Elasticsearch(簡稱ES)是一個基於Apache Lucene(TM)的開源搜索引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫。
一、Elasticsearch簡介
1、應用場景
-
海量數據分析引擎
-
站內搜索引擎
-
數據倉庫
一線公司應用場景
-
實時分析公眾對文章的回應
-
GitHub-站內實時搜索
-
百度-日志監控平台
2、Elasticsearch是什么
Elasticsearch是一個基於Apache Lucene(TM)的開源搜索引擎,無論在開源還是專有領域,Lucene可以被認為是迄今為止最先進、性能最好的、功能最全的搜索引擎庫。 但是,Lucene只是一個庫。想要發揮其強大的作用,你需使用Java並要將其集成到你的應用中。Lucene非常復雜,你需要深入的了解檢索相關知識來理解它是如何工作的。 Elasticsearch也是使用Java編寫並使用Lucene來建立索引並實現搜索功能,但是它的目的是通過簡單連貫的RESTful API讓全文搜索變得簡單並隱藏Lucene的復雜性。 不過,Elasticsearch不僅僅是Lucene和全文搜索引擎,它還提供:
-
分布式的實時文件存儲,每個字段都被索引並可被搜索
-
實時分析的分布式搜索引擎
-
可以擴展到上百台服務器,處理PB級結構化或非結構化數據
而且,所有的這些功能被集成到一台服務器,你的應用可以通過簡單的RESTful API、各種語言的客戶端甚至命令行與之交互。上手Elasticsearch非常簡單,它提供了許多合理的缺省值,並對初學者隱藏了復雜的搜索引擎理論。它開箱即用(安裝即可使用),只需很少的學習既可在生產環境中使用。Elasticsearch在Apache 2 license下許可使用,可以免費下載、使用和修改。 隨着知識的積累,你可以根據不同的問題領域定制Elasticsearch的高級特性,這一切都是可配置的,並且配置非常靈活。
3、Elasticsearch中涉及到的重要概念
Elasticsearch有幾個核心概念。從一開始理解這些概念會對整個學習過程有莫大的幫助。
(1) 接近實時(NRT) Elasticsearch是一個接近實時的搜索平台。這意味着,從索引一個文檔直到這個文檔能夠被搜索到有一個輕微的延遲(通常是1秒)。
(2) 集群(cluster) 一個集群就是由一個或多個節點組織在一起,它們共同持有你整個的數據,並一起提供索引和搜索功能。一個集群由一個唯一的名字標識,這個名字默認就是“elasticsearch”。這個名字是重要的,因為一個節點只能通過指定某個集群的名字,來加入這個集群。在產品環境中顯式地設定這個名字是一個好習慣,但是使用默認值來進行測試/開發也是不錯的。
(3) 節點(node) 一個節點是你集群中的一個服務器,作為集群的一部分,它存儲你的數據,參與集群的索引和搜索功能。和集群類似,一個節點也是由一個名字來標識的,默認情況下,這個名字是一個隨機的漫威漫畫角色的名字,這個名字會在啟動的時候賦予節點。這個名字對於管理工作來說挺重要的,因為在這個管理過程中,你會去確定網絡中的哪些服務器對應於Elasticsearch集群中的哪些節點。
一個節點可以通過配置集群名稱的方式來加入一個指定的集群。默認情況下,每個節點都會被安排加入到一個叫做“elasticsearch”的集群中,這意味着,如果你在你的網絡中啟動了若干個節點,並假定它們能夠相互發現彼此,它們將會自動地形成並加入到一個叫做“elasticsearch”的集群中。
在一個集群里,只要你想,可以擁有任意多個節點。而且,如果當前你的網絡中沒有運行任何Elasticsearch節點,這時啟動一個節點,會默認創建並加入一個叫做“elasticsearch”的集群。
(4) 索引(index) 一個索引就是一個擁有幾分相似特征的文檔的集合。比如說,你可以有一個客戶數據的索引,另一個產品目錄的索引,還有一個訂單數據的索引。一個索引由一個名字來標識(必須全部是小寫字母的),並且當我們要對對應於這個索引中的文檔進行索引、搜索、更新和刪除的時候,都要使用到這個名字。索引類似於關系型數據庫中Database的概念。在一個集群中,如果你想,可以定義任意多的索引。
(5) 類型(type) 在一個索引中,你可以定義一種或多種類型。一個類型是你的索引的一個邏輯上的分類/分區,其語義完全由你來定。通常,會為具有一組共同字段的文檔定義一個類型。比如說,我們假設你運營一個博客平台並且將你所有的數據存儲到一個索引中。在這個索引中,你可以為用戶數據定義一個類型,為博客數據定義另一個類型,當然,也可以為評論數據定義另一個類型。類型類似於關系型數據庫中Table的概念。
(6)文檔(document) 一個文檔是一個可被索引的基礎信息單元。比如,你可以擁有某一個客戶的文檔,某一個產品的一個文檔,當然,也可以擁有某個訂單的一個文檔。文檔以JSON(Javascript Object Notation)格式來表示,而JSON是一個到處存在的互聯網數據交互格式。 在一個index/type里面,只要你想,你可以存儲任意多的文檔。注意,盡管一個文檔,物理上存在於一個索引之中,文檔必須被索引/賦予一個索引的type。文檔類似於關系型數據庫中Record的概念。實際上一個文檔除了用戶定義的數據外,還包括_index、_type和_id字段。
(7) 分片和復制(shards & replicas) 一個索引可以存儲超出單個結點硬件限制的大量數據。比如,一個具有10億文檔的索引占據1TB的磁盤空間,而任一節點都沒有這樣大的磁盤空間;或者單個節點處理搜索請求,響應太慢。
為了解決這個問題,Elasticsearch提供了將索引划分成多份的能力,這些份就叫做分片。當你創建一個索引的時候,你可以指定你想要的分片的數量。每個分片本身也是一個功能完善並且獨立的“索引”,這個“索引”可以被放置到集群中的任何節點上。 分片之所以重要,主要有兩方面的原因:
-
允許你水平分割/擴展你的內容容量
-
允許你在分片(潛在地,位於多個節點上)之上進行分布式的、並行的操作,進而提高性能/吞吐量
至於一個分片怎樣分布,它的文檔怎樣聚合回搜索請求,是完全由Elasticsearch管理的,對於作為用戶的你來說,這些都是透明的。
在一個網絡/雲的環境里,失敗隨時都可能發生,在某個分片/節點不知怎么的就處於離線狀態,或者由於任何原因消失了。這種情況下,有一個故障轉移機制是非常有用並且是強烈推薦的。為此目的,Elasticsearch允許你創建分片的一份或多份拷貝,這些拷貝叫做復制分片,或者直接叫復制。復制之所以重要,主要有兩方面的原因:
-
在分片/節點失敗的情況下,提供了高可用性。因為這個原因,注意到復制分片從不與原/主要(original/primary)分片置於同一節點上是非常重要的。
-
擴展你的搜索量/吞吐量,因為搜索可以在所有的復制上並行運行
總之,每個索引可以被分成多個分片。一個索引也可以被復制0次(意思是沒有復制)或多次。一旦復制了,每個索引就有了主分片(作為復制源的原來的分片)和復制分片(主分片的拷貝)之別。分片和復制的數量可以在索引創建的時候指定。在索引創建之后,你可以在任何時候動態地改變復制數量,但是不能改變分片的數量。
默認情況下,Elasticsearch中的每個索引被分片5個主分片和1個復制,這意味着,如果你的集群中至少有兩個節點,你的索引將會有5個主分片和另外5個復制分片(1個完全拷貝),這樣的話每個索引總共就有10個分片。一個索引的多個分片可以存放在集群中的一台主機上,也可以存放在多台主機上,這取決於你的集群機器數量。主分片和復制分片的具體位置是由ES內在的策略所決定的。
以上部分內容轉自Elasticsearch基礎教程,並對其進行了補充。
二、Elasticsearch安裝與配置
1、安裝與運行
(1) 從這里下載Elasticsearch安裝包。一共提供4種格式的安裝包(ZIP、TAR.GZ、DEB和RPM),可以根據自己所使用的系統平台選擇相應格式的安裝包進行下載。(建議使用Linux系統,本人在2台windows機器上嘗試啟動過,一台機器上無法正常啟動,另外一台可以)
(2) 對下載的安裝包進行解壓縮即可完成安裝操作。下面以在Ubuntu操作系統下使用TAR.GZ格式的1.5.0版本的安裝包為例進行安裝。在Linux shell中輸入下面的命令解壓縮。
tar –vxf elasticsearch-1.5.0.tar.gz
安裝成功,下面運行ES。
注意:Elasticsearch需要Java虛擬機的支持,在運行之前保證機器上安裝了JDK,並且JDK版本不能低於1.7_55。
(3) 現在可以直接使用默認配置啟動Elasticsearch了。 假設安裝包解壓后的目錄路徑為【/home/elasticsearch/elasticsearch-1.5.0】,下面軍用$ES_HOME來表示這個路徑。執行下面的命令:
cd /home/elasticsearch/elasticsearch-1.5.0/bin/
chmod +x *
./elasticsearch
如果出現如圖所示的界面(最后打印出started),則說明Elasticsearch啟動成功。 
下面來驗證一下是否真的啟動成功。打開瀏覽器,訪問網址 http://host:9200(這里的host是ES的安裝主機地址,如果安裝在本機,就是http://127.0.0.1:9200)。如果顯示下面的信息,則表示ES安裝成功。
{
"status" : 200,
"name" : "Captain Zero",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.5.0",
"build_hash" : "544816042d40151d3ce4ba4f95399d7860dc2e92",
"build_timestamp" : "2015-03-23T14:30:58Z",
"build_snapshot" : false,
"lucene_version" : "4.10.4"
},
"tagline" : "You Know, for Search"
}
上面是前台啟動方式,一旦關閉Linux shell,ES服務就會停止。所以是實際使用過程中,絕對不會使用這種方式去啟動ES。除了上面的啟動方式外,還可以加上一定的啟動參數。例如:
./elasticsearch –d #在后台運行Elasticsearch
./elasticsearch -d -Xmx2g -Xms2g #后台啟動,啟動時指定內存大小(2G)
./elasticsearch -d -Des.logger.level=DEBUG #可以在日志中打印出更加詳細的信息。
2、ES的配置
配置文件所在的目錄路徑如下:$ES_HOME/config/elasticsearch.yml。 下面介紹一些重要的配置項及其含義。
(1)cluster.name: elasticsearch
配置elasticsearch的集群名稱,默認是elasticsearch。elasticsearch會自動發現在同一網段下的集群名為elasticsearch的主機,如果在同一網段下有多個集群,就可以用這個屬性來區分不同的集群。生成環境時建議更改。
(2)node.name: “Franz Kafka”
節點名,默認隨機指定一個name列表中名字,該列表在elasticsearch的jar包中config文件夾里name.txt文件中,其中有很多作者添加的有趣名字,大部分是漫威動漫里面的人物名字。生成環境中建議更改以能方便的指定集群中的節點對應的機器
(3)node.master: true
指定該節點是否有資格被選舉成為node,默認是true,elasticsearch默認集群中的第一台啟動的機器為master,如果這台機掛了就會重新選舉master。
(4)node.data: true
指定該節點是否存儲索引數據,默認為true。如果節點配置node.master:false並且node.data: false,則該節點將起到負載均衡的作用
(5)index.number_of_shards: 5
設置默認索引分片個數,默認為5片。經本人測試,索引分片對ES的查詢性能有很大的影響,在應用環境,應該選擇適合的分片大小。
(6)index.number_of_replicas:
設置默認索引副本個數,默認為1個副本。此處的1個副本是指index.number_of_shards的一個完全拷貝;默認5個分片1個拷貝;即總分片數為10。
(7)path.conf: /path/to/conf
設置配置文件的存儲路徑,默認是es根目錄下的config文件夾。
(8)path.data:/path/to/data1,/path/to/data2
設置索引數據的存儲路徑,默認是es根目錄下的data文件夾,可以設置多個存儲路徑,用逗號隔開。
(9)path.work:/path/to/work
設置臨時文件的存儲路徑,默認是es根目錄下的work文件夾。
(10)path.logs: /path/to/logs
設置日志文件的存儲路徑,默認是es根目錄下的logs文件夾
(11)path.plugins: /path/to/plugins
設置插件的存放路徑,默認是es根目錄下的plugins文件夾
(12)bootstrap.mlockall: true
設置為true來鎖住內存。因為當jvm開始swapping時es的效率會降低,所以要保證它不swap,可以把ES_MIN_MEM和ES_MAX_MEM兩個環境變量設置成同一個值,並且保證機器有足夠的內存分配給es。同時也要允許elasticsearch的進程可以鎖住內存,linux下可以通過
ulimit -l unlimited命令。
(13)network.bind_host: 192.168.0.1
設置綁定的ip地址,可以是ipv4或ipv6的,默認為0.0.0.0。
(14)network.publish_host: 192.168.0.1
設置其它節點和該節點交互的ip地址,如果不設置它會自動判斷,值必須是個真實的ip地址。
(15)network.host: 192.168.0.1
這個參數是用來同時設置bind_host和publish_host上面兩個參數。
(16)transport.tcp.port: 9300
設置節點間交互的tcp端口,默認是9300。
(17)transport.tcp.compress: true
設置是否壓縮tcp傳輸時的數據,默認為false,不壓縮。
(18)http.port: 9200
設置對外服務的http端口,默認為9200。
(19)http.max_content_length: 100mb
設置內容的最大容量,默認100mb
(20)http.enabled: false
是否使用http協議對外提供服務,默認為true,開啟。
(21)gateway.type: local
gateway的類型,默認為local即為本地文件系統,可以設置為本地文件系統,分布式文件系統,hadoop的HDFS,和amazon的s3服務器,其它文件系統的設置。
(22)gateway.recover_after_nodes: 1
設置集群中N個節點啟動時進行數據恢復,默認為1。
(23)gateway.recover_after_time: 5m
設置初始化數據恢復進程的超時時間,默認是5分鍾。
(24)gateway.expected_nodes: 2
設置這個集群中節點的數量,默認為2,一旦這N個節點啟動,就會立即進行數據恢復。
(25)cluster.routing.allocation.node_initial_primaries_recoveries: 4
初始化數據恢復時,並發恢復線程的個數,默認為4。
(26)cluster.routing.allocation.node_concurrent_recoveries: 2
添加刪除節點或負載均衡時並發恢復線程的個數,默認為4。
(27)indices.recovery.max_size_per_sec: 0
設置數據恢復時限制的帶寬,如入100mb,默認為0,即無限制。
(28)indices.recovery.concurrent_streams: 5
設置這個參數來限制從其它分片恢復數據時最大同時打開並發流的個數,默認為5。
(29)discovery.zen.minimum_master_nodes: 1
設置這個參數來保證集群中的節點可以知道其它N個有master資格的節點。默認為1,對於大的集群來說,可以設置大一點的值(2-4)
(30)discovery.zen.ping.timeout: 3s
設置集群中自動發現其它節點時ping連接超時時間,默認為3秒,對於比較差的網絡環境可以高點的值來防止自動發現時出錯。
(31)discovery.zen.ping.multicast.enabled: false
設置是否打開多播發現節點,默認是true。
(32)discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”, “host3 [portX-portY] “]
設置集群中master節點的初始列表,可以通過這些節點來自動發現新加入集群的節點。
除了上面的在安裝時配置文件中就自帶的配置項外,本人在實際使用過程還使用到了下面的配置:
threadpool:
search:
type: fixed
min: 60
max: 80
queue_size: 1000
// 配置es服務器的執行查詢操作時所用線程池,fix固定線程數的線程池。
index :
store:
type: memory
// 表示索引存儲在內存中,當然es不太建議這么做。經本人測試,做查詢時,使用內存索引並不會比正常的索引快。
index.mapper.dynamic: false
// 禁止自動創建mapping。默認情況下,es可以根據數據類型自動創建mapping。配置成這樣,可以禁止自動創建mapping的行為。至於什么是mapping,在之后的博文中再介紹。
index.query.parse.allow_unmapped_fields: false
// 不能查找沒有在mapping中定義的屬性
以上總結介紹了Elasticsearch中的一些基礎知識,包括其中的一些核心概念。只有理解了ES中的這些核心概念,才能對更加得心應手地使用ES,發揮其強大的搜索能力。同時,也介紹了ES的安裝和運行,ES的安裝和運行是很簡單的,只需要極少的簡單步驟,就可以開始體驗ES。ES的配置非常豐富,安裝時自帶的配置文件只包含一部分比較核心的配置項,更多的配置內容需要自己去閱讀ES的源碼時才能被發現。
3、單實例安裝
-
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.tar.gz-
wget命令可以直接通過http協議下載,當然我們也可以在網頁下載
-
-
tar -vxf 解壓 -
cd elasticsearch-5.5.2-
核心文件有
-
config,modules,plugins
-
-
啟動命令:
./bin/elasticseatch -
出現下圖界面,started啟動成功, 默認9200端口

es1.png
-
訪問url,es默認返回的 *json* 數據格式

es2.png
-
插件安裝
-
head插件,提供了友好的web界面,基本信息查看
-
下載完文件為
master.zip文件,進行解壓unzip master.zip -
進入解壓完成的文件
cd elasticsearch-head-master -
node -v可以看到版本號 -
npm install安裝 -
npm run start服務啟動

es3.png
-
-
訪問瀏覽器效果:

es4.png
此時連接是未連接,因為我剛剛將es服務停了,現在需要配置幾個東西。
-
修改配置
-
原因:es和head屬於兩個進程,其之間的訪問具備跨域問題,所以需要配置修改
-
進入elasticsearch-5.5.2 修改 yml

es5.png
-
-
添加最后兩行
-
啟動 加 -d參數
./bin/elasticsearch -d后台啟動 -
重新啟動head
cd elasticsearch-head-master,npm run start -
刷新瀏覽器,連接狀態green
三、ES Restful API基本使用:
ES為開發者提供了非常豐富的基於HTTP協議的Rest API,只需要向ES服務端發送簡單的Rest請求,就可以實現非常強大的功能。本篇文章主要介紹ES中常用操作的Rest API的使用,同時會講解ES的源代碼工程中的API接口文檔,通過了解這個API文檔的接口描述結構,就基本上可以實現ES中的絕大部分功能。
注意:查詢是ES的核心。作為一個先進的搜索引擎,ES中提供了多種查詢接口。本篇僅僅會涉及查詢API的結構,而具體如何使用ES所提供的各種查詢API,會在接下來的博文中做詳細介紹。
1、基礎知識
如果之前沒有用過類似於ES這樣的索引數據庫(暫且將ES歸為數據庫類,與傳統的數據庫有較大的區別),要理解本篇博文介紹的API是有些難度的。本節先介紹一些基礎知識,對理解全文有很幫助。
2、Rest介紹
筆者在學習軟件開發過程中,多次聽到過Rest Http這個概念,但在很長的一段時間里,死活搞不懂這玩意到底是個什么東西。剛開始看相關資料時,看得雲里霧里,完全不知所雲 _。這玩意太過於抽象和理論,心里覺得有必要搞這么復雜么。隨着自己動手開發的東西越來越多,才開始對它有了一丟丟感覺。
Rest完全不是三言兩語就能將清楚的,它有自己的一套體系,所以筆者打算以后單獨寫一些有關Rest的博文。在這里推薦一篇優秀的文章,它對Rest講的相當清楚,本人看完之后真有醍醐灌頂的感覺!
3、Mapping詳解
Mapping是ES中的一個很重要的內容,它類似於傳統關系型數據中table的schema,用於定義一個索引(index)的某個類型(type)的數據的結構。
在傳統關系型數據庫,我們必須首先創建table並同時定義其schema,如下面的SQL語句。下面代碼中小括號內的代碼的作用就是定義person_info的schema(模式)。
create table person_info
(
name varchar(20),
age tinyint
)
在ES中,我們無需手動創建type(相當於table)和mapping(相關與schema)。在默認配置下,ES可以根據插入的數據自動地創建type及其mapping。在下面的API介紹部分中,會做相關的試驗。當然,在實際使用過程中我們可能就想硬性規定mapping,可以通過配置文件關閉ES的自動創建mapping功能。
mapping中主要包括字段名、字段數據類型和字段索引類型這3個方面的定義。
字段名:這就不用說了,與傳統數據庫字段名作用一樣,就是給字段起個唯一的名字,好讓系統和用戶能識別。
字段數據類型:定義該字段保存的數據的類型,不符合數據類型定義的數據不能保存到ES中。下表列出的是ES中所支持的數據類型。(大類是對所有類型的一種歸類,小類是實際使用的類型。)
| 大類 | 包含的小類 |
|---|---|
| String | string |
| Whole number | byte, short, integer, long |
| Floating point | float, double |
| Boolean | boolean |
| Date | date |
字段索引類型:索引是ES中的核心,ES之所以能夠實現實時搜索,完全歸功於Lucene這個優秀的Java開源索引。在傳統數據庫中,如果字段上建立索引,我們仍然能夠以它作為查詢條件進行查詢,只不過查詢速度慢點。而在ES中,字段如果不建立索引,則就不能以這個字段作為查詢條件來搜索。也就是說,不建立索引的字段僅僅能起到數據載體的作用。string類型的數據肯定是日常使用得最多的數據類型,下面介紹mapping中string類型字段可以配置的索引類型。
| 索引類型 | 解釋 |
|---|---|
| analyzed | 首先分析這個字符串,然后再建立索引。換言之,以全文形式索引此字段。 |
| not_analyzed | 索引這個字段,使之可以被搜索,但是索引內容和指定值一樣。不分析此字段。 |
| no | 不索引這個字段。這個字段不能被搜索到。 |
如果索引類型設置為analyzed,在表示ES會先對這個字段進行分析(一般來說,就是自然語言中的分詞),ES內置了不少分析器(analyser),如果覺得它們對中文的支持不好,也可以使用第三方分析器。由於筆者在實際項目中僅僅將ES用作普通的數據查詢引擎,所以並沒有研究過這些分析器。如果將ES當做真正的搜索引擎,那么挑選正確的分析器是至關重要的。
mapping中除了上面介紹的3個主要的內容外,還有其他的定義內容,詳見官網文檔。
四、常用的Rest API介紹
下面介紹一下ES中的一些常用的Rest API。掌握了這些API的用法,基本上就可以簡單地使用ES了。
我們需要借助能夠發送HTTP請求的工具調用這些API,工具是可以任意的,包括網頁瀏覽器。這里利用Linux上的curl命令來發送HTTP請求。基本的命令結構為:
curl <-Xaction> url -d 'body'
# 這里的action表示HTTP協議中的各種動作,包括GET、POST、PUT、DELETE等。
注意。文中的示例代碼里面包含了用戶注釋的文字,就是 # 號后面的文字。運行代碼時,請注意刪除這些注釋。
1、查看集群(Cluster)信息相關API
(1)查看集群健康信息。
curl -XGET "localhost:9200/_cat/heath?v"
返回結果為:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks
1440206633 18:23:53 elasticsearch green 1 1 0 0 0 0 0 0
返回結果的主要字段意義:
-
cluster:集群名,是在ES的配置文件中配置的cluster.name的值。
-
status:集群狀態。集群共有green、yellow或red中的三種狀態。green代表一切正常(集群功能齊全),yellow意味着所有的數據都是可用的,但是某些復制沒有被分配(集群功能齊全),red則代表因為某些原因,某些數據不可用。如果是red狀態,則要引起高度注意,數據很有可能已經丟失。
-
node.total:集群中的節點數。
-
node.data:集群中的數據節點數。
-
shards:集群中總的分片數量。
-
pri:主分片數量,英文全稱為private。
-
relo:復制分片總數。
-
unassign:未指定的分片數量,是應有分片數和現有的分片數的差值(包括主分片和復制分片)。
我們也可以在請求中添加help參數來查看每個操作返回結果字段的意義。
curl -XGET "localhost:9200/_cat/heath?help"
返回結果如下:
epoch | t,time | seconds since 1970-01-01 00:00:00
timestamp | ts,hms,hhmmss | time in HH:MM:SS
cluster | cl | cluster name
status | st | health status
node.total | nt,nodeTotal | total number of nodes
node.data | nd,nodeData | number of nodes that can store data
shards | t,sh,shards.total,shardsTotal | total number of shards
pri | p,shards.primary,shardsPrimary | number of primary shards
relo | r,shards.relocating,shardsRelocating | number of relocating nodes
init | i,shards.initializing,shardsInitializing | number of initializing nodes
unassign | u,shards.unassigned,shardsUnassigned | number of unassigned shards
pending_tasks | pt,pendingTasks | number of pending tasks
確實是很好很強大。有了這個東東,就可以減少看文檔的時間。ES中許多API都可以添加help參數來顯示字段含義,哪些可以這么做呢?每個API都試試就知道了。
當然,如果你覺得返回的東西太多,看着眼煩,我們也可以人為地指定返回的字段。
curl -XGET "localhost:9200/_cat/health?h=cluster,pri,relo&v"
這次的返回結果就簡單很多羅。對於患有嚴重強迫症的患者來說,這是福音啊!
cluster pri relo
elasticsearch 0 0
(2)查看集群中的節點信息。
curl -XGET "localhost:9200/_cat/nodes?v"
返回節點的詳細信息如下:
host ip heap.percent ram.percent load node.role master name
master.hadoop localhost 3 35 0.00 d * Ezekiel
(3)查看集群中的索引信息。
curl -XGET "localhost:9200/_cat/indices?v"
返回集群中的索引信息如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
yellow open index_test 5 1 0 0 575b 575b
更多的查看和監視ES的API參見官網文檔。
2、索引(Index)相關API
(1)創建一個新的索引。
curl -XPUT "localhost:9200/index_test"
如果返回下面的信息,則說明索引創建成功。如果不是,則ES會返回相應的異常信息。通常可以通過異常信息的最后一項推斷出失敗的原因。
{
"acknowledged": true
}
上面的操作使用默認的配置信息創建一個索引。大多數情況下,我們想在索引創建的時候就將我們所需的mapping和其他配置確定好。下面的操作就可以在創建索引的同時,創建settings和mapping。
curl -XPUT "localhost:9200/index_test" -d ' # 注意這里的'號
{
"settings": {
"index": {
"number_of_replicas": "1", # 設置復制數
"number_of_shards": "5" # 設置主分片數
}
},
"mappings": { # 創建mapping
"test_type": { # 在index中創建一個新的type(相當於table)
"properties": {
"name": { # 創建一個字段(string類型數據,使用普通索引)
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
}'
(2)刪除一個索引。
curl -XDELETE "localhost:9200/index_test"
如果返回與創建索引同樣的信息,則說明刪除成功。反之,則返回相應的異常信息。
3、映射(Mapping)相關API
(1)創建索引的mapping。
curl -XPUT 'localhost:9200/index_test/_mapping/test_type' -d '
{
"test_type": { # 注意,這里的test_type與url上的test_type名保存一致
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}'
如果不想單獨創建mapping,可以使用上一節的方法(創建索引時創建mappings)。
假設我們的項目中有多個環境(開發環境、測試環境等),那每一個環境的mapping總要一致的吧,那每次創建一次mappings就比較麻煩了,而且還容易導致數據不一致。莫急,ES還給我們准備另外一種創建mapping的方式。可以按照下面的步驟來做。
步驟1 創建一個擴展名為test_type.json的文件名,其中type_test就是mapping所對應的type名。
步驟2 在test_type.json中輸入mapping信息。假設你的mapping如下:
{
"test_type": { # 注意,這里的test_type與json文件名必須一致
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"age": {
"type": "integer"
}
}
}
}
步驟3 在$ES_HOME/config/路徑下創建mappings/index_test子目錄,這里的index_test目錄名必須與我們要建立的索引名一致。將test_type.json文件拷貝到index_tes目錄下。
步驟4 創建index_test索引。操作如下:
curl -XPUT "localhost:9200/index_test" # 注意,這里的索引名必須與mappings下新建的index_test目錄名一致
這樣我們就創建了一個新的索引,並且使用了test_type.json所定義的mapping作為索引的mapping。就是這么簡單方便!
(2)刪除mapping。
curl -XDELETE 'localhost:9200/index_test/_mapping/test_type'
(3)查看索引的mapping。
curl -XGET 'localhost:9200/index_test/_mapping/test_type'
4、文檔(document)相關API
(1)新增一個文檔。
curl -XPUT 'localhost:9200/index_test/test_type/1?pretty' -d ' # 這里的pretty參數的作用是使得返回的json顯示地更加好看。1是文檔的id值(唯一鍵)。
{
"name": "zhangsan",
"age" : "12"
}'
(2)更新一個文檔
curl -XPOST 'localhost:9200/index_test/test_type/1?pretty' -d ' # 這里的1必須是索引中已經存在id,否則就會變成新增文檔操作
{
"name": "lisi",
"age" : "12"
}'
(3)刪除一個文檔
curl -XDELETE 'localhost:9200/index_test/test_type/1?pretty' # 這里的1必須是索引中已經存在id
(4)查詢單個文檔
curl -XGET 'localhost:9200/index_test/test_type/1?pretty'
上面的操作僅僅查詢id為1的一條文檔,這樣看似乎ES的查詢也太弱了。前面已經說過了,查詢操作是ES中的核心,是其立身的根本。但是本文的重點並不在這里,為了防止文章的篇幅過長,之后將專本介紹ES中的查詢操作。
5、源代碼中提供的Rest API文檔結構
ES的源代碼托管在Github上。將源代碼下載下來之后,里面有一個文件夾專門存放ES中絕大部分的Rest API。有了這些文檔,就不必每次都要到官網上查詢接口文檔了(PS:ES的官網真的很慢)。 下面以cat.health.json文件為例簡單地介紹這些Rest API文檔的結構。一旦結構搞清楚了,文檔看起來就比較順心,ES用起來就更加得心應手了!
{
"cat.health": {
"documentation": "http://www.elastic.co/guide/en/elasticsearch/reference/master/cat-health.html", # 該文檔對應的官方站點
"methods": ["GET"],
"url": { # url部分可選
"path": "/_cat/health",
"paths": ["/_cat/health"],
"parts": {
},
"params": {
"local": {
"type" : "boolean",
"description" : "Return local information, do not retrieve the state from master node (default: false)"
},
"master_timeout": {
"type" : "time",
"description" : "Explicit operation timeout for connection to master node"
},
"h": {
"type": "list",
"description" : "Comma-separated list of column names to display"
},
"help": {
"type": "boolean",
"description": "Return help information",
"default": false
},
"ts": {
"type": "boolean",
"description": "Set to false to disable timestamping",
"default": true
},
"v": {
"type": "boolean",
"description": "Verbose mode. Display column headers",
"default": true
}
}
},
"body": null
}
}
上面文檔接口所對應的Reqeust操作如下:
curl -XGET "localhost:9200/_cat/health?v" -d 'body'
該操作命令可划分為5個部分,下面把這5個部分與文檔對應起來。通過這個例子,就可以在閱讀其他文檔后,使用正確的操作了。
-
第1部分(-XGET):對應文檔中methods所包含的GET操作。
-
第2部分(localhost:9200):是ES服務端所在主機的hostname和port。
-
第3部分(/_cat/health):對應文檔中的url。其中path是最簡單的url;paths是除了path之外的其他url;parts描述和解釋paths里面的url的可變部分(通常用{}包裹,如{index})。
-
第4部分v:表示參數,對應文檔中的params。像“v”這種boolean類型的參數,不需要特意指定其布爾值(true或者false),出現即表示true,否則為false。
-
第5部分body:表示要傳遞的數據主體,對應文檔中的body。如果body里面指明“required=true”,則表示必須傳入body數據。具體body里面需要傳怎樣的數據,則可以訪問文檔中的documentation字段所指明的官方站點進行查詢。
第二章、ElasticSearch實戰
一、 Elasticsearch史上最全最常用工具清單
1、題記 工欲善其事必先利其器,ELK Stack的學習和實戰更是如此,特將工作中用到的“高效”工具分享給大家。
希望能借助“工具”提高開發、運維效率!
2、工具分類概覽 2.1 基礎類工具 1、Head插件
1)功能概述:
ES集群狀態查看、索引數據查看、ES DSL實現(增、刪、改、查操作) 比較實用的地方:json串的格式化

2)地址:http://mobz.github.io/elasticsearch-head/
2、Kibana工具
除了支持各種數據的可視化之外,最重要的是:支持Dev Tool進行RESTFUL API增刪改查操作。 ——比Postman工具和curl都方便很多。

地址:https://www.elastic.co/products/kibana
3、ElasticHD工具
強勢功能——支持sql轉DSL,不要完全依賴,可以借鑒用。

地址:https://github.com/360EntSecGroup-Skylar/ElasticHD
2.2 集群監控工具 4、cerebro工具

地址:https://github.com/lmenezes/cerebro
5、Elaticsearch-HQ工具
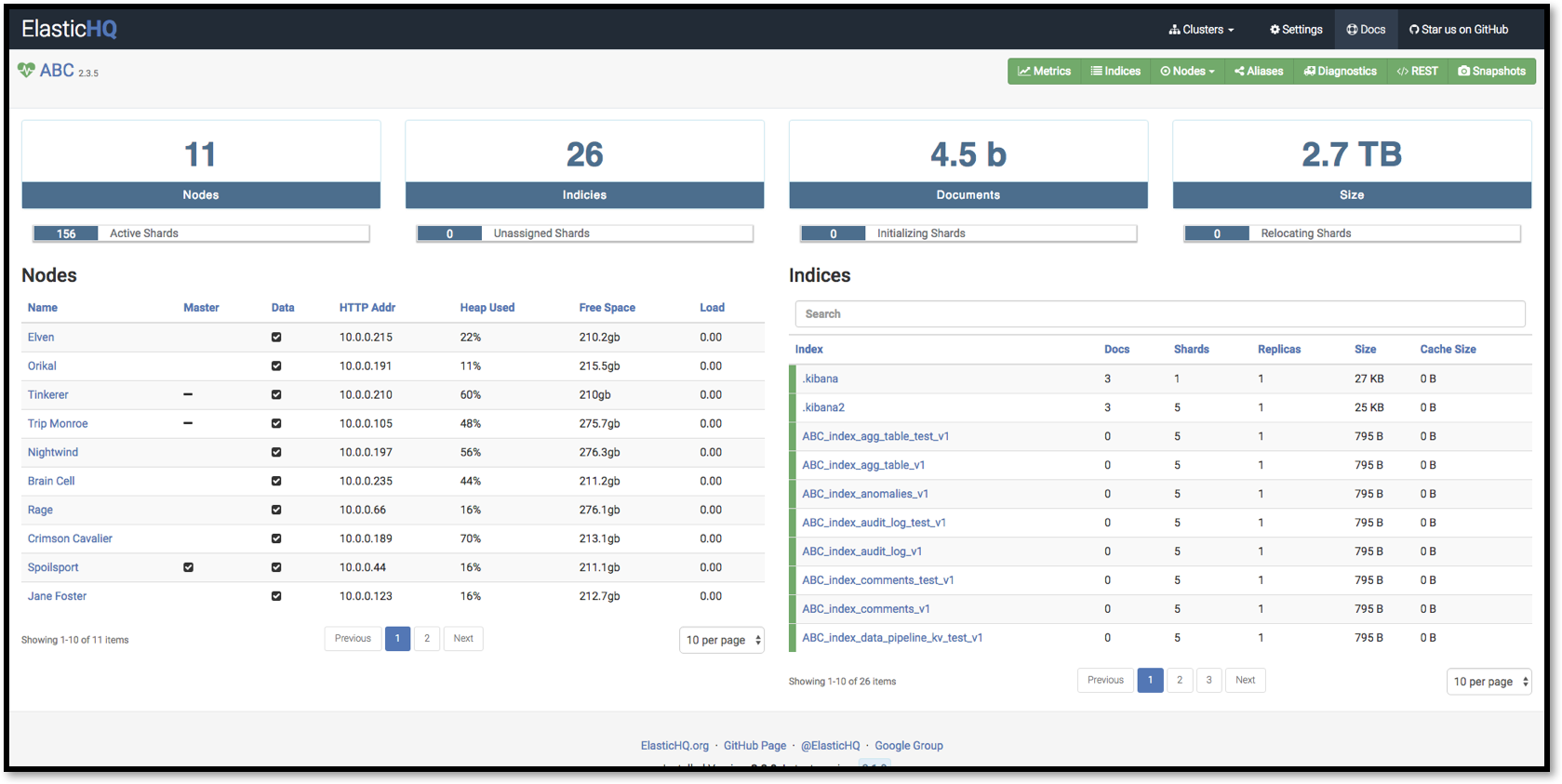
管理elasticsearch集群以及通過web界面來進行查詢操作
地址:https://github.com/royrusso/elasticsearch-HQ
2.3 集群遷移工具 6、Elasticsearch-migration工具
支持多個版本間的數據遷移,使用scroll+bulk
地址:https://github.com/medcl/elasticsearch-migration
7、Elasticsearch-Exporter
將ES中的數據向其他導出的簡單腳本實現。
地址:https://github.com/mallocator/Elasticsearch-Exporter
8、Elasticsearch-dump
移動和保存索引的工具。
地址:https://github.com/taskrabbit/elasticsearch-dump
2.4 集群數據處理工具 9、elasticsearch-curator
elasticsearch官方工具,能實現諸如數據只保留前七天的數據的功能。
地址: https://pypi.python.org/pypi/elasticsearch-curator
另外 ES6.3(還未上線) 有一個 Index LifeCycle Management 可以很方便的管理索引的保存期限。
2.5 安全類工具 10、x-pack工具

地址:https://www.elastic.co/downloads/x-pack
11、search-guard 第三方工具
Search Guard 是 Elasticsearch 的安全插件。它為后端系統(如LDAP或Kerberos)提供身份驗證和授權,並向Elasticsearch添加審核日志記錄和文檔/字段級安全性。
Search Guard所有基本安全功能(非全部)都是免費的,並且內置在Search Guard中。 Search Guard支持OpenSSL並與Kibana和logstash配合使用。
地址:https://github.com/floragunncom/search-guard
2.6 可視化類工具 12、grafana工具

地址:https://grafana.com/grafana
grafana工具與kibana可視化的區別:
如果你的業務線數據較少且單一,可以用kibana做出很棒很直觀的數據分析。 而如果你的數據源很多並且業務線也多,建議使用grafana,可以減少你的工作量
對比: https://www.zhihu.com/question/54388690 2.7 自動化運維工具 elasticsearch免費的自動化運維工具
13、Ansible
https://github.com/elastic/ansible-elasticsearch
14、Puppet
https://github.com/elastic/puppet-elasticsearch
15、Cookbook
https://github.com/elastic/cookbook-elasticsearch
以上三個工具來自medcl大神社區問題的回復,我沒有實踐過三個工具。
2.8 類SQl查詢工具 16、Elasticsearch-sql 工具
sql 一款國人NLP-china團隊寫的通過類似sql語法進行查詢的工具
地址:https://github.com/NLPchina/elasticsearch-sql
ES6.3+以后的新版本會集成sql。
2.9 增強類工具 17、Conveyor 工具
kibna插件——圖形化數據導入工具
18、kibana_markdown_doc_view 工具
Kibana文檔查看強化插件,以markdown格式展示文檔
19、 indices_view工具
indices_view 是新蛋網開源的一個 kibana APP 插件項目,可以安裝在 kibana 中,快速、高效、便捷的查看elasticsearch 中 indices 相關信息
地址:https://gitee.com/newegg/indices_view
20、dremio 工具
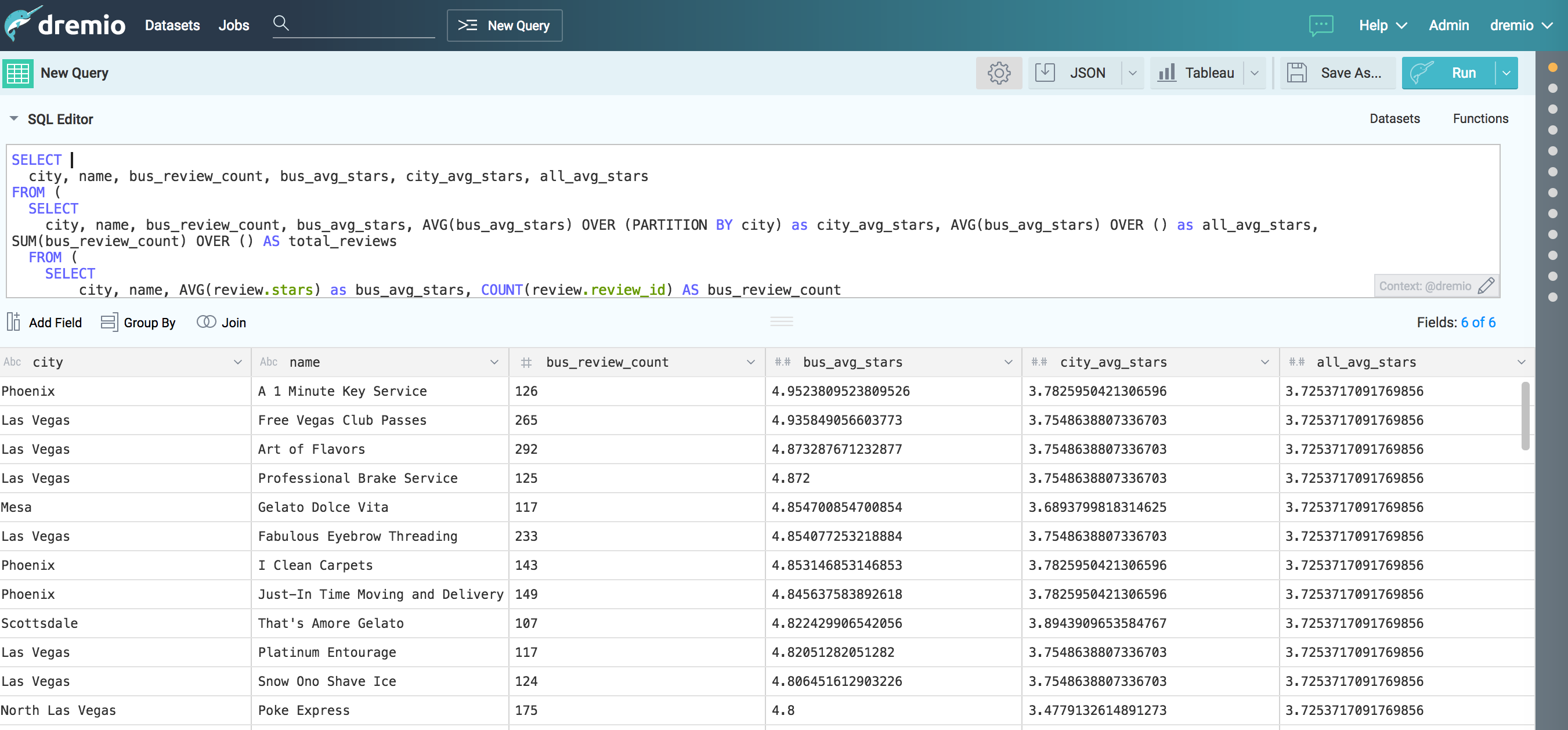
-
支持sql轉DSL,
-
支持elasticsearch、mysql、oracle、mongo、csv等多種格式可視化處理;
-
支持ES多表的Join操作
2.10 報警類 1、elastalert ElastAlert 是 Yelp 公司開源的一套用 Python2.6 寫的報警框架。屬於后來 Elastic.co 公司出品的 Watcher 同類產品。官網地址見:http://elastalert.readthedocs.org/。
使用舉例:當我們把ELK搭建好、病順利的收集到日志,但是日志里發生了什么事,我們並不能第一時間知道日志里到底發生了什么,運維需要第一時間知道日志發生了什么事,所以就有了ElastAlert的郵件報警。
2、sentinl SENTINL 6擴展了Siren Investigate和Kibana的警報和報告功能,使用標准查詢,可編程驗證器和各種可配置操作來監控,通知和報告數據系列更改 - 將其視為一個獨立的“Watcher” “報告”功能(支持PNG / PDF快照)。
SENTINL還旨在簡化在Siren Investigate / Kibana 6.x中通過其本地應用程序界面創建和管理警報和報告的過程,或通過在Kibana 6.x +中使用本地監視工具來創建和管理警報和報告的過程。
二、索引
1、Elasticsearch(ES)創建索引
歡迎關注博主公眾號“小哈學Java”,專注於分享Java領域干貨文章,關注回復“資源”,免費領取全網最熱的Java架構師學習PDF,轉載請注明出處https:// www .exception.site / elasticsearch / elasticsearch-create-index
一,開始創建索引
您可以通過Elasticsearch的RESTFul API來創建索引:
PUT http://127.0.0.1:9200/commodity
注意:最小情況下,創建的索引分片數量是5個,副本數量是1個。
您可以通過以下參數來指定分片數,副本數量:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
1.1實戰演示
通過CURL命令來上手操作一下,我們嘗試創建一個商品索引,看下效果:
curl -X PUT "localhost:9200/commodity?pretty"
索引創建成功會返回以下出參:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "commodity"
}
如下圖所示:

二,創建帶有類型,映射的索引
其實,我們可以在創建索引的時候,同時將索引的類型,以及映射一並創建好:
curl -X PUT "localhost:9200/commodity?pretty"
入參:
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
},
"mapping": {
"_doc": {
"properties": {
"commodity_id": {
"type": "long"
},
"commodity_name": {
"type": "text"
},
"picture_url": {
"type": "keyword"
},
"price": {
"type": "double"
}
}
}
}
}
我們創建了一個分片數為3,副本數為2的索引,同時,定義了一個_doc的類型,里面包含了4個段落,類型各不相同。
接下來,我們用Postman工具來一次性創建帶有類型,映射的索引(索引):

這里應為筆者通過CURL創建索引,由於帶入參,出現了格式錯誤的問題,改用了Postman工具,效果相同。
三,修改索引的副本數
我們可以通過如下API來修改索引的副本數:
PUT http://127.0.0.1:9200/commodity/_settings
入參:
{
"number_of_replicas": 3
}
我們將commodity索引副本數更新為了3:

2、Elasticsearch(ES)刪除索引
歡迎關注博主公眾號“小哈學Java”,專注於分享Java領域干貨文章,關注回復“資源”,免費領取全網最熱的Java架構師學習PDF,轉載請注明出處https:// www .exception.site / elasticsearch / elasticsearch-delete-index
一,開始刪除索引
通過如下Elasticserach API來刪除索引:
PUT http://127.0.0.1:9200/commodity
如上示例,刪除了名稱為commodity的索引。另外指定名稱刪除外,我們還可以通過索引別名或通配符來刪除。
注意:要謹慎使用
_all或*去刪除全部索引。
生產環境中,為了防止索引被誤刪,我們可以將elasticsearch.yml配置文件中的action.destructive_requires_name配置項設置為true,以達到強制使用索引名,別名才能刪除索引的效果。
二,實戰操作
接下來,我們通過CURL命令來刪除commodity索引:
curl -X DELETE "localhost:9200/commodity?pretty"

3、Elasticsearch(ES) 獲取索引信息
一、通過具體索引名稱來獲取索引信息
通過 Elasticsearch 提供的接口,我們可以獲取一個或多個索引信息。
GET http://127.0.0.1:9200/commodity
這里,我們用 CURL 命令來演示一下,來獲取 commodity 索引的具體信息:
curl -X GET http://127.0.0.1:9200/commodity?pretty
效果如下:

如圖所示,結果中包含了索引的映射信息,以及一些配置信息。
注意:若索引中是空的,也就是沒有一條文檔的話,映射(mapping)信息將是空的。
二、通過通配符來獲取索引信息
除了上面說到的,通過具體索引名稱來獲取索引信息外,我們還可以通過別名或通配符來獲取。
通過通配符來或者 _all 或 * 來多個索引的信息。
三、添加篩選條件來獲取索引信息
我們可以在 URL 中指定篩選條件,只獲取自己想要的信息,比如只想要 commodity 索引的映射信息,操作如下:
GET http://127.0.0.1:9200/commodity/_mappings
通過 CURL 命令來演示下:
curl -X GET http://127.0.0.1:9200/commodity/_mappings?pretty

可以看到,只返回了索引的映射信息。
如果你只想獲取索引的配置信息,通過如下接口即可:
GET http://127.0.0.1:9200/commodity/_settings

4、Elasticsearch(ES) 打開/關閉索引
什么是 Elasticsearch 打開/關閉索引? 先說說什么是關閉索引?一旦索引被關閉,那么這個索引只能顯示元數據信息,不能夠進行讀寫操作。
再說說打開索引就好理解了。就是打開被關閉的索引,允許進行讀寫操作。
通過 /{索引名}/_close 關閉索引
通過 /{索引名}/_open 打開索引
一、關閉索引
比如說,我們想關閉 commodity 索引:
POST http://127.0.0.1:9200/commodity/_close
CURL 命令如下:
curl -X POST http://127.0.0.1:9200/commodity/_close?pretty

索引已經被關閉成功,這個時候,我們再向 commodity 添加一條文檔信息,看看結果如何:

可以看到,返回了一個索引已被關閉的異常,文檔無法被正常創建。
二、打開索引
通過如下請求,我們可以打開一個被關閉的索引:
POST http://127.0.0.1:9200/commodity/_open
接下來,我們通過 CURL 命令來打開剛剛被關閉的 commodity 索引:
curl -X POST http://127.0.0.1:9200/commodity/_open?pretty

文檔被打開成功后,我們就可以愉快的對索引進行讀寫操作了。
三、映射、
1、Elasticsearch(ES) 添加/更新映射
通過 Elasticsearch API 可以向索引(Index) 添加文檔類型(Type), 或者向文檔類型(Type) 中添加/更新字段(Field)。
PUT http://127.0.0.1:9200/commodity
入參:
{
"mappings": {
"_doc": {
"properties": {
"commodity_id": {
"type": "long"
},
"commodity_name": {
"type": "text"
},
"picture_url": {
"type": "keyword"
}
}
}
}
}
接下來,通過 Postman 工具來實際操作一下:

通過上面 API, 我們創建了一個名稱為 commodity(商品) 的索引,類型為_doc, 且包含了三個字段(field), 分別為 commodity_id(商品id)、commodity_name (商品名稱)、picture_url(商品圖片)。
一、向已存在的類型中添加字段
commodity 索引創建成功后,我們還可以向其中添加新的字段,下面添加一個 price(價格)字段:
PUT http://127.0.0.1:9200/commodity/_mapping/_doc
入參:
{
"properties": {
"price": {
"type": "double"
}
}
}
用 Postman 工具演示一下:

二、同時向多個索引設置映射
Elasticsearch 允許同時向多個索引添加文檔類型。
PUT http://127.0.0.1:9200/{index}/_mapping/{type}
{body}
-
{index}: 索引可以有多種指定方式:
-
逗號分隔符,比如:
comodity1,commodity2; -
_all: 表示所有索引; -
commodity*:表示以 commodity 為前綴的所有索引;
-
-
{type}: 需要添加或更新的文檔類型; -
{body}:需要添加的字段或字段類型;
接下來,我們測試一下,先創建兩個未設置映射的空索引 commodity1、commodity2:
PUT http://127.0.0.1:9200/commodity1
PUT http://127.0.0.1:9200/commodity1
然后向這兩個索引同時添加映射:
PUT http://localhost:9200/commodity1,commodity2/_mapping/_doc
入參:
{
"properties": {
"commodity_id": {
"type": "long"
},
"commodity_name": {
"type": "text"
},
"picture_url": {
"type": "keyword"
}
}
}
使用 Postman 執行請求:

設置映射信息成功!
2、Elasticsearch(ES)獲取映射信息
Elasticsearch(ES)允許我們通過索引,或者是索引聯合類型來獲取映射信息:
GET http://127.0.0.1:9200/commodity/_mapping/_doc

我們還可以一次性獲取多個索引或文檔的映射信息。接口形式通常如下:
GET http://127.0.0.1:9200/{index}/_mapping/{type}
{index}和{type}均可以指定多個,中間用,分隔,另外,我們也可以使用_all表示全部索引,示例如下:
GET http://127.0.0.1:9200/_mapping/_doc1,_doc2
GET http://127.0.0.1:9200/_all/_mapping/_doc1,_doc2
第二個帶有
_all,第一個沒有,但是它們是等價的,均表示獲取全部索引。
三、更新字段映射
一些情況下,我們需要對某個索引當前類型進行更新,比如:
-
添加一個新的字段;
-
更改原有的某個字段;
-
禁用
doc_values(默認情況是開啟的); -
添加
ignore_above參數; -
...
Note:關於 ignore_above 參數,若字段長度超過指定的值,則該字段不會被索引起來,也就是說查詢不到。
接下來,為了演示,我們先刪除之前 commodity 索引,重新建立:
PUT http://127.0.0.1:9200/commdoty
入參:
{
"mappings": {
"_doc": {
"properties": {
"commodity_id": {
"type": "long"
},
"commodity_name": {
"properties": {
"first": {"type": "text"}
}
},
"picture_url": {
"type": "keyword"
}
}
}
}
}
需要注意,commodity_name 字段是一個對象數據類型(Object datatype)。
對象類型指的是,這個字段是個對象,它里面還可以存儲多個屬性字段。
接着,索引映射新建成功后,我們嘗試去更新:
PUT http://127.0.0.1:9200/commdoty/_mapping/_doc
入參:
{
"properties": {
"commodity_id": {
"type": "long"
},
"commodity_name": {
"properties": {
"last": {
"type": "text"
}
}
},
"picture_url": {
"type": "keyword",
"ignore_above": 500
}
}
}
上述請求中,我們對 commodity_name 對象數據類型增加了一個 last 屬性,並且修改了 picture_url 字段,將 ignore_above設置成了 500。

四、搜尋
1、Elasticsearch(ES)查詢指定返回細分
Elasticsearch(ES)API允許在查詢時指定返回細分,也就是僅返回部分細分。
按需索取,能夠提高Elasticsearch的響應速度。
一,僅顯示部分分段
入參格式,如下:
{
"_source": [
"commodity_id",
"commodity_name"
],
"query": {
"query_string": {
"query": "榮耀"
}
}
}
通過_source細分來指定需要返回的細分,此處我們僅顯示commodity_id,commodity_name細分。
通過HEAD插件,看下實際效果:

二,不顯示原始基線
將_source設置為false,可以不顯示原始細分,部分特殊場景下會用到。
{
"_source": false,
"query": {
"query_string": {
"query": "榮耀"
}
}
}

三,包含或排除某些長度
我們可以同時指定需要顯示的細分的,和需要排除顯示的細分:
{
"_source": {
"include": [
"commodity_id",
"commodity_name"
],
"exclude": [
"picture_url"
]
},
"query": {
"query_string": {
"query": "雙卡"
}
}
}
上面這段入參,就指定了只需要顯示commodity_id,commodity_name,排除掉picture_url。

五、ElasticSearch精通
1、Elasticsearch的特點
1)可以作為一個大型分布式集群(數百台服務器)技術,處理PB級數據,服務大公司;也可以運行在單機上,服務小公司 2)Elasticsearch不是什么新技術,主要是將全文檢索、數據分析以及分布式技術,合並在了一起,才形成了獨一無二的ES;lucene(全文檢索),商用的數據分析軟件(也是有的),分布式數據庫(mycat) 3)對用戶而言,是開箱即用的,非常簡單,作為中小型的應用,直接3分鍾部署一下ES,就可以作為生產環境的系統來使用了,數據量不大,操作不是太復雜 4)數據庫的功能面對很多領域是不夠用的(事務,還有各種聯機事務型的操作);特殊的功能,比如全文檢索,同義詞處理,相關度排名,復雜數據分析,海量數據的近實時處理;Elasticsearch作為傳統數據庫的一個補充,提供了數據庫所不能提供的很多功能
什么是搜索? 1)百度,谷歌,必應。我們可以通過他們去搜索我們需要的東西。但是我們的搜索不只是包含這些,還有京東站內搜索啊。
2)互聯網的搜索:電商網站。招聘網站。新聞網站。各種APP(百度外賣,美團等等)
3)windows系統的搜索,OA軟件,淘寶SSM網站,前后台的搜索功能
總結:搜索無處不在。通過一些關鍵字,給我們查詢出來跟這些關鍵字相關的信息 什么是全文檢索 全文檢索是指計算機索引程序通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程序就根據事先建立的索引進行查找,並將查找的結果反饋給用戶的檢索方式。這個過程類似於通過字典中的檢索字表查字的過程。
全文檢索的方法主要分為按字檢索和按詞檢索兩種。按字檢索是指對於文章中的每一個字都建立索引,檢索時將詞分解為字的組合。對於各種不同的語言而言,字有不同的含義,比如英文中字與詞實際上是合一的,而中文中字與詞有很大分別。按詞檢索指對文章中的詞,即語義單位建立索引,檢索時按詞檢索,並且可以處理同義項等。英文等西方文字由於按照空白切分詞,因此實現上與按字處理類似,添加同義處理也很容易。中文等東方文字則需要切分字詞,以達到按詞索引的目的,關於這方面的問題,是當前全文檢索技術尤其是中文全文檢索技術中的難點,在此不做詳述。 什么是倒排索引 以前是根據ID查內容,倒排索引之后是根據內容查ID,然后再拿着ID去查詢出來真正需要的東西。

image.png
什么是Lucene Lucene就是一個jar包,里面包含了各種建立倒排索引的方法,java開發的時候只需要導入這個jar包就可以開發了。Lucene的介紹及使用 典型的用空間換時間。ES 和 Lucene的區別 Lucene不是分布式的。
ES的底層就是Lucene,ES是分布式的 為什么不用數據庫去實現搜索功能? 我們用搜索“牙膏”商品為例

image.png
如果用我們平時數據庫來實現搜索的功能在性能上就很差。ES的由來 因為Lucene有兩個難以解決的問題,
1)數據越大,存不下來,那我就需要多台服務器存數據,那么我的Lucene不支持分布式的,那就需要安裝多個Lucene然后通過代碼來合並搜索結果。這樣很不好
2)數據要考慮安全性,一台服務器掛了,那么上面的數據不就消失了。
ES就是分布式的集群,每一個節點其實就是Lucene,當用戶搜索的時候,會隨機挑一台,然后這台機器自己知道數據在哪,不用我們管這些底層、

image.png
ES的優點 1.分布式的功能
2、數據高可用,集群高可用
3.API更簡單
4.API更高級。
5.支持的語言很多
6.支持PB級別的數據
7.完成搜索的功能和分析功能
基於Lucene,隱藏了Lucene的復雜性,提供簡單的API
ES的性能比HBase高,咱們的競價引擎最后還是要存到ES中的。 搜索引擎原理 反向索引又叫倒排索引,是根據文章內容中的關鍵字建立索引。 搜索引擎原理就是建立反向索引。 Elasticsearch 在 Lucene 的基礎上進行封裝,實現了分布式搜索引擎。 Elasticsearch 中的索引、類型和文檔的概念比較重要,類似於 MySQL 中的數據庫、表和行。 Elasticsearch 也是 Master-slave 架構,也實現了數據的分片和備份。 Elasticsearch 一個典型應用就是 ELK 日志分析系統。 ES的作用 1)全文檢索:
類似 select * from product where product_name like '%牙膏%'
類似百度效果(電商搜索的效果)
2)結構化搜索:
類似 select * from product where product_id = '1'
3)數據分析
類似 select count (*) from product ES的安裝 參考https://www.jianshu.com/p/198a874cc14f 直接解壓就能用(針對中小型項目),大型項目還是要調一調參數的
2.用數據庫實現搜素的功能

image.png
3.ES的核心概念
3.1 NRT(Near Realtime)近實時

image.png
3.2 cluster集群,ES是一個分布式的系統 ES直接解壓不需要配置就可以使用,在hadoop1上解壓一個ES,在hadoop2上解壓了一個ES,接下來把這兩個ES啟動起來。他們就構成了一個集群。
在ES里面默認有一個配置,clustername 默認值就是ElasticSearch,如果這個值是一樣的就屬於同一個集群,不一樣的值就是不一樣的集群。
3.3 Node節點,就是集群中的一台服務器 3.4 Index(索引-數據庫) 我們為什么使用ES?因為想把數據存進去,然后再查詢出來。
我們在使用Mysql或者Oracle的時候,為了區分數據,我們會建立不同的數據庫,庫下面還有表的。
其實ES功能就像一個關系型數據庫,在這個數據庫我們可以往里面添加數據,查詢數據。
ES中的索引非傳統索引的含義,ES中的索引是存放數據的地方,是ES中的一個概念詞匯
index類似於我們Mysql里面的一個數據庫 create database user; 好比就是一個索引庫
3.5 Type(類型-表) ES6以后一個index只能有一個type,為了提高查詢效率。
3.6 Document(文檔-行) 文檔就是最終的數據了,可以認為一個文檔就是一條記錄。
是ES里面最小的數據單元,就好比表里面的一條數據
3.7 Field(字段-列) 好比關系型數據庫中列的概念,一個document有一個或者多個field組成。
3.8 mapping(映射-約束) 數據如何存放到索引對象上,需要有一個映射配置,包括:數據類型、是否存儲、是否分詞等。
1、elasticsearch與數據庫的類比
| 關系型數據庫(比如Mysql) | 非關系型數據庫(Elasticsearch) |
|---|---|
| 數據庫Database | 索引Index |
| 表Table | 類型Type |
| 數據行Row | 文檔Document |
| 數據列Column | 字段Field |
| 約束 Schema | 映射Mapping |
3.9 shard:分片 一台服務器,無法存儲大量的數據,ES把一個index里面的數據,分為多個shard,分布式的存儲在各個服務器上面。
kafka:為什么支持分布式的功能,因為里面是有topic,支持分區的概念。所以topic A可以存在不同的節點上面。就可以支持海量數據和高並發,提升性能和吞吐量
3.10 replica:副本 一個分布式的集群,難免會有一台或者多台服務器宕機,如果我們沒有副本這個概念。就會造成我們的shard發生故障,無法提供正常服務。
我們為了保證數據的安全,我們引入了replica的概念,跟hdfs里面的概念是一個意思。
可以保證我們數據的安全。
在ES集群中,我們一模一樣的數據有多份,能正常提供查詢和插入的分片我們叫做 primary shard,其余的我們就管他們叫做 replica shard(備份的分片)
當我們去查詢數據的時候,我們數據是有備份的,它會同時發出命令讓我們有數據的機器去查詢結果,最后誰的查詢結果快,我們就要誰的數據(這個不需要我們去控制,它內部就自己控制了)
2、總結:
在默認情況下,我們創建一個庫的時候,默認會幫我們創建5個主分片(primary shrad)和5個副分片(replica shard),所以說正常情況下是有10個分片的。
同一個節點上面,副本和主分片是一定不會在一台機器上面的,就是擁有相同數據的分片,是不會在同一個節點上面的。
所以當你有一個節點的時候,這個分片是不會把副本存在這僅有的一個節點上的,當你新加入了一台節點,ES會自動的給你在新機器上創建一個之前分片的副本。

image.png
3.11 舉例
比如一首詩,有詩題、作者、朝代、字數、詩內容等字段,那么首先,我們可以建立一個名叫 Poems 的索引,然后創建一個名叫 Poem 的類型,類型是通過 Mapping 來定義每個字段的類型。
比如詩題、作者、朝代都是 Keyword 類型,詩內容是 Text 類型,而字數是 Integer 類型,最后就是把數據組織成 Json 格式存放進去了。

image.png
Keyword 類型是不會分詞的,直接根據字符串內容建立反向索引,Text 類型在存入 Elasticsearch 的時候,會先分詞,然后根據分詞后的內容建立反向索引。

image.png
4. ES集群的安裝
以后補充
5. 安裝 Kibana
https://www.jianshu.com/p/198a874cc14f
6. ES的相關命令
GET _cat/health 查看集群的健康狀況
GET _all
PUT 類似於SQL中的增
DELETE 類似於SQL中的刪
POST 類似於SQL中的改
GET 類似於SQL中的查
index的操作:
PUT /aura_index 增加一個aura_index的index庫

image.png
GET _cat/indices 命令查詢ES中所有的index索引庫

image.png
5:代表的是 primary shard的個數
DELETE /aura_index 刪除一個aura_index的index庫

image.png
7. ES的CURD操作
通過演示一個電商的例子,感受到ES的語法特點
1)插入一條商品數據

image.png
注意:我們插入數據的時候,如果我們的語句中指明了index和type,如果ES里面不存在,默認幫我們自動創建
2)查詢商品數據 使用這種語法: GET /index/type/id

image.png
3)修改商品數據
使用POST來修改數據,其實使用PUT也可以實現修改數據,原理和hbase比較像。POST的修改數據的方法在第4條中

image.png

image.png
換個方式,下面這種操作也是成功的,會丟數據,是全局的修改

image.png

image.png
4)刪除商品數據

image.png
再次插入之前的數據,發現version是5,這就說明跟hbase是類似的,不會立刻刪除,會在合適的時機進行刪除。

image.png
這次我們使用POST的方式進行修改數據,POST是局部更新數據,別的數據不動。PUT是全局更新

image.png

image.png
5)接着插入兩條數據

image.png

image.png
現在查看所有數據,類似於全表掃描

image.png
took:耗費了6毫秒
hits:獲取到的數據的情況
total:3 總的數據條數
max_score:1 所有數據里面打分最高的分數
_index:"ecommerce" index名稱
_type:"product" type的名稱
_id:"2" id號
_score:1 分數,這個分數越大越靠前出來,百度也是這樣。除非是花錢。否則匹配度越高越靠前

image.png

image.png
8.DSL語言
ES最主要是用來做搜索和分析的。所以DSL還是對於ES很重要的
下面我們寫的代碼都是RESTful風格
query DSL:domain Specialed Lanaguage 在特定領域的語言
案例:我們要進行全表掃描使用DSL語言,查詢所有的商品

image.png
使用match_all 可以查詢到所有文檔,是沒有查詢條件下的默認語句。
案例:查詢所有名稱里面包含chenyi的商品,同時按價格進行降序排序
如上圖所示,name為dior chenyi的數據會在ES中進行倒排索引分詞的操作,這樣的數據也會被查詢出來。

image.png
match查詢是一個標准查詢,不管你需要全文本查詢還是精確查詢基本上都要用到它。
下面我們按照價格進行排序:因為不屬於查詢的范圍了。所以要寫一個 逗號

image.png
這樣我們的排序就完成了
案例:實現分頁查詢
條件:根據查詢結果(包含chenyi的商品),再進行每頁展示2個商品

image.png
案例:進行全表掃面,但返回指定字段的數據
現在的情況是把所有的數據都返回了,但是我們想返回指定字段的數據內容就需要下面的方法了

image.png
案例:搜索名稱里面包含chenyi的,並且價格大於250元的商品
相當於 select * form product where name like %chenyi% and price >250;
因為有兩個查詢條件,我們就需要使用下面的查詢方式
如果需要多個查詢條件拼接在一起就需要使用bool
bool 過濾可以用來合並多個過濾條件查詢結果的布爾邏輯,它包含以下操作符:
must :: 多個查詢條件的完全匹配,相當於 and。
must_not :: 多個查詢條件的相反匹配,相當於 not。
should :: 至少有一個查詢條件匹配, 相當於 or。
這些參數可以分別繼承一個過濾條件或者一個過濾條件的數組

image.png
案例:展示一個全文檢索的效果

image.png
首先查詢條件也會進行分詞
kama
chenyi
並集
案例:不要把條件分詞,要精確匹配
但是我們現有有一種需求我就是想查詢kama chenyi不要分詞,要精確匹配到

image.png
百度就類似於這樣
案例:把查詢結果進行高亮展示

image.png
kama這個標簽是默認的標簽,是可以自定義的進行替換的,比如我們可以替換成kama,把這個輸出到網頁上,自然而然就是紅色的了。
9.聚合分析
案例:計算每個標簽tag下商品的數量
按標簽進行分組類似於 select count(*) from product group by tag;

image.png

image.png
terms 跟 term 有點類似,但 terms 允許指定多個匹配條件。 如果某個字段指定了多個值,那么文檔需要一起去做匹配
error是報錯,但是這個語句是對的,這個報錯在ES2之前是沒有的,在ES5以后才有的,在5中fielddata=true 默認是false,以前都是true
group_by_tag是個名字隨意取
所以我們需要先執行下面的代碼進行一下設置的修改:

image.png
再次執行一次

image.png
如果不想顯示具體內容,加上"size":0
案例:對商品名稱里面包含chenyi的,計算每個tag下商品的數量

image.png
案例:查詢商品名稱里面包含chenyi的數據,並且按照tag進行分組,計算每個分組下的平均價格

image.png
案例:查詢商品名稱里面包含chenyi的數據,並且按照tag進行分組,計算每個分組下的平均價格,按照平均價格進行降序排序

image.png
注意寫的位置
案例:查詢出producer里面包含producer的數據,按照指定的價格區間進行分組,在每個組內再按tag進行分組,分完組以后再求每個組的平均價格,並且按照降序進行排序
range過濾允許我們按照指定范圍查找一批數據

image.png

image.png
10、Elasticsearch對復雜分布式機制的透明隱藏特性
1)Elasticsearch是一套分布式系統,分布式是為了應對大數據量,隱藏了復雜的分布式機制
分片機制(我們之前隨隨便便就將一些document插入到es集群中,我們沒有關心過數據是怎么進行分片的,數據到哪個shard中去)
cluster discovery(集群發現機制,我們之前做集群status從yellow轉green,直接啟動第二個es進程,那個進程直接作為一個node自動就發現了集群,並且加入了進去,還接受了部分數據,replica shard)
shard負載均衡(假設現在有3個node,總共有25個shard要分配到3個節點上去,es會自動進行均勻分配,以保持每個節點的均衡的讀寫負載請求)
shard副本`,`請求路由`,`集群擴容`,`shard重分配
2)Elasticsearch的垂直擴容與水平擴容
垂直擴容:采購更強大的服務器,成本高昂,會有瓶頸
水平擴容:業界經常采用的方式,采購越來越多的普通服務器,性能比較一般,但是很多普通服務器組織在一起,就能構成強大的計算和存儲能力。
3)增加或減少節點時的數據rebalance: 比如現在有3個節點,4個shard。這樣肯定有一台節點上存儲2個shard,總會有那么一台節點負荷重一點,當增加一個節點時,es集群會自動把有2個shard的節點分出一個shard給新增加的節點,保持負載均衡。
4)master節點 管理es集群的元數據:比如創建或刪除index,維護索引元數據,節點的增加和刪除,維護集群的元數據。
默認情況下,會自動選擇出一台節點,作為master節點。
master節點不承載所有的請求,所以不會是一個單點瓶頸。
5)節點對等的分布式架構 節點對等,每個節點都能接收所有的請求
自動請求路由(如果請求要找的數據不在這台節點上,這個節點會自動把請求路由到數據所在的節點)
響應收集(數據所在節點會接收到其他節點發送的請求,並且響應回client)
11、shard&replica機制梳理
(1)index包含多個shard (2)每個shard都是一個最小工作單元,承載部分數據,lucene實例,完整的建立索引和處理請求的能力 (3)增減節點時,shard會自動在nodes中負載均衡 (4)primary shard和replica shard,每個document肯定只存在於某一個primary shard以及其對應的replica shard中,不可能存在於多個primary shard (5)replica shard是primary shard的副本,負責容錯,以及承擔讀請求負載 (6)primary shard的數量在創建索引的時候就固定了,replica shard數量可以隨時修改 (7)primary shard的默認數量是5,replica默認是1,默認有10個shard,5個primary shard,5個replica shard (8)primary shard不能和自己的replica shard放在同一個節點上(否則節點宕機,primary shard和副本全部丟失,起不到容錯作用),但是可以和其他primary shard的replica shard放在同一個節點
12、單node環境下創建index是什么樣子
(1)單node環境下,創建一個index,有3個primary shard,3個replica shard (2)集群status是yellow (3)這個時候,只會將3個primary shard分配到僅有的一台node上去,另外3個replica shard無法分配 (4)集群可以正常工作,但是一旦出現節點宕機,數據全部丟失,而且集群不可用,無法承載任何請求
PUT /test_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
第三章、ElasticSearch面試
1、es 讀數據過程
可以通過 doc id 來查詢,會根據 doc id 進行 hash,判斷出來當時把 doc id 分配到了哪個 shard 上面去,從那個 shard 去查詢。
-
客戶端發送請求到任意一個 node,成為
coordinate node。 -
coordinate node對doc id進行哈希路由,將請求轉發到對應的 node,此時會使用round-robin隨機輪詢算法,在primary shard以及其所有 replica 中隨機選擇一個,讓讀請求負載均衡。 -
接收請求的 node 返回 document 給
coordinate node。 -
coordinate node返回 document 給客戶端。
-
es 讀數據過程
可以通過
doc id來查詢,會根據doc id進行 hash,判斷出來當時把doc id分配到了哪個 shard 上面去,從那個 shard 去查詢。-
客戶端發送請求到任意一個 node,成為
coordinate node。 -
coordinate node對doc id進行哈希路由,將請求轉發到對應的 node,此時會使用round-robin隨機輪詢算法,在primary shard以及其所有 replica 中隨機選擇一個,讓讀請求負載均衡。 -
接收請求的 node 返回 document 給
coordinate node。 -
coordinate node返回 document 給客戶端。
寫請求是寫入 primary shard,然后同步給所有的 replica shard;讀請求可以從 primary shard 或 replica shard 讀取,采用的是隨機輪詢算法
-
2、寫數據底層原理
1)document先寫入導內存buffer中,同時寫translog日志
2))近實時搜索
隨着按段(per-segment)搜索的發展,一個新的文檔從索引到可被搜索的迭代顯着降低了。新文檔在幾分鍾之內即可被檢索,但這樣還是不夠快。
磁盤在這里成為了瓶頸提交(Commiting)一個新的段到磁盤需要一個。 fsync來確保段被物理性地寫入磁盤,這樣在斷電的時候就不會丟失數據但是。fsync操作代價很大; 如果每次索引一個文檔都去執行一次的話會造成很大的性能問題。
我們需要的是一個更輕量的方式來使一個文檔可被搜索,這意味着fsync要從整個過程中被刪除。
之前描述的一樣,在內存索引索引(圖19,“在內存磁盤中包含了新文檔的Lucene索引”)中的文檔會被寫入到一個新的段中(圖20,“快照的內容已經被寫入一個可被搜索的段中,但還沒有進行進行”)。但是這里新段會被先寫入到文件系統緩存—此步代價會比較低,稍后再被刷新到磁盤—這一步代價比較高。不過只要文件已經在緩存中,就可以像其他文件一樣被打開和讀取了。

圖19.在內存緩沖區中包含了新文檔的Lucene索引
Lucene允許新段被寫入和打開—-包含的文檔在未進行一次完整提交時便對搜索可見。這種方式比進行一次提交代價要小得多,並且在不影響性能的方面下可以被過多地執行。

圖20.犯罪的內容已經被寫入一個可被搜索的段中,但還沒有進行進行提交
刷新API
在Elasticsearch中,寫入和打開一個新段的輕量的過程叫做刷新默認情況下每個分片會每秒自動刷新一次這就是為什么我們說Elasticsearch是。近實時搜索:文檔的變化並不是立即對搜索可見,但會在一秒鍾之內可以看到。
這些行為可能導致新用戶造成混亂:他們索引了一個文檔然后嘗試搜索它,卻沒有搜到。這個問題的解決方法是用refreshAPI執行一次手動刷新:
開機自檢/ _刷新
POST / 博客/ _refresh
| 刷新(Refresh)所有的索引。 | |
|---|---|
只刷新(Refresh)blogs索引。 |
盡管刷新是比提交輕量很多的操作,它還是會有性能消耗。當寫測試的時候,手動刷新很有用,但是不要在生產環境下每次索引一個文檔都去手動刷新。相反,你的應用需要考慮Elasticsearch的近實時的性質,並接受它的不足。
並非所有情況下都需要重新刷新。可能您正在使用Elasticsearch索引大量的日志文件,您可能想優化索引速度而不是近實時搜索,可以通過設置refresh_interval,減少每個索引的刷新頻率:
PUT / my_logs
{ “ settings” :{ “ refresh_interval” :“ 30s”
} }
每30秒刷新my_logs索引。 |
|
|---|---|
refresh_interval 在生產環境中,當您正在建立一個大的新索引時,可以先關閉自動刷新,待開始使用該索引時,再把它們調回來:可以在既存索引上進行動態更新。
PUT / my_logs / _settings
{ “ refresh_interval” :- 1 }
PUT / my_logs / _settings
{ “ refresh_interval” :“ 1s” }
| 關閉自動刷新。 | |
|---|---|
| 每秒自動刷新。 |
refresh_interval需要一個持續時間值,例如1s(1秒)或2m(2分鍾)。一個絕對值1表示的是1毫秒 -完全可能會使您陷入癱瘓。
refresh操作所以近實時搜索:寫入和打開一個新段(一個追加的倒排索引)的輕量的過程叫做 *refresh* 。每隔一秒鍾把buffer中的數據創建一個新的segment,這里新段會被先寫入到文件系統緩存--這一步代價會比較低,稍后再被刷新到磁盤--這一步代價比較高。不過只要文件已經在緩存中, 就可以像其它文件一樣被打開和讀取了,內存buffer被清空。此時,新segment 中的文件就可以被搜索了,這就意味着document從被寫入到可以被搜索需要一秒種,如果要更改這個屬性,可以執行以下操作
PUT /my_index { "settings": { "refresh_interval": "30s" } } 3)持久化變化
如果沒有用fsync把數據從文件系統緩存刷到(刷新)到硬盤,我們不能保證數據在斷電甚至是程序正常退出之后依然存在。為了保證Elasticsearch的可靠性,需要確保數據變化被持久化到磁盤。
在動態更新索引,我們說一次完整的提交提交段刷到磁盤,並寫入一個包含所有段列表的提交點。Elasticsearch在啟動或重新打開一個索引的過程中使用這個提交點來估計其中段所屬屬於當前分片。
即使通過每秒刷新(refresh)實現了近實時搜索,我們仍然需要經常進行完整提交來確保能從失敗中恢復。但在兩次提交之間發生變化的文檔怎么辦?我們也不希望丟失掉這些數據。
Elasticsearch增加了一個translog,或者每一次對Elasticsearch進行操作時均進行了日志記錄。通過translog,整個流程看起來是下面這樣:
-
一個文檔被索引之后,就會被添加到內存緩沖區,並且追加到了超越對,正如圖21中的“新的文檔被添加到內存緩沖區並且被追加到了事務日志”描述的一樣。

圖21.新的文檔被添加到內存堆棧和被追加到了事務日志
-
刷新(refresh)使分片位於圖22中,“刷新(refresh)完成后,緩存被清空但事務日志不會”描述的狀態,分片每秒被刷新(refresh)一次:
-
這些在內存正極的文檔被寫入到一個新的段中,且沒有進行
fsync操作。 -
這個段被打開,有助於可被搜索。
-
內存正極被清空。

圖22.刷新(刷新)完成后,緩存被清空但事務日志不會
-
-
這個進程繼續工作,更多的文檔被添加到內存副本和追加到事務日志(參見圖23,“事務日志不斷積累文檔”)。

圖23.事務日志不斷積累文檔
-
每隔間隔—例如Translog變得越來越大—索引被刷新(Flush);一個新的Translog被創建,並且一個全量提交被執行(參見圖24,“在刷新(Flush)之后,段”被全量提交,和事務日志被清空”):
-
所有在內存容量的文檔都被寫入一個新的段。
-
上方被清空。
-
一個提交點被寫入硬盤。
-
文件系統緩存通過
fsync被刷新(flush)。 -
老的translog被刪除。
-
當Elasticsearch啟動的時候,它會從磁盤中使用最后一個提交點去恢復已知的段,並且會重新連接translog中所有在最后一次提交后發生的變更操作。
當您試着通過ID查詢,更新,刪除一個文檔,它會在嘗試從相應的段中檢索之前,首先檢查translog任何最近的變更。這意味着它總是能夠實時地獲取到文檔的最新版本。

圖24.在刷新(flush)之后,段被全量提交,並且事務日志被清空
沖洗API
這個執行一個提交並且截斷超越對的行為在Elasticsearch被稱作一次沖洗。分片每30分鍾被自動刷新(刷新),或者在超越對太大的時候也會刷新。查看請 translog文檔來設置,它可以用來控制這些閾值:
flushAPI可以被用來執行一個手工的刷新(flush):
POST / 博客/ _flush
POST / _flush ?wait_for_ongoing
刷新(flush)blogs索引。 |
|
|---|---|
| 刷新(flush)所有的索引和並等待所有刷新在返回前完成。 |
你很少需要自己手動執行flush操作;通常情況下,自動刷新就足夠了。
這就是說,在重啟節點或關閉索引之前執行沖洗有益於你的索引。當Elasticsearch嘗試恢復或重新打開一個索引,它需要重放超越對中所有的操作,所以如果日志越短,恢復越快。
Translog是否有多安全性?
translog的目的是保證操作不會丟失。這引出了這個問題:Translog有多安全?
文件在被fsync到磁盤前,被寫入的文件在重啟之后就會丟失。默認超越對是每5被秒fsync刷新到硬盤,或者在每次寫請求完成之后執行(例如索引,刪除,更新,散裝)。最終,基本上,這意味着在整個請求被fsync到主分片和復制分片的translog之前,您的客戶端不會得到一個200 OK響應。
在每次請求后都執行一個fsync會帶來一些性能損失,雖然實踐表明這種損耗相對較小(特別是批量導入,它在一次請求中平攤減小文檔的體積)。
但是對於某些大容量的偶爾丟失幾秒數據問題也不會嚴重的損壞,使用異步的fsync還是比較有益的。例如,寫入的數據被緩存到內存中,再每5秒執行一次fsync。
這個行為可以通過設置durability參數為async來啟用:
PUT / my_index / _settings
{ “ index.translog.durability” :“異步” ,“ index.translog.sync_interval” :“ 5s” }
這個選項可以針對索引單獨設置,並且可以動態進行修改。如果你決定使用異步translog的話,你需要保證在發生崩潰時,丟失掉sync_interval時間段的數據也無所謂。請在決定前知道這個特性。
如果您不確定這個行為的后果,最好是使用替代的參數("index.translog.durability": "request")來避免數據丟失。
flush操作導致持久化變更:執行一個提交並且截斷 translog 的行為在 Elasticsearch 被稱作一次 *flush。*刷新(refresh)完成后, 緩存被清空但是事務日志不會。translog日志也會越來越多,當translog日志大小大於一個閥值時候或30分鍾,會出發flush操作。
-
所有在內存緩沖區的文檔都被寫入一個新的段。
-
緩沖區被清空。
-
一個提交點被寫入硬盤。(表明有哪些segment commit了)
-
文件系統緩存通過
fsync到磁盤。 -
老的 translog 被刪除。
分片每30分鍾被自動刷新(flush),或者在 translog 太大的時候也會刷新。也可以用_flush命令手動執行。
translog每隔5秒會被寫入磁盤(所以如果這5s,數據在cache而且log沒持久化會丟失)。在一次增刪改操作之后translog只有在replica和primary shard都成功才會成功,如果要提高操作速度,可以設置成異步的
PUT /my_index { "settings": { "index.translog.durability": "async" ,
"index.translog.sync_interval":"5s" } }
所以總結是有三個批次操作,一秒做一次refresh保證近實時搜索,5秒做一次translog持久化保證數據未持久化前留底,30分鍾做一次數據持久化。
2.基於translog和commit point的數據恢復
在磁盤上會有一個上次持久化的commit point,translog上有一個commit point,根據這兩個commit point,會把translog中的變更記錄進行回放,重新執行之前的操作
3.不變形下的刪除和更新原理
動態更新索引
下一個需要被解決的問題是怎樣在保留不變性的預定下實現倒排索引的更新?答案是:用更多的索引。
通過增加新的補充索引來反映新近的修改,而不是直接重新轉換整個倒排索引。每一個倒排索引都會被輪流查詢到—從最初的開始—查詢完成后再對結果進行合並。
Elasticsearch基於Lucene的,這個java的引入庫了按段搜索的概念每一。段本身都是一個倒排索引,但索引在Lucene的除中表示所有段的集合外,增加還了提交點的概念-一個列出了所有已知段的文件,就像在圖16中,“一個Lucene索引包含一個提交點和三個段”中替換的那樣。如圖17,“一個在內存緩存中包含新文檔的Lucene索引”所示,新的文檔首先被添加到內存索引緩存中,然后寫入到一個基於磁盤的段,如圖18中,“在一次提交后,一個新的段被添加到提交點而且緩存被清空。”所示。

圖16.一個Lucene索引包含一個提交點和三個段
索引與分片的比較
被混淆的概念是,一個Lucene的索引我們在Elasticsearch稱作分片。一個Elasticsearch 索引的英文分片的集合。當Elasticsearch在索引中搜索的時候,他發送查詢到每一個屬於索引的分片(Lucene的索引) ,,然后像執行分布式檢索 提到的那樣,合並每個分片的結果到一個上下的結果集。
逐段搜索會以如下流程進行工作:
-
新文檔被收集到內存索引緩存,請參見圖17,“一個在內存緩存中包含新文檔的Lucene索引”。
-
不時地,緩存被提交:
-
一個新的段—一個追加的倒排索引—被寫入磁盤。
-
一個新的包含新段名字的提交點被寫入磁盤。
-
磁盤進行同步 —所有在文件系統緩存中等待的寫入都刷新到磁盤,以確保其被寫入物理文件。
-
-
新的段被開啟,讓它包含的文檔可見以被搜索。
-
內存緩存被清空,等待接收新的文檔。

圖17.一個在內存緩存中包含新文檔的Lucene索引

圖18.在一次提交后,一個新的段被添加到提交點而且緩存被清空。
當一個查詢被觸發,所有已知的段按順序被查詢。詞項統計計量所有段的結果進行聚合,以保證每個詞和每個文檔的關聯都被准確計算。這種方式可以用相對最高的成本將新文檔添加到索引。
刪除和更新
段是不可改變的,所以既不能從把文檔從舊的段中刪除,也不能修改舊的段來進行反映文檔的更新。取而代之的是,每個提交點會包含一個.del文件,文件中會列出這些被刪除文檔的段信息。
當一個文檔被“刪除”時,它實際上只是在.del文件中被標記刪除。一個被標記刪除的文檔仍然可以被查詢匹配到,但它會在最終結果被返回前從結果集中移除。
文檔更新也是類似的操作方式:當一個文檔被更新時,舊版本文檔被標記刪除,文檔的新版本被索引到一個新的段中。可能兩個版本的文檔都會被一個查詢匹配到,但被刪除的那個舊版本文檔在結果集返回前就已經被刪除。
在段合並,我們展示了一個被刪除的文檔是怎樣被文件系統移除的。
一個文檔被 “刪除” 時,它實際上只是在 .del 文件中被 標記 刪除。一個被標記刪除的文檔仍然可以被查詢匹配到, 但它會在最終結果被返回前從結果集中移除。
文檔更新也是類似的操作方式:當一個文檔被更新時,舊版本文檔被標記刪除,文檔的新版本被索引到一個新的段中。 可能兩個版本的文檔都會被一個查詢匹配到,但被刪除的那個舊版本文檔在結果集返回前就已經被移除。
段合並的時候會將那些舊的已刪除文檔 從文件系統中清除。 被刪除的文檔(或被更新文檔的舊版本)不會被拷貝到新的大段中。
4.merge操作,段合並
由於自動刷新流程每秒會創建一個新的段,這樣會導致短時間內的段數量暴增。而段多個會會帶來干擾的麻煩。每一個段都會消耗文件句柄,內存和cpu運行周期。更重要的是,每個搜索請求都必須輪流檢查每個段;所以段越多,搜索也就越慢。
Elasticsearch通過在后台進行段合並來解決這個問題。小的段被合並到大的段,然后這些大的段再被合並到更大的段。
段合並的當時重置那些舊的已刪除文檔從文件系統中清除。被刪除的文檔(或被更新文檔的舊版本)不會被復制到新的大段中。
這個流程像在圖25中,“兩個提交了的段和一個未提交的段正在被合並到一個更大的段”中提到的一樣工作:
1,當索引的時候,刷新(refresh)操作會創建新的段轉換段打開以供搜索使用。
2,合並進程選擇一小部分大小相似的段,並且在后台將其合並到高層的段中。這並不會中斷索引和搜索。

圖25.兩個提交了的段和一個未提交的段正在被合並到一個更大的段
3,圖26,“一旦合並結束,老的段被刪除”說明合並完成時的活動:
-
**寫入一個包含新段且排除了舊的和較小的段的新提交點。
-
新的段被打開進行搜索。
-
老的段被刪除。

圖26.一旦合並結束,老的段被刪除
合並大的段需要消耗大量的I / O和CPU資源,如果任其發展會影響搜索性能。Elasticsearch在各種情況下下整合合並流程進行資源限制,因此搜索仍然有足夠的資源很好地執行。
查看段和合並來為你的實例獲取關於合並調整的建議。
優化API
optimizeAPI大可看做是強制合並的 API。它可以將一個分片強制合並到max_num_segments參數指定大小的段數。這實際上是減少段的數量(通常減少到一個),來提升搜索性能。
optimizeAPI 不應該被用在一個活躍的索引————一個正積極更新的索引。后台合並流程已經可以很好地完成工作。
在特定情況下,使用optimizeAPI相當有分量。例如在日志這種用例下,每天,每周,每月的日志被存儲在一個索引中。可能會發生變化。
在這種情況下,使用optimize優化老的索引,將每一個分片合並為一個單獨的段就很有用了;這樣既可以節省資源,也可以使搜索更加快速:
POST / logstash - 2014 - 10 / _optimize ?max_num_segments = 1
| 合並索引中的每個分片為一個單獨的段 | |
|---|---|
請注意,使用optimizeAPI觸發段合並的操作不會受到任何資源上的限制。這可能會消耗掉你例程上全部的I / O資源,從而沒有余裕來處理搜索請求,從而有可能使丟失的響應。如果您想要對索引執行optimize,您需要先使用分片分配(查看遷移舊索引)把索引移到一個安全的中斷,再執行。
由於每秒會把buffer刷到segment中,所以segment會很多,為了防止這種情況出現,es內部會不斷把一些相似大小的segment合並,並且物理刪除del的segment。
當然也可以手動執行
POST /my_index/_optimize?max_num_segments=1,盡量不要手動執行,讓它自動默認執行就可以了
5.當你正在建立一個大的新索引時(相當於直接全部寫入buffer,先不refresh,寫完再refresh),可以先關閉自動刷新,待開始使用該索引時,再把它們調回來:
PUT /my_logs/_settings
{ "refresh_interval": -1 }
PUT /my_logs/_settings
{ "refresh_interval": "1s" }
底層 lucene
簡單來說,lucene 就是一個 jar 包,里面包含了封裝好的各種建立倒排索引的算法代碼。我們用 Java 開發的時候,引入 lucene jar,然后基於 lucene 的 api 去開發就可以了。
通過 lucene,我們可以將已有的數據建立索引,lucene 會在本地磁盤上面,給我們組織索引的數據結構。
倒排索引
在搜索引擎中,每個文檔都有一個對應的文檔 ID,文檔內容被表示為一系列關鍵詞的集合。例如,文檔 1 經過分詞,提取了 20 個關鍵詞,每個關鍵詞都會記錄它在文檔中出現的次數和出現位置。
詳細描述一下Elasticsearch索引文檔的過程。
-
協調節點默認使用文檔ID參與計算(也支持通過routing),以便為路由提供合適的分片
shard = hash(document_id) % (num_of_primary_shards)當分片所在的節點接收到來自協調節點的請求后,會將請求寫入到Memory Buffer,然后定時(默認是每隔1秒)寫入到Filesystem Cache,這個從Momery Buffer到Filesystem Cache的過程就叫做refresh; 當然在某些情況下,存在Momery Buffer和Filesystem Cache的數據可能會丟失,ES是通過translog的機制來保證數據的可靠性的。其實現機制是接收到請求后,同時也會寫入到translog中,當Filesystem cache中的數據寫入到磁盤中時,才會清除掉,這個過程叫做flush; 在flush過程中,內存中的緩沖將被清除,內容被寫入一個新段,段的fsync將創建一個新的提交點,並將內容刷新到磁盤,舊的translog將被刪除並開始一個新的translog。 flush觸發的時機是定時觸發(默認30分鍾)或者translog變得太大(默認為512M)時;
7.Elasticsearch在部署時,對Linux的設置有哪些優化方法?
64 GB 內存的機器是非常理想的, 但是32 GB 和16 GB 機器也是很常見的。少於8 GB 會適得其反。
如果你要在更快的 CPUs 和更多的核心之間選擇,選擇更多的核心更好。多個內核提供的額外並發遠勝過稍微快一點點的時鍾頻率。
如果你負擔得起 SSD,它將遠遠超出任何旋轉介質。 基於 SSD 的節點,查詢和索引性能都有提升。如果你負擔得起,SSD 是一個好的選擇。
即使數據中心們近在咫尺,也要避免集群跨越多個數據中心。絕對要避免集群跨越大的地理距離。
請確保運行你應用程序的 JVM 和服務器的 JVM 是完全一樣的。 在 Elasticsearch 的幾個地方,使用 Java 的本地序列化。
通過設置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重啟的時候避免過多的分片交換,這可能會讓數據恢復從數個小時縮短為幾秒鍾。
Elasticsearch 默認被配置為使用單播發現,以防止節點無意中加入集群。只有在同一台機器上運行的節點才會自動組成集群。最好使用單播代替組播。
不要隨意修改垃圾回收器(CMS)和各個線程池的大小。
把你的內存的(少於)一半給 Lucene(但不要超過 32 GB!),通過ES_HEAP_SIZE 環境變量設置。
內存交換到磁盤對服務器性能來說是致命的。如果內存交換到磁盤上,一個 100 微秒的操作可能變成 10 毫秒。 再想想那么多 10 微秒的操作時延累加起來。 不難看出 swapping 對於性能是多么可怕。
Lucene 使用了大量的文件。同時,Elasticsearch 在節點和 HTTP 客戶端之間進行通信也使用了大量的套接字。 所有這一切都需要足夠的文件描述符。你應該增加你的文件描述符,設置一個很大的值,如 64,000。
1、elasticsearch了解多少,說說你們公司es的集群架構,索引數據大小,分片有多少,以及一些調優手段 。
面試官:想了解應聘者之前公司接觸的ES使用場景、規模,有沒有做過比較大規模的索引設計、規划、調優。
解答:
如實結合自己的實踐場景回答即可。
比如:ES集群架構13個節點,索引根據通道不同共20+索引,根據日期,每日遞增20+,索引:10分片,每日遞增1億+數據,
每個通道每天索引大小控制:150GB之內。
僅索引層面調優手段:
1.1、設計階段調優
1)根據業務增量需求,采取基於日期模板創建索引,通過roll over API滾動索引;
2)使用別名進行索引管理;
3)每天凌晨定時對索引做force_merge操作,以釋放空間;
4)采取冷熱分離機制,熱數據存儲到SSD,提高檢索效率;冷數據定期進行shrink操作,以縮減存儲;
5)采取curator進行索引的生命周期管理;
6)僅針對需要分詞的字段,合理的設置分詞器;
7)Mapping階段充分結合各個字段的屬性,是否需要檢索、是否需要存儲等。 …
1.2、寫入調優
1)寫入前副本數設置為0;
2)寫入前關閉refresh_interval設置為-1,禁用刷新機制;
3)寫入過程中:采取bulk批量寫入;
4)寫入后恢復副本數和刷新間隔;
5)盡量使用自動生成的id。
1.3、查詢調優
1)禁用wildcard;
2)禁用批量terms(成百上千的場景);
3)充分利用倒排索引機制,能keyword類型盡量keyword;
4)數據量大時候,可以先基於時間敲定索引再檢索;
5)設置合理的路由機制。
1.4、其他調優
部署調優,業務調優等。
上面的提及一部分,面試者就基本對你之前的實踐或者運維經驗有所評估了。
2、elasticsearch的倒排索引是什么?
面試官:想了解你對基礎概念的認知。
解答:通俗解釋一下就可以。
傳統的我們的檢索是通過文章,逐個遍歷找到對應關鍵詞的位置。
而倒排索引,是通過分詞策略,形成了詞和文章的映射關系表,這種詞典+映射表即為倒排索引。
有了倒排索引,就能實現o(1)時間復雜度的效率檢索文章了,極大的提高了檢索效率。
學術的解答方式:
倒排索引,相反於一篇文章包含了哪些詞,它從詞出發,記載了這個詞在哪些文檔中出現過,由兩部分組成——詞典和倒排表。
加分項:倒排索引的底層實現是基於:FST(Finite State Transducer)數據結構。
lucene從4+版本后開始大量使用的數據結構是FST。FST有兩個優點:
1)空間占用小。通過對詞典中單詞前綴和后綴的重復利用,壓縮了存儲空間;
2)查詢速度快。O(len(str))的查詢時間復雜度。
3、elasticsearch 索引數據多了怎么辦,如何調優,部署?
面試官:想了解大數據量的運維能力。
解答:索引數據的規划,應在前期做好規划,正所謂“設計先行,編碼在后”,這樣才能有效的避免突如其來的數據激增導致集群處理能力不足引發的線上客戶檢索或者其他業務受到影響。
如何調優,正如問題1所說,這里細化一下:
3.1 動態索引層面
基於模板+時間+rollover api滾動創建索引,舉例:設計階段定義:blog索引的模板格式為:blog_index_時間戳的形式,每天遞增數據。
這樣做的好處:不至於數據量激增導致單個索引數據量非常大,接近於上線2的32次冪-1,索引存儲達到了TB+甚至更大。
一旦單個索引很大,存儲等各種風險也隨之而來,所以要提前考慮+及早避免。
3.2 存儲層面
冷熱數據分離存儲,熱數據(比如最近3天或者一周的數據),其余為冷數據。
對於冷數據不會再寫入新數據,可以考慮定期force_merge加shrink壓縮操作,節省存儲空間和檢索效率。
3.3 部署層面
一旦之前沒有規划,這里就屬於應急策略。
結合ES自身的支持動態擴展的特點,動態新增機器的方式可以緩解集群壓力,注意:如果之前主節點等規划合理,不需要重啟集群也能完成動態新增的。
4、elasticsearch是如何實現master選舉的?
面試官:想了解ES集群的底層原理,不再只關注業務層面了。
解答:
前置前提:
1)只有候選主節點(master:true)的節點才能成為主節點。
2)最小主節點數(min_master_nodes)的目的是防止腦裂。
這個我看了各種網上分析的版本和源碼分析的書籍,雲里霧里。
核對了一下代碼,核心入口為findMaster,選擇主節點成功返回對應Master,否則返回null。選舉流程大致描述如下:
第一步:確認候選主節點數達標,elasticsearch.yml設置的值discovery.zen.minimum_master_nodes;
第二步:比較:先判定是否具備master資格,具備候選主節點資格的優先返回;若兩節點都為候選主節點,則id小的值會主節點。注意這里的id為string類型。
題外話:獲取節點id的方法。
1、GET /_cat/nodes?v&h=ip,port,heapPercent,heapMax,id,name
2、ip port heapPercent heapMax id name
3、127.0.0.1 9300 39 1.9gb Hk9w Hk9wFwU
5、詳細描述一下Elasticsearch索引文檔的過程?
面試官:想了解ES的底層原理,不再只關注業務層面了。
解答:
這里的索引文檔應該理解為文檔寫入ES,創建索引的過程。
文檔寫入包含:單文檔寫入和批量bulk寫入,這里只解釋一下:單文檔寫入流程。
記住官方文檔中的這個圖。
第一步:客戶寫集群某節點寫入數據,發送請求。(如果沒有指定路由/協調節點,請求的節點扮演路由節點的角色。)
第二步:節點1接受到請求后,使用文檔_id來確定文檔屬於分片0。請求會被轉到另外的節點,假定節點3。因此分片0的主分片分配到節點3上。
第三步:節點3在主分片上執行寫操作,如果成功,則將請求並行轉發到節點1和節點2的副本分片上,等待結果返回。所有的副本分片都報告成功,節點3將向協調節點(節點1)報告成功,節點1向請求客戶端報告寫入成功。
如果面試官再問:第二步中的文檔獲取分片的過程?
回答:借助路由算法獲取,路由算法就是根據路由和文檔id計算目標的分片id的過程。
shard = hash(_routing) % (num_of_primary_shards)
6、詳細描述一下Elasticsearch搜索的過程?
面試官:想了解ES搜索的底層原理,不再只關注業務層面了。
解答:
搜索拆解為“query then fetch” 兩個階段。
query階段的目的:定位到位置,但不取。
步驟拆解如下:
1)假設一個索引數據有5主+1副本 共10分片,一次請求會命中(主或者副本分片中)的一個。
2)每個分片在本地進行查詢,結果返回到本地有序的優先隊列中。
3)第2)步驟的結果發送到協調節點,協調節點產生一個全局的排序列表。
fetch階段的目的:取數據。
路由節點獲取所有文檔,返回給客戶端。
7、Elasticsearch在部署時,對Linux的設置有哪些優化方法?
面試官:想了解對ES集群的運維能力。
解答:
1)關閉緩存swap;
2)堆內存設置為:Min(節點內存/2, 32GB);
3)設置最大文件句柄數;
4)線程池+隊列大小根據業務需要做調整;
5)磁盤存儲raid方式——存儲有條件使用RAID10,增加單節點性能以及避免單節點存儲故障。
8、lucence內部結構是什么?
面試官:想了解你的知識面的廣度和深度。
解答: