產品簡介
UDW(UCloud Data Warehouse)是大規模並行處理數據倉庫產品,提供Greenplum和Udpg兩種可選的類型。Greenplum是EMC開源的數據倉庫,Udpg是基於PostgreSQL開發的大規模並行、完全托管的PB級數據倉庫服務。UDW支持JSON類型,可用通過SQL讓數據分析更簡單、高效,為互聯網、物聯網、金融、電信等行業提供豐富的業務分析能力
雲數據倉庫UDW的特性
- 海量存儲分析:支持百GB到上PB級別的數據存儲和分析
- 實時分析:通過准實時、實時的數據加載,實現對數據倉庫的實時更新,從而對業務進行實時分析
- 簡單易用:豐富的OLAP SQL語法及函數,用sql讓數據分析變得簡單、高效
- 多種數據存儲方式:行存儲、列存儲、HDFS外部表、ufile外部表讓存儲多樣化
- 線性擴展:通過增加節點可以線性的提高系統的存儲和計算能力
- 穩定可靠:除了硬件raid之外,所有的數據都是雙機熱備,同時還會定期的冷備
- 支持JSON類型:讓JSON格式的數據處理更方便
雲數據倉庫UDW使用場景
- 整合BI系統:UDW的OLAP分析能力,可以給報表多維分析提供有效的性能保障,並且可以實現從百GB到上PB平滑擴展。
- 對接監控系統:可以通過對監控數據的實時加載和分析、找出監控指標的異常。
- 分析業務數據:實時對業務數據分析、可以幫用戶快速做出決策。
- 匯總不同來源的數據:把mysql、日志等不同來源的數據匯總到UDW、結合業務數據和日志對業務進行匯總、深度分析。
利用UHadoop和UDW構建大數據服務平台
在分析構建大數據服務平台之前,我們先看看大數據應用場景,常見的大數據應用場景如下:
- 離線/批量分析:離線/批量分析一般對實時性要求不高,大部分都是小時、天級別的周期性任務,這部分我們用Hive/MapReduce/UDW來實現;
- 數據倉庫/數據分析查詢:此類場景會有很多查詢需求,並且大部分查詢是臨時性的,如果對實時性要求不高可以使用Hive,如果對實時性要求比較高的話可以使用Spark SQL或者UDW;
- 在線服務:在線服務一般都要快速響應,比較適合使用Hbase或者UDW來滿足需求;
- 流式處理:一般要求數據不落地,實時收集、實時處理、實時決策,我們可以借助Kafka Spark Streaming來應對流失處理場景;
- 數據挖掘/機器學習:主要是在現有數據上面進行基於各種算法的計算,起到預測的效果,從而實現一些高級別數據分析的需求,我們可以利用Spark MLlib提供的豐富的機器學習庫來輕松應對數據深層分析。
產品架構
雲數據倉庫產品架構
雲數據庫倉庫 UDW 服務的架構圖如下所示:
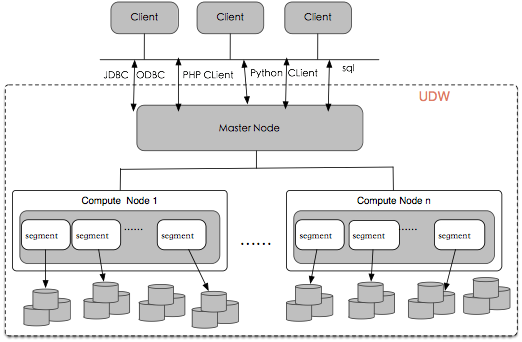
UDW 采用無共享的 MPP 架構,適用於海量數據的存儲和計算。UDW 的架構如上圖所示,主要有 Client、Master Node 和 Compute Node 組成。基本組成部分的功能如下:
- Client:訪問 UDW 的客戶端
- 支持通過 JDBC、ODBC、PHP、Python、命令行 Sql 等方式訪問 UDW
- Master Node:訪問 UDW 數據倉庫的入口
- 接收客戶端的連接請求
- 負責權限認證
- 處理 SQL 命令
- 調度分發執行計划
- 匯總 Segment 的執行結果並將結果返回給客戶端
- Compute Node:
- Compute Node 管理節點的計算和存儲資源
- 每個 Compute Node 由多個 Segment 組成
- Segment 負責業務數據的存儲、用戶 SQL 的執行