
前言
前一篇「硬不硬你說了算!近 40 張圖解被問千百遍的 TCP 三次握手和四次揮手面試題」得到了很多讀者的認可,在此特別感謝你們的認可,大家都暖暖的。

來了,今天又來圖解 TCP 了,小林可能會遲到,但不會缺席。
遲到的原因,主要是 TCP 巨復雜,它為了保證可靠性,用了巨多的機制來保證,真是個「偉大」的協議,寫着寫着發現這水太深了。。。
本文的全部圖片都是小林繪畫的,非常的辛苦且累,不廢話了,直接進入正文,Go!
正文
相信大家都知道 TCP 是一個可靠傳輸的協議,那它是如何保證可靠的呢?
為了實現可靠性傳輸,需要考慮很多事情,例如數據的破壞、丟包、重復以及分片順序混亂等問題。如不能解決這些問題,也就無從談起可靠傳輸。
那么,TCP 是通過序列號、確認應答、重發控制、連接管理以及窗口控制等機制實現可靠性傳輸的。
今天,將重點介紹 TCP 的重傳機制、滑動窗口、流量控制、擁塞控制。
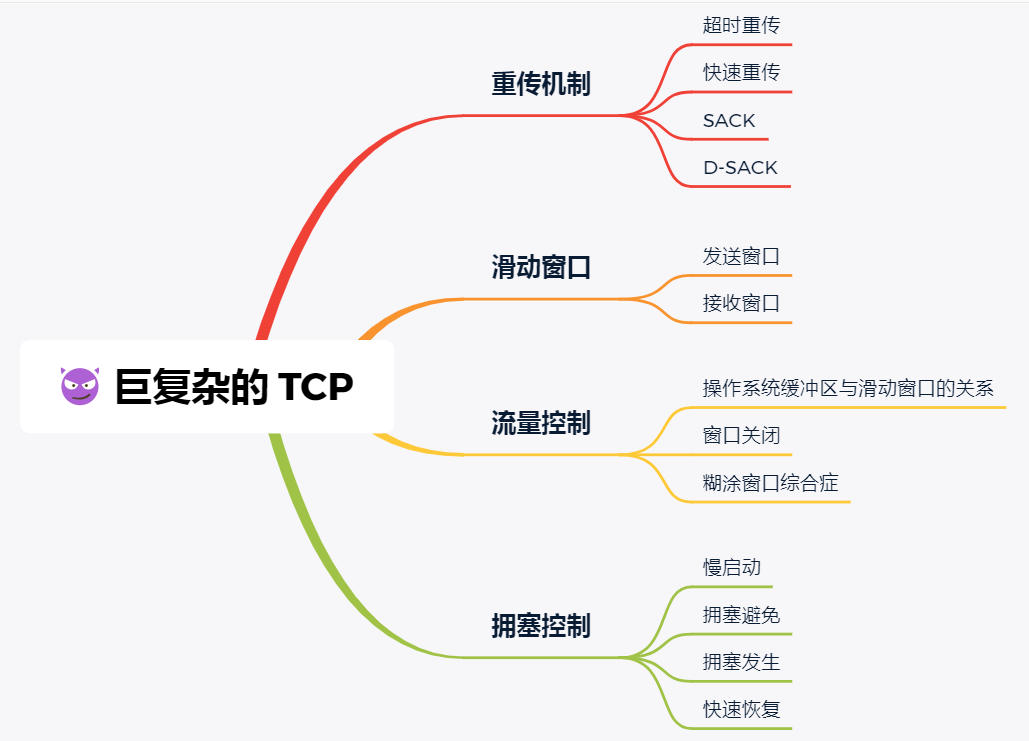
重傳機制
TCP 實現可靠傳輸的方式之一,是通過序列號與確認應答。
在 TCP 中,當發送端的數據到達接收主機時,接收端主機會返回一個確認應答消息,表示已收到消息。
 正常的數據傳輸
正常的數據傳輸
但在錯綜復雜的網絡,並不一定能如上圖那么順利能正常的數據傳輸,萬一數據在傳輸過程中丟失了呢?
所以 TCP 針對數據包丟失的情況,會用重傳機制解決。
接下來說說常見的重傳機制:
- 超時重傳
- 快速重傳
- SACK
- D-SACK
超時重傳
重傳機制的其中一個方式,就是在發送數據時,設定一個定時器,當超過指定的時間后,沒有收到對方的 ACK 確認應答報文,就會重發該數據,也就是我們常說的超時重傳。
TCP 會在以下兩種情況發生超時重傳:
- 數據包丟失
- 確認應答丟失
 超時重傳的兩種情況
超時重傳的兩種情況
超時時間應該設置為多少呢?
我們先來了解一下什么是 RTT(Round-Trip Time 往返時延),從下圖我們就可以知道:
 RTT
RTT
RTT 就是數據從網絡一端傳送到另一端所需的時間,也就是包的往返時間。
超時重傳時間是以 RTO (Retransmission Timeout 超時重傳時間)表示。
假設在重傳的情況下,超時時間 RTO 「較長或較短」時,會發生什么事情呢?
 超時時間較長與較短
超時時間較長與較短
上圖中有兩種超時時間不同的情況:
- 當超時時間 RTO 較大時,重發就慢,丟了老半天才重發,沒有效率,性能差;
- 當超時時間 RTO 較小時,會導致可能並沒有丟就重發,於是重發的就快,會增加網絡擁塞,導致更多的超時,更多的超時導致更多的重發。
精確的測量超時時間 RTO 的值是非常重要的,這可讓我們的重傳機制更高效。
根據上述的兩種情況,我們可以得知,超時重傳時間 RTO 的值應該略大於報文往返 RTT 的值。
 RTO 應略大於 RTT
RTO 應略大於 RTT
至此,可能大家覺得超時重傳時間 RTO 的值計算,也不是很復雜嘛。
好像就是在發送端發包時記下 t0 ,然后接收端再把這個 ack 回來時再記一個 t1,於是 RTT = t1 – t0。沒那么簡單,這只是一個采樣,不能代表普遍情況。
實際上「報文往返 RTT 的值」是經常變化的,因為我們的網絡也是時常變化的。也就因為「報文往返 RTT 的值」 是經常波動變化的,所以「超時重傳時間 RTO 的值」應該是一個動態變化的值。
我們來看看 Linux 是如何計算 RTO 的呢?
估計往返時間,通常需要采樣以下兩個:
- 需要 TCP 通過采樣 RTT 的時間,然后進行加權平均,算出一個平滑 RTT 的值,而且這個值還是要不斷變化的,因為網絡狀況不斷地變化。
- 除了采樣 RTT,還要采樣 RTT 的波動范圍,這樣就避免如果 RTT 有一個大的波動的話,很難被發現的情況。
RFC6289 建議使用以下的公式計算 RTO:
 RFC6289 建議的 RTO 計算
RFC6289 建議的 RTO 計算
其中 SRTT 是計算平滑的RTT ,DevRTR 是計算平滑的RTT 與 最新 RTT 的差距。
在 Linux 下,α = 0.125,β = 0.25, μ = 1,∂ = 4。別問怎么來的,問就是大量實驗中調出來的。
如果超時重發的數據,再次超時的時候,又需要重傳的時候,TCP 的策略是超時間隔加倍。
也就是每當遇到一次超時重傳的時候,都會將下一次超時時間間隔設為先前值的兩倍。兩次超時,就說明網絡環境差,不宜頻繁反復發送。
超時觸發重傳存在的問題是,超時周期可能相對較長。那是不是可以有更快的方式呢?
於是就可以用「快速重傳」機制來解決超時重發的時間等待。
快速重傳
TCP 還有另外一種快速重傳(Fast Retransmit)機制,它不以時間為驅動,而是以數據驅動重傳。
快速重傳機制,是如何工作的呢?其實很簡單,一圖勝千言。
 快速重傳機制
快速重傳機制
在上圖,發送方發出了 1,2,3,4,5 份數據:
- 第一份 Seq1 先送到了,於是就 Ack 回 2;
- 結果 Seq2 因為某些原因沒收到,Seq3 到達了,於是還是 Ack 回 2;
- 后面的 Seq4 和 Seq5 都到了,但還是 Ack 回 2,因為 Seq2 還是沒有收到;
- 發送端收到了三個 Ack = 2 的確認,知道了 Seq2 還沒有收到,就會在定時器過期之前,重傳丟失的 Seq2。
- 最后,收到了 Seq2,此時因為 Seq3,Seq4,Seq5 都收到了,於是 Ack 回 6 。
所以,快速重傳的工作方式是當收到三個相同的 ACK 報文時,會在定時器過期之前,重傳丟失的報文段。
快速重傳機制只解決了一個問題,就是超時時間的問題,但是它依然面臨着另外一個問題。就是重傳的時候,是重傳之前的一個,還是重傳所有的問題。
比如對於上面的例子,是重傳 Seq2 呢?還是重傳 Seq2、Seq3、Seq4、Seq5 呢?因為發送端並不清楚這連續的三個 Ack 2 是誰傳回來的。
根據 TCP 不同的實現,以上兩種情況都是有可能的。可見,這是一把雙刃劍。
為了解決不知道該重傳哪些 TCP 報文,於是就有 SACK 方法。
SACK 方法
還有一種實現重傳機制的方式叫:SACK( Selective Acknowledgment 選擇性確認)。
這種方式需要在 TCP 頭部「選項」字段里加一個 SACK 的東西,它可以將緩存的地圖發送給發送方,這樣發送方就可以知道哪些數據收到了,哪些數據沒收到,知道了這些信息,就可以只重傳丟失的數據。
如下圖,發送方收到了三次同樣的 ACK 確認報文,於是就會觸發快速重發機制,通過 SACK 信息發現只有 200~299 這段數據丟失,則重發時,就只選擇了這個 TCP 段進行重復。
 選擇性確認
選擇性確認
如果要支持 SACK,必須雙方都要支持。在 Linux 下,可以通過 net.ipv4.tcp_sack 參數打開這個功能(Linux 2.4 后默認打開)。
Duplicate SACK
Duplicate SACK 又稱 D-SACK,其主要使用了 SACK 來告訴「發送方」有哪些數據被重復接收了。
下面舉例兩個栗子,來說明 D-SACK 的作用。
栗子一號:ACK 丟包
 ACK 丟包
ACK 丟包
- 「接收方」發給「發送方」的兩個 ACK 確認應答都丟失了,所以發送方超時后,重傳第一個數據包(3000 ~ 3499)
- 於是「接收方」發現數據是重復收到的,於是回了一個 SACK = 3000~3500,告訴「發送方」 3000~3500 的數據早已被接收了,因為 ACK 都到了 4000 了,已經意味着 4000 之前的所有數據都已收到,所以這個 SACK 就代表着
D-SACK。 - 這樣「發送方」就知道了,數據沒有丟,是「接收方」的 ACK 確認報文丟了。
栗子二號:網絡延時
 網絡延時
網絡延時
- 數據包(1000~1499) 被網絡延遲了,導致「發送方」沒有收到 Ack 1500 的確認報文。
- 而后面報文到達的三個相同的 ACK 確認報文,就觸發了快速重傳機制,但是在重傳后,被延遲的數據包(1000~1499)又到了「接收方」;
- 所以「接收方」回了一個 SACK=1000~1500,因為 ACK 已經到了 3000,所以這個 SACK 是 D-SACK,表示收到了重復的包。
- 這樣發送方就知道快速重傳觸發的原因不是發出去的包丟了,也不是因為回應的 ACK 包丟了,而是因為網絡延遲了。
可見,D-SACK 有這么幾個好處:
- 可以讓「發送方」知道,是發出去的包丟了,還是接收方回應的 ACK 包丟了;
- 可以知道是不是「發送方」的數據包被網絡延遲了;
- 可以知道網絡中是不是把「發送方」的數據包給復制了;
在 Linux 下可以通過 net.ipv4.tcp_dsack 參數開啟/關閉這個功能(Linux 2.4 后默認打開)。
滑動窗口
引入窗口概念的原因
我們都知道 TCP 是每發送一個數據,都要進行一次確認應答。當上一個數據包收到了應答了, 再發送下一個。
這個模式就有點像我和你面對面聊天,你一句我一句。但這種方式的缺點是效率比較低的。
如果你說完一句話,我在處理其他事情,沒有及時回復你,那你不是要干等着我做完其他事情后,我回復你,你才能說下一句話,很顯然這不現實。
 按數據包進行確認應答
按數據包進行確認應答
所以,這樣的傳輸方式有一個缺點:數據包的往返時間越長,通信的效率就越低。
為解決這個問題,TCP 引入了窗口這個概念。即使在往返時間較長的情況下,它也不會降低網絡通信的效率。
那么有了窗口,就可以指定窗口大小,窗口大小就是指無需等待確認應答,而可以繼續發送數據的最大值。
窗口的實現實際上是操作系統開辟的一個緩存空間,發送方主機在等到確認應答返回之前,必須在緩沖區中保留已發送的數據。如果按期收到確認應答,此時數據就可以從緩存區清除。
假設窗口大小為 3 個 TCP 段,那么發送方就可以「連續發送」 3 個 TCP 段,並且中途若有 ACK 丟失,可以通過「下一個確認應答進行確認」。如下圖:
 用滑動窗口方式並行處理
用滑動窗口方式並行處理
圖中的 ACK 600 確認應答報文丟失,也沒關系,因為可以通過下一個確認應答進行確認,只要發送方收到了 ACK 700 確認應答,就意味着 700 之前的所有數據「接收方」都收到了。這個模式就叫累計確認或者累計應答。
窗口大小由哪一方決定?
TCP 頭里有一個字段叫 Window,也就是窗口大小。
這個字段是接收端告訴發送端自己還有多少緩沖區可以接收數據。於是發送端就可以根據這個接收端的處理能力來發送數據,而不會導致接收端處理不過來。
所以,通常窗口的大小是由接收方的窗口大小來決定的。
發送方發送的數據大小不能超過接收方的窗口大小,否則接收方就無法正常接收到數據。
發送方的滑動窗口
我們先來看看發送方的窗口,下圖就是發送方緩存的數據,根據處理的情況分成四個部分,其中深藍色方框是發送窗口,紫色方框是可用窗口:

- #1 是已發送並收到 ACK確認的數據:1~31 字節
- #2 是已發送但未收到 ACK確認的數據:32~45 字節
- #3 是未發送但總大小在接收方處理范圍內(接收方還有空間):46~51字節
- #4 是未發送但總大小超過接收方處理范圍(接收方沒有空間):52字節以后
在下圖,當發送方把數據「全部」都一下發送出去后,可用窗口的大小就為 0 了,表明可用窗口耗盡,在沒收到 ACK 確認之前是無法繼續發送數據了。
 可用窗口耗盡
可用窗口耗盡
在下圖,當收到之前發送的數據 32~36 字節的 ACK 確認應答后,如果發送窗口的大小沒有變化,則滑動窗口往右邊移動 5 個字節,因為有 5 個字節的數據被應答確認,接下來 52~56 字節又變成了可用窗口,那么后續也就可以發送 52~56 這 5 個字節的數據了。
 32 ~ 36 字節已確認
32 ~ 36 字節已確認
程序是如何表示發送方的四個部分的呢?
TCP 滑動窗口方案使用三個指針來跟蹤在四個傳輸類別中的每一個類別中的字節。其中兩個指針是絕對指針(指特定的序列號),一個是相對指針(需要做偏移)。
 SND.WND、SND.UN、SND.NXT
SND.WND、SND.UN、SND.NXT
-
SND.WND:表示發送窗口的大小(大小是由接收方指定的); -
SND.UNA:是一個絕對指針,它指向的是已發送但未收到確認的第一個字節的序列號,也就是 #2 的第一個字節。 -
SND.NXT:也是一個絕對指針,它指向未發送但可發送范圍的第一個字節的序列號,也就是 #3 的第一個字節。 -
指向 #4 的第一個字節是個相對指針,它需要
SND.UNA指針加上SND.WND大小的偏移量,就可以指向 #4 的第一個字節了。
那么可用窗口大小的計算就可以是:
可用窗口大 = SND.WND -(SND.NXT - SND.UNA)
接收方的滑動窗口
接下來我們看看接收方的窗口,接收窗口相對簡單一些,根據處理的情況划分成三個部分:
- #1 + #2 是已成功接收並確認的數據(等待應用進程讀取);
- #3 是未收到數據但可以接收的數據;
- #4 未收到數據並不可以接收的數據;
 接收窗口
接收窗口
其中三個接收部分,使用兩個指針進行划分:
RCV.WND:表示接收窗口的大小,它會通告給發送方。RCV.NXT:是一個指針,它指向期望從發送方發送來的下一個數據字節的序列號,也就是 #3 的第一個字節。- 指向 #4 的第一個字節是個相對指針,它需要
RCV.NXT指針加上RCV.WND大小的偏移量,就可以指向 #4 的第一個字節了。
接收窗口和發送窗口的大小是相等的嗎?
並不是完全相等,接收窗口的大小是約等於發送窗口的大小的。
因為滑動窗口並不是一成不變的。比如,當接收方的應用進程讀取數據的速度非常快的話,這樣的話接收窗口可以很快的就空缺出來。那么新的接收窗口大小,是通過 TCP 報文中的 Windows 字段來告訴發送方。那么這個傳輸過程是存在時延的,所以接收窗口和發送窗口是約等於的關系。
流量控制
發送方不能無腦的發數據給接收方,要考慮接收方處理能力。
如果一直無腦的發數據給對方,但對方處理不過來,那么就會導致觸發重發機制,從而導致網絡流量的無端的浪費。
為了解決這種現象發生,TCP 提供一種機制可以讓「發送方」根據「接收方」的實際接收能力控制發送的數據量,這就是所謂的流量控制。
下面舉個栗子,為了簡單起見,假設以下場景:
- 客戶端是接收方,服務端是發送方
- 假設接收窗口和發送窗口相同,都為
200 - 假設兩個設備在整個傳輸過程中都保持相同的窗口大小,不受外界影響
 流量控制
流量控制
根據上圖的流量控制,說明下每個過程:
- 客戶端向服務端發送請求數據報文。這里要說明下,本次例子是把服務端作為發送方,所以沒有畫出服務端的接收窗口。
- 服務端收到請求報文后,發送確認報文和 80 字節的數據,於是可用窗口
Usable減少為 120 字節,同時SND.NXT指針也向右偏移 80 字節后,指向 321,這意味着下次發送數據的時候,序列號是 321。 - 客戶端收到 80 字節數據后,於是接收窗口往右移動 80 字節,
RCV.NXT也就指向 321,這意味着客戶端期望的下一個報文的序列號是 321,接着發送確認報文給服務端。 - 服務端再次發送了 120 字節數據,於是可用窗口耗盡為 0,服務端無法再繼續發送數據。
- 客戶端收到 120 字節的數據后,於是接收窗口往右移動 120 字節,
RCV.NXT也就指向 441,接着發送確認報文給服務端。 - 服務端收到對 80 字節數據的確認報文后,
SND.UNA指針往右偏移后指向 321,於是可用窗口Usable增大到 80。 - 服務端收到對 120 字節數據的確認報文后,
SND.UNA指針往右偏移后指向 441,於是可用窗口Usable增大到 200。 - 服務端可以繼續發送了,於是發送了 160 字節的數據后,
SND.NXT指向 601,於是可用窗口Usable減少到 40。 - 客戶端收到 160 字節后,接收窗口往右移動了 160 字節,
RCV.NXT也就是指向了 601,接着發送確認報文給服務端。 - 服務端收到對 160 字節數據的確認報文后,發送窗口往右移動了 160 字節,於是
SND.UNA指針偏移了 160 后指向 601,可用窗口Usable也就增大至了 200。
操作系統緩沖區與滑動窗口的關系
前面的流量控制例子,我們假定了發送窗口和接收窗口是不變的,但是實際上,發送窗口和接收窗口中所存放的字節數,都是放在操作系統內存緩沖區中的,而操作系統的緩沖區,會被操作系統調整。
當應用進程沒辦法及時讀取緩沖區的內容時,也會對我們的緩沖區造成影響。
那操心系統的緩沖區,是如何影響發送窗口和接收窗口的呢?
我們先來看看第一個例子。
當應用程序沒有及時讀取緩存時,發送窗口和接收窗口的變化。
考慮以下場景:
- 客戶端作為發送方,服務端作為接收方,發送窗口和接收窗口初始大小為
360; - 服務端非常的繁忙,當收到客戶端的數據時,應用層不能及時讀取數據。
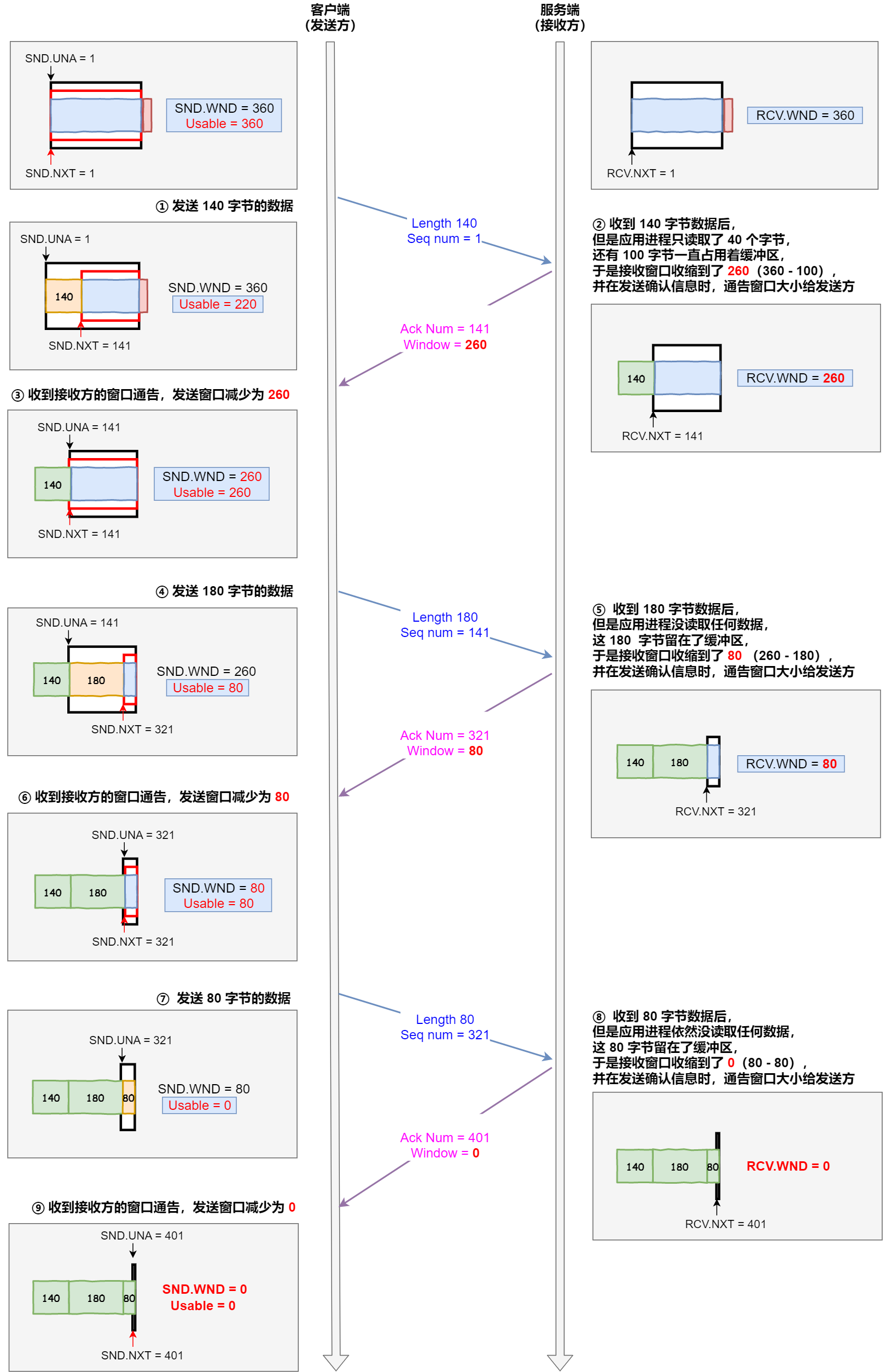
根據上圖的流量控制,說明下每個過程:
- 客戶端發送 140 字節數據后,可用窗口變為 220 (360 - 140)。
- 服務端收到 140 字節數據,但是服務端非常繁忙,應用進程只讀取了 40 個字節,還有 100 字節占用着緩沖區,於是接收窗口收縮到了 260 (360 - 100),最后發送確認信息時,將窗口大小通告給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 260。
- 客戶端發送 180 字節數據,此時可用窗口減少到 80。
- 服務端收到 180 字節數據,但是應用程序沒有讀取任何數據,這 180 字節直接就留在了緩沖區,於是接收窗口收縮到了 80 (260 - 180),並在發送確認信息時,通過窗口大小給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 80。
- 客戶端發送 80 字節數據后,可用窗口耗盡。
- 服務端收到 80 字節數據,但是應用程序依然沒有讀取任何數據,這 80 字節留在了緩沖區,於是接收窗口收縮到了 0,並在發送確認信息時,通過窗口大小給客戶端。
- 客戶端收到確認和窗口通告報文后,發送窗口減少為 0。
可見最后窗口都收縮為 0 了,也就是發生了窗口關閉。當發送方可用窗口變為 0 時,發送方實際上會定時發送窗口探測報文,以便知道接收方的窗口是否發生了改變,這個內容后面會說,這里先簡單提一下。
我們先來看看第二個例子。
當服務端系統資源非常緊張的時候,操心系統可能會直接減少了接收緩沖區大小,這時應用程序又無法及時讀取緩存數據,那么這時候就有嚴重的事情發生了,會出現數據包丟失的現象。
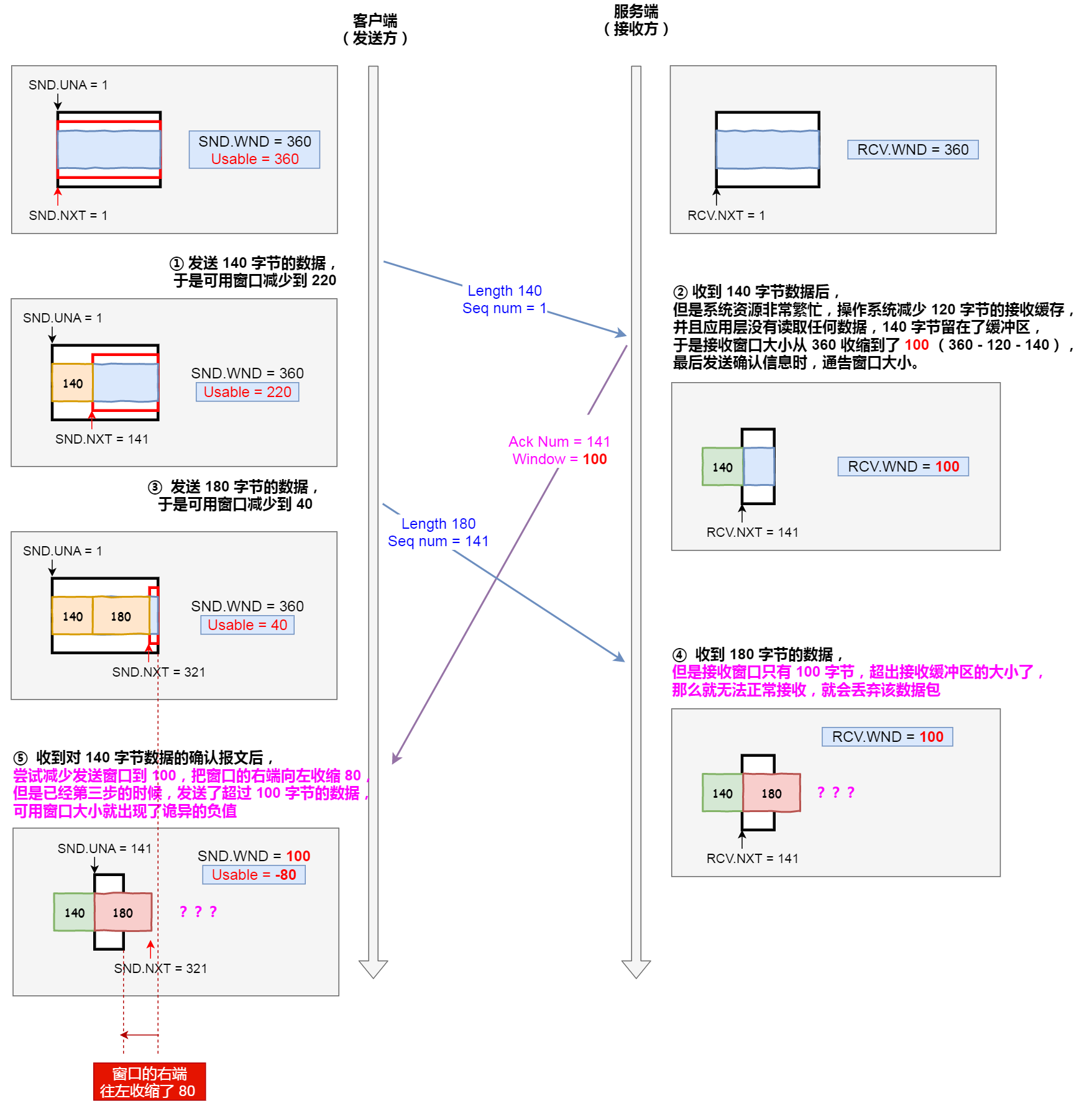
說明下每個過程:
- 客戶端發送 140 字節的數據,於是可用窗口減少到了 220。
- 服務端因為現在非常的繁忙,操作系統於是就把接收緩存減少了 120 字節,當收到 140 字節數據后,又因為應用程序沒有讀取任何數據,所以 140 字節留在了緩沖區中,於是接收窗口大小從 360 收縮成了 100,最后發送確認信息時,通告窗口大小給對方。
- 此時客戶端因為還沒有收到服務端的通告窗口報文,所以不知道此時接收窗口收縮成了 100,客戶端只會看自己的可用窗口還有 220,所以客戶端就發送了 180 字節數據,於是可用窗口減少到 40。
- 服務端收到了 180 字節數據時,發現數據大小超過了接收窗口的大小,於是就把數據包丟失了。
- 客戶端收到第 2 步時,服務端發送的確認報文和通告窗口報文,嘗試減少發送窗口到 100,把窗口的右端向左收縮了 80,此時可用窗口的大小就會出現詭異的負值。
所以,如果發生了先減少緩存,再收縮窗口,就會出現丟包的現象。
為了防止這種情況發生,TCP 規定是不允許同時減少緩存又收縮窗口的,而是采用先收縮窗口,過段時間再減少緩存,這樣就可以避免了丟包情況。
窗口關閉
在前面我們都看到了,TCP 通過讓接收方指明希望從發送方接收的數據大小(窗口大小)來進行流量控制。
如果窗口大小為 0 時,就會阻止發送方給接收方傳遞數據,直到窗口變為非 0 為止,這就是窗口關閉。
窗口關閉潛在的危險
接收方向發送方通告窗口大小時,是通過 ACK 報文來通告的。
那么,當發生窗口關閉時,接收方處理完數據后,會向發送方通告一個窗口非 0 的 ACK 報文,如果這個通告窗口的 ACK 報文在網絡中丟失了,那麻煩就大了。
 窗口關閉潛在的危險
窗口關閉潛在的危險
這會導致發送方一直等待接收方的非 0 窗口通知,接收方也一直等待發送方的數據,如不采取措施,這種相互等待的過程,會造成了死鎖的現象。
TCP 是如何解決窗口關閉時,潛在的死鎖現象呢?
為了解決這個問題,TCP 為每個連接設有一個持續定時器,只要 TCP 連接一方收到對方的零窗口通知,就啟動持續計時器。
如果持續計時器超時,就會發送窗口探測 ( Window probe ) 報文,而對方在確認這個探測報文時,給出自己現在的接收窗口大小。
 窗口探測
窗口探測
- 如果接收窗口仍然為 0,那么收到這個報文的一方就會重新啟動持續計時器;
- 如果接收窗口不是 0,那么死鎖的局面就可以被打破了。
窗口探測的次數一般為 3 次,每次大約 30-60 秒(不同的實現可能會不一樣)。如果 3 次過后接收窗口還是 0 的話,有的 TCP 實現就會發 RST 報文來中斷連接。
糊塗窗口綜合症
如果接收方太忙了,來不及取走接收窗口里的數據,那么就會導致發送方的發送窗口越來越小。
到最后,如果接收方騰出幾個字節並告訴發送方現在有幾個字節的窗口,而發送方會義無反顧地發送這幾個字節,這就是糊塗窗口綜合症。
要知道,我們的 TCP + IP 頭有 40 個字節,為了傳輸那幾個字節的數據,要達上這么大的開銷,這太不經濟了。
就好像一個可以承載 50 人的大巴車,每次來了一兩個人,就直接發車。除非家里有礦的大巴司機,才敢這樣玩,不然遲早破產。要解決這個問題也不難,大巴司機等乘客數量超過了 25 個,才認定可以發車。
現舉個糊塗窗口綜合症的栗子,考慮以下場景:
接收方的窗口大小是 360 字節,但接收方由於某些原因陷入困境,假設接收方的應用層讀取的能力如下:
- 接收方每接收 3 個字節,應用程序就只能從緩沖區中讀取 1 個字節的數據;
- 在下一個發送方的 TCP 段到達之前,應用程序還從緩沖區中讀取了 40 個額外的字節;
 糊塗窗口綜合症
糊塗窗口綜合症
每個過程的窗口大小的變化,在圖中都描述的很清楚了,可以發現窗口不斷減少了,並且發送的數據都是比較小的了。
所以,糊塗窗口綜合症的現象是可以發生在發送方和接收方:
- 接收方可以通告一個小的窗口
- 而發送方可以發送小數據
於是,要解決糊塗窗口綜合症,就解決上面兩個問題就可以了
- 讓接收方不通告小窗口給發送方
- 讓發送方避免發送小數據
怎么讓接收方不通告小窗口呢?
接收方通常的策略如下:
當「窗口大小」小於 min( MSS,緩存空間/2 ) ,也就是小於 MSS 與 1/2 緩存大小中的最小值時,就會向發送方通告窗口為 0,也就阻止了發送方再發數據過來。
等到接收方處理了一些數據后,窗口大小 >= MSS,或者接收方緩存空間有一半可以使用,就可以把窗口打開讓發送方發送數據過來。
怎么讓發送方避免發送小數據呢?
發送方通常的策略:
使用 Nagle 算法,該算法的思路是延時處理,它滿足以下兩個條件中的一條才可以發送數據:
- 要等到窗口大小 >=
MSS或是 數據大小 >=MSS - 收到之前發送數據的
ack回包
只要沒滿足上面條件中的一條,發送方一直在囤積數據,直到滿足上面的發送條件。
另外,Nagle 算法默認是打開的,如果對於一些需要小數據包交互的場景的程序,比如,telnet 或 ssh 這樣的交互性比較強的程序,則需要關閉 Nagle 算法。
可以在 Socket 設置 TCP_NODELAY 選項來關閉這個算法(關閉 Nagle 算法沒有全局參數,需要根據每個應用自己的特點來關閉)
setsockopt(sock_fd, IPPROTO_TCP, TCP_NODELAY, (char *)&value, sizeof(int));
擁塞控制
為什么要有擁塞控制呀,不是有流量控制了嗎?
前面的流量控制是避免「發送方」的數據填滿「接收方」的緩存,但是並不知道網絡的中發生了什么。
一般來說,計算機網絡都處在一個共享的環境。因此也有可能會因為其他主機之間的通信使得網絡擁堵。
在網絡出現擁堵時,如果繼續發送大量數據包,可能會導致數據包時延、丟失等,這時 TCP 就會重傳數據,但是一重傳就會導致網絡的負擔更重,於是會導致更大的延遲以及更多的丟包,這個情況就會進入惡性循環被不斷地放大….
所以,TCP 不能忽略網絡上發生的事,它被設計成一個無私的協議,當網絡發送擁塞時,TCP 會自我犧牲,降低發送的數據量。
於是,就有了擁塞控制,控制的目的就是避免「發送方」的數據填滿整個網絡。
為了在「發送方」調節所要發送數據的量,定義了一個叫做「擁塞窗口」的概念。
什么是擁塞窗口?和發送窗口有什么關系呢?
擁塞窗口 cwnd是發送方維護的一個的狀態變量,它會根據網絡的擁塞程度動態變化的。
我們在前面提到過發送窗口 swnd 和接收窗口 rwnd 是約等於的關系,那么由於加入了擁塞窗口的概念后,此時發送窗口的值是swnd = min(cwnd, rwnd),也就是擁塞窗口和接收窗口中的最小值。
擁塞窗口 cwnd 變化的規則:
- 只要網絡中沒有出現擁塞,
cwnd就會增大; - 但網絡中出現了擁塞,
cwnd就減少;
那么怎么知道當前網絡是否出現了擁塞呢?
其實只要「發送方」沒有在規定時間內接收到 ACK 應答報文,也就是發生了超時重傳,就會認為網絡出現了用擁塞。
擁塞控制有哪些控制算法?
擁塞控制主要是四個算法:
- 慢啟動
- 擁塞避免
- 擁塞發生
- 快速恢復
慢啟動
TCP 在剛建立連接完成后,首先是有個慢啟動的過程,這個慢啟動的意思就是一點一點的提高發送數據包的數量,如果一上來就發大量的數據,這不是給網絡添堵嗎?
慢啟動的算法記住一個規則就行:當發送方每收到一個 ACK,擁塞窗口 cwnd 的大小就會加 1。
這里假定擁塞窗口 cwnd 和發送窗口 swnd 相等,下面舉個栗子:
- 連接建立完成后,一開始初始化
cwnd = 1,表示可以傳一個MSS大小的數據。 - 當收到一個 ACK 確認應答后,cwnd 增加 1,於是一次能夠發送 2 個
- 當收到 2 個的 ACK 確認應答后, cwnd 增加 2,於是就可以比之前多發2 個,所以這一次能夠發送 4 個
- 當這 4 個的 ACK 確認到來的時候,每個確認 cwnd 增加 1, 4 個確認 cwnd 增加 4,於是就可以比之前多發 4 個,所以這一次能夠發送 8 個。
 慢啟動算法
慢啟動算法
可以看出慢啟動算法,發包的個數是指數性的增長。
那慢啟動漲到什么時候是個頭呢?
有一個叫慢啟動門限 ssthresh (slow start threshold)狀態變量。
- 當
cwnd<ssthresh時,使用慢啟動算法。 - 當
cwnd>=ssthresh時,就會使用「擁塞避免算法」。
擁塞避免算法
前面說道,當擁塞窗口 cwnd 「超過」慢啟動門限 ssthresh 就會進入擁塞避免算法。
一般來說 ssthresh 的大小是 65535 字節。
那么進入擁塞避免算法后,它的規則是:每當收到一個 ACK 時,cwnd 增加 1/cwnd。
接上前面的慢啟動的栗子,現假定 ssthresh 為 8:
- 當 8 個 ACK 應答確認到來時,每個確認增加 1/8,8 個 ACK 確認 cwnd 一共增加 1,於是這一次能夠發送 9 個
MSS大小的數據,變成了線性增長。
 擁塞避免
擁塞避免
所以,我們可以發現,擁塞避免算法就是將原本慢啟動算法的指數增長變成了線性增長,還是增長階段,但是增長速度緩慢了一些。
就這么一直增長着后,網絡就會慢慢進入了擁塞的狀況了,於是就會出現丟包現象,這時就需要對丟失的數據包進行重傳。
當觸發了重傳機制,也就進入了「擁塞發生算法」。
擁塞發生
當網絡出現擁塞,也就是會發生數據包重傳,重傳機制主要有兩種:
- 超時重傳
- 快速重傳
這兩種使用的擁塞發送算法是不同的,接下來分別來說說。
發生超時重傳的擁塞發生算法
當發生了「超時重傳」,則就會使用擁塞發生算法。
這個時候,ssthresh 和 cwnd 的值會發生變化:
ssthresh設為cwnd/2,cwnd重置為1
 擁塞發送 —— 超時重傳
擁塞發送 —— 超時重傳
接着,就重新開始慢啟動,慢啟動是會突然減少數據流的。這真是一旦「超時重傳」,馬上回到解放前。但是這種方式太激進了,反應也很強烈,會造成網絡卡頓。
就好像本來在秋名山高速漂移着,突然來個緊急剎車,輪胎受得了嗎。。。
發生快速重傳的擁塞發生算法
還有更好的方式,前面我們講過「快速重傳算法」。當接收方發現丟了一個中間包的時候,發送三次前一個包的 ACK,於是發送端就會快速地重傳,不必等待超時再重傳。
TCP 認為這種情況不嚴重,因為大部分沒丟,只丟了一小部分,則 ssthresh 和 cwnd 變化如下:
cwnd = cwnd/2,也就是設置為原來的一半;ssthresh = cwnd;- 進入快速恢復算法
快速恢復
快速重傳和快速恢復算法一般同時使用,快速恢復算法是認為,你還能收到 3 個重復 ACK 說明網絡也不那么糟糕,所以沒有必要像 RTO 超時那么強烈。
正如前面所說,進入快速恢復之前,cwnd 和 ssthresh 已被更新了:
cwnd = cwnd/2,也就是設置為原來的一半;ssthresh = cwnd;
然后,進入快速恢復算法如下:
- 擁塞窗口
cwnd = ssthresh + 3( 3 的意思是確認有 3 個數據包被收到了); - 重傳丟失的數據包;
- 如果再收到重復的 ACK,那么 cwnd 增加 1;
- 如果收到新數據的 ACK 后,把 cwnd 設置為第一步中的 ssthresh 的值,原因是該 ACK 確認了新的數據,說明從 duplicated ACK 時的數據都已收到,該恢復過程已經結束,可以回到恢復之前的狀態了,也即再次進入擁塞避免狀態;
 快速重傳和快速恢復
快速重傳和快速恢復
也就是沒有像「超時重傳」一夜回到解放前,而是還在比較高的值,后續呈線性增長。
擁塞算法示意圖
好了,以上就是擁塞控制的全部內容了,看完后,你再來看下面這張圖片,每個過程我相信你都能明白:
 TCP 擁塞控制
TCP 擁塞控制
巨人的肩膀
[1] 趣談網絡協議專欄.劉超.極客時間
[2] Web協議詳解與抓包實戰專欄.陶輝.極客時間
[3] TCP/IP詳解 卷1:協議.范建華 譯.機械工業出版社
[4] 圖解TCP/IP.竹下隆史.人民郵電出版社
[5] The TCP/IP Guide.Charles M. Kozierok.
[6] TCP那些事(上).陳皓.酷殼博客.
https://coolshell.cn/articles/11564.html
[7] TCP那些事(下).陳皓.酷殼博客.https://coolshell.cn/articles/11609.html
嘮叨嘮叨
是吧? TCP 巨復雜吧?看完很累吧?
但這還只是 TCP 冰山一腳,它的更深處就由你們自己去探索啦。
本文只是拋磚引玉,若你有更好的想法或文章有誤的地方,歡迎留言討論!
小林是專為大家圖解的工具人,Goodbye,我們下次見!

讀者問答
讀者問:“整個看完收獲很大,下面是我的一些疑問(稍后
會去確認):
1.擁塞避免這一段,藍色字體:每當收到一個
ACK時,cwnd增加1/cwnd。是否應該是
1/ssthresh?否則不符合線性增長。
2.快速重傳的擁塞發生算法,步驟一和步驟2是
否寫反了?否則快速恢復算法中最后一步【如果
收到新數據的ACK后,設置cwnd為
ssthresh,接看就進入了擁塞避免算法】沒什么
意義。
3.對ssthresh的變化介紹的比較含糊。”
- 是 1/cwnd,你可以在 RFC2581 第 3 頁找到答案
- 沒有寫反,同樣你可以在 RFC2581 第 5 頁找到答案
- ssthresh 就是慢啟動門限,我覺得 ssthresh 我已經說的很清楚了,當然你可以找其他資料補充你的疑惑