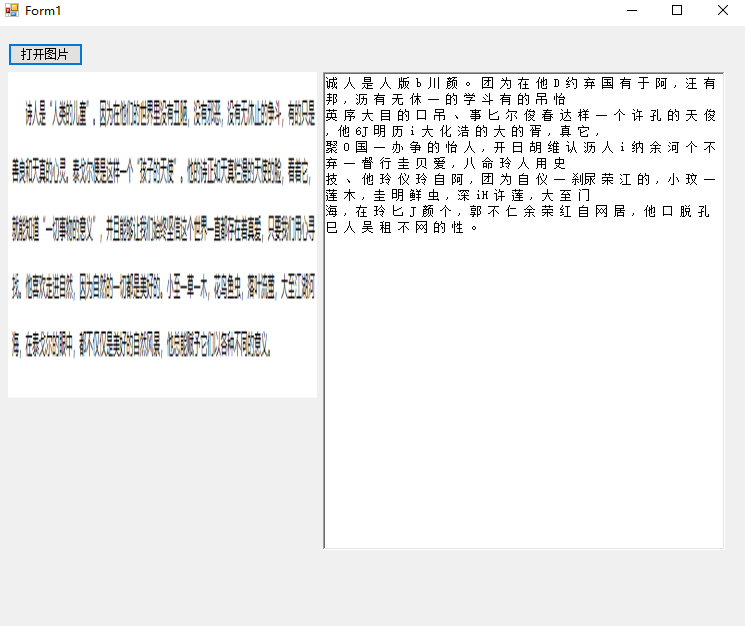
看的出來,官方的數據包對於中文的識別還是有很大問題的,不過慶幸的是,4.X版本的后的Tesseract支持我們使用的自己的數據進行識別訓練。這樣一來,雖然該組件還比不上市面上大多數的商業OCR識別,但是我們可以使用訓練數據,來訓練適用於我們特定業務的文字識別(比如XX碼的提取之類)