經過測試,同步MongoDB數據到Solr的時候,Solr版本為8.4.0會出現連接不上的錯誤,8.3.0未經測試不知,博主測試好用的一版為8.2.0,但是官網已經下不到了,所以我會把下載鏈接放在文末,需要的同學自取,不要再下8.3.0/8.4.0!!!
拖更了一個多月,忙於公司的新項目,期間接觸到了一個新東西,那就是solr,什么是solr,我理解為全文檢索,他能實現數據庫的全文檢索並實現高亮顯示,相信你的腦海中已經浮現出了在淘寶類似的購物平台搜索商品時的樣子,沒錯,solr跟他很類似,當我們需要全文檢索的時候就可以用到solr,下面開始搭建solr環境。
下載安裝Apache Solr
我們到solr官網下載solr安裝包
下載為zip格式,直接解壓到本地即可。solr內置了jetty服務器,所以我們可以直接運行,當然我們也可以把solr部署到tomcat等服務器中運行,這里我們使用內置的服務器。
啟動solr服務
我們進入到solr安裝目錄的bin文件夾下,shift+右鍵打開命令行窗口,win10是powershell窗口,所以我們打開后要執行cmd命令切換到cmd窗口(以下所執行的solr命令均是在此目錄下執行,不再贅述),接着執行solr start來啟動solr,這是solr啟動成功的畫面。
我們打開瀏覽器輸入localhost:8983(solr默認啟動端口為8983)就能看到solr界面了。
添加core
core就相當於solr的一個項目實例,輸入命令solr create -c mycore
成功創建后,可以在 solr-8.2.0/server/solr/ 目錄下看到自動生成的默認配置文件
創建完成后,重新進入后台控制頁面,可以查看到新建的 core
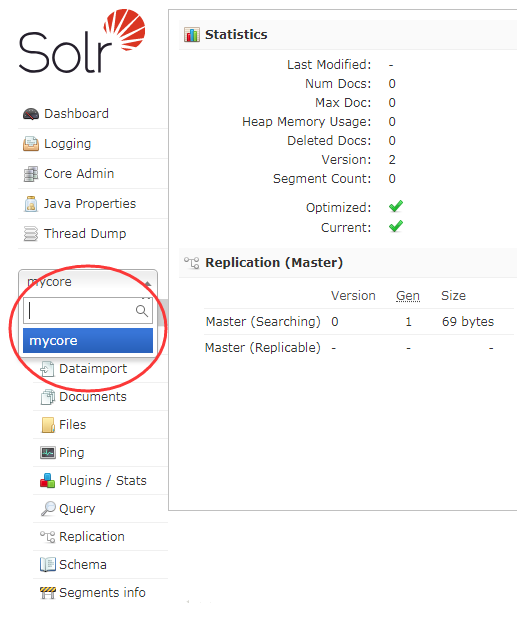
配置中文分詞器 IK-Analyzer-Solr8
分詞器就是能把我們輸入的一個短語分成幾個單詞的形式,例如我愛中國,會被分為 我,愛,中國,三個。
為什么需要分詞器?全文檢索的意義就是當我們輸入一個詞語的時候能把相關涵蓋的全都搜出來,比如我們搜索筆記本電腦,會把筆記本電腦拆成,筆記本,電腦,也就是說筆記本和電腦都會被查出來,這才是我們所需要的。
下載solr8版本的ik分詞器,下載地址:https://search.maven.org/search?q=com.github.magese
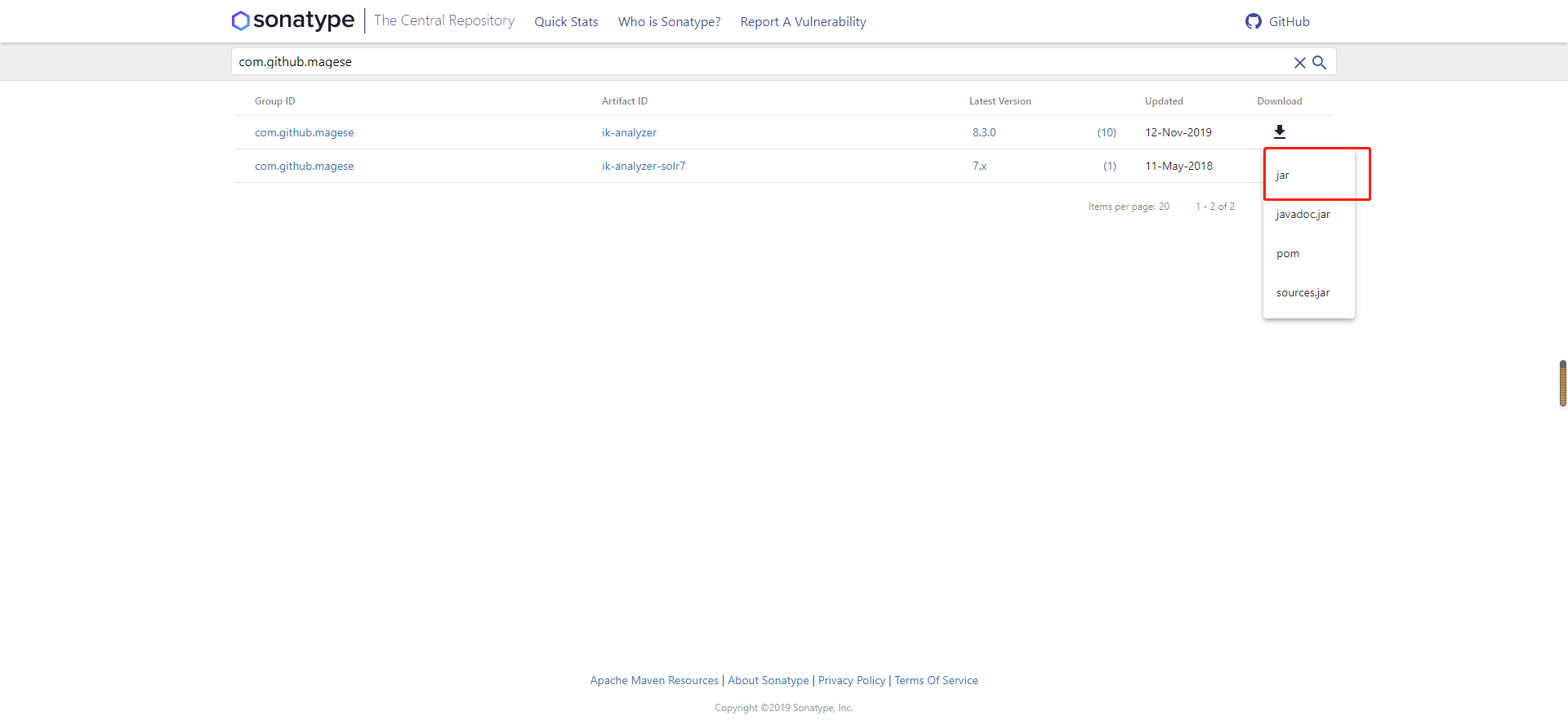
將下載好的jar包放入solr-8.2.0\server\solr-webapp\webapp\WEB-INF\lib目錄中
然后到solr-8.2.0\server\solr\mycore\conf目錄中打開managed-schema文件
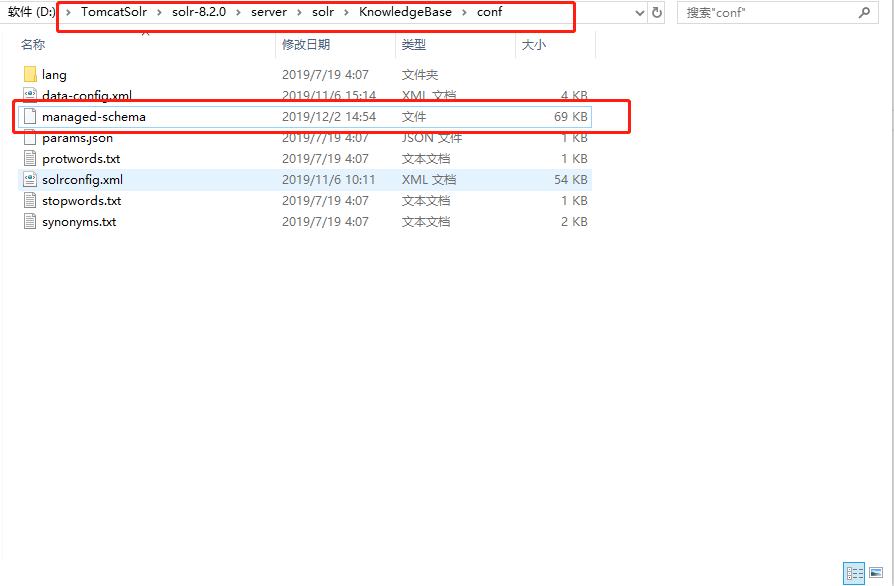
打開managed-schema文件在文件末尾添加以下代碼
<!-- ik分詞器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
然后我們輸入solr restart -port 8983來重啟solr,回到后台管理頁面
選擇mycore -> Analysis -> 選擇分詞器 text_ik 輸入 "我愛中國"
點擊"Analyse Values"按鈕可以看到結果已經分詞成功了。

Solr后台管理
solr的安裝與部署已經結束了,接下來帶大家熟悉solr管理界面的各種功能。
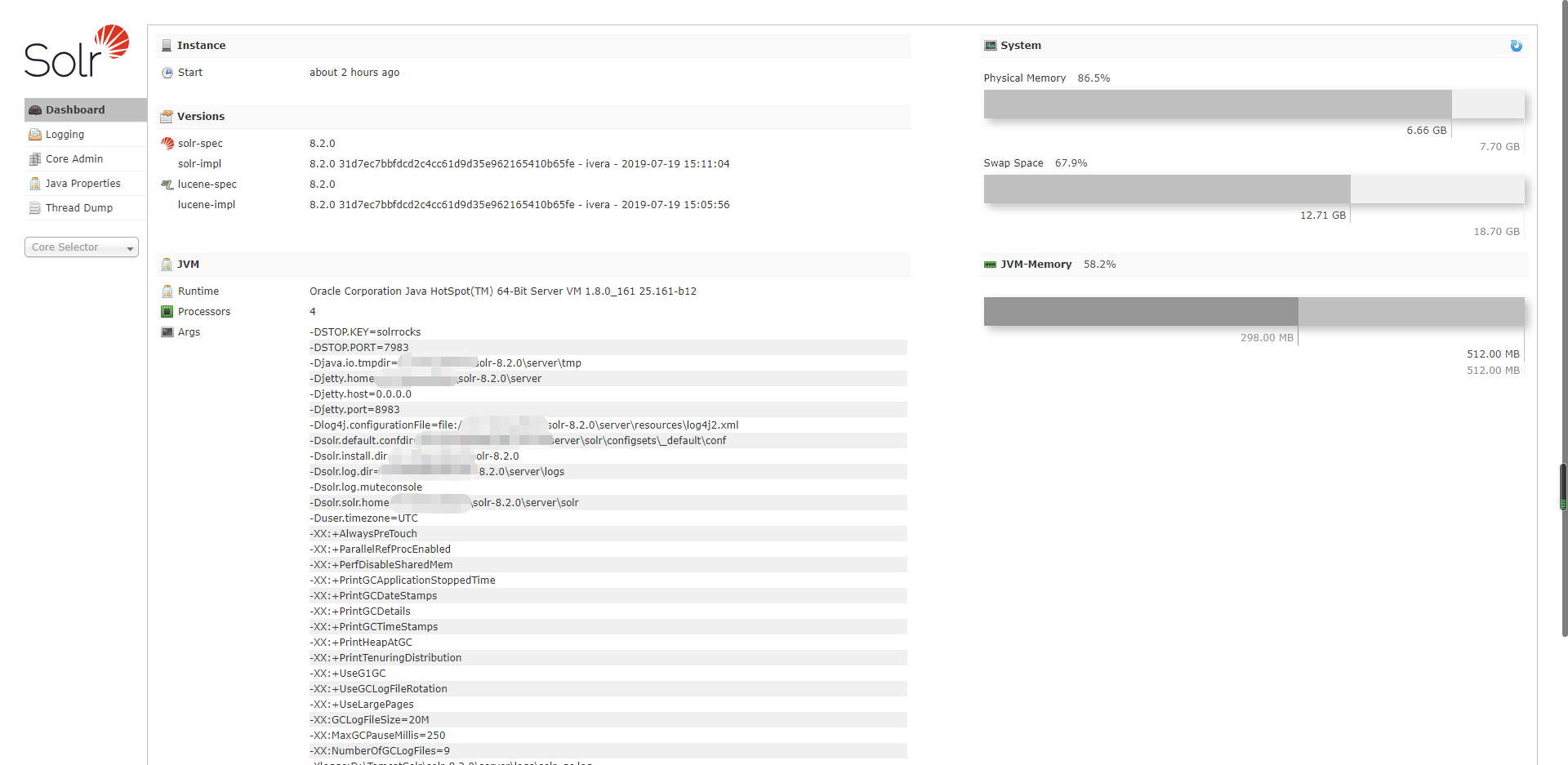
Dashboard
儀表盤,顯示了該Solr實例開始啟動運行的時間、版本、系統資源、jvm等信息。
Logging
Solr運行日志信息
Core Admin
Solr Core的管理界面。Solr Core 是Solr的一個獨立運行實例單位,它可以對外提供索引和搜索服務,一個Solr工程可以運行多個SolrCore(Solr實例),一個Core對應一個索引目錄。
java properties
Solr在JVM 運行環境中的屬性信息,包括類路徑、文件編碼、jvm內存設置等信息。
Tread Dump
顯示Solr Server中當前活躍線程信息,同時也可以跟蹤線程運行棧信息。
Core selector
選擇一個SolrCore進行詳細操作,如下:

Analysis
分詞器,在上面已經講過了,通過此界面可以測試索引分析器和搜索分析器的執行情況。
Dataimport
可以定義數據導入處理器,從關系數據庫將數據導入 到Solr索引庫中。
Document
通過此菜單可以創建索引、更新索引、刪除索引等操作,界面如下:
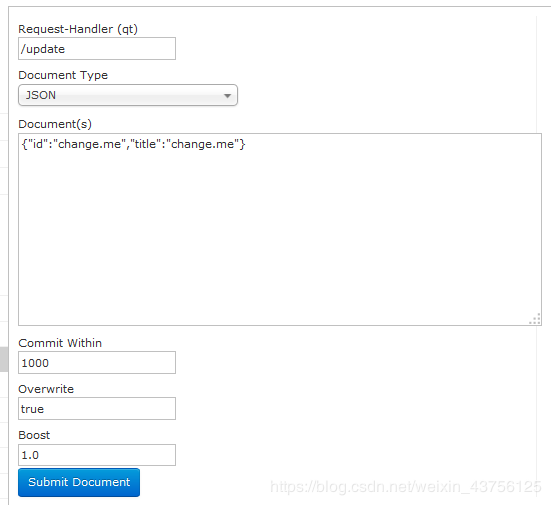
/update表示更新索引,solr默認根據id(唯一約束)域來更新Document的內容,如果根據id值搜索不到id域則會執行添加操作,如果找到則更新。
Query
solr的條件查詢操作
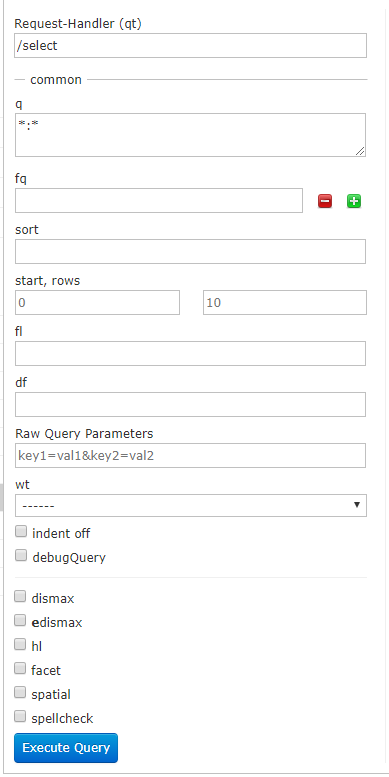
Request-Handler
/select為一個URI。solr服務在接受到這個請求的時候,就會根據”/select”這段URI來選擇對應的RequestHandler。
common
| 參數 | 描述 | 用法 |
|---|---|---|
| q | 這是Apache Solr的主要查詢參數,文檔根據它們與此參數中的術語的相似性來評分。 | * : * |
| fq | 這個參數表示Apache Solr的過濾器查詢,將結果集限制為與此過濾器匹配的文檔。 | |
| sort | 這個參數指定由逗號分隔的字段列表,根據該列表對查詢的結果進行排序。 | id desc,price asc |
| start | start參數表示頁面的起始偏移量,此參數的默認值為0。若為1,表示從第二條記錄中檢索記錄 | 1 |
| rows | 這個參數表示每頁要檢索的文檔的數量。此參數的默認值為10。例如,可以通過將值2傳遞到參數行(row),將查詢結果中的記錄總數限制為2。 | 2 |
| fl | 這個參數為結果集中的每個文檔指定返回的字段列表。如果想在結果文檔中顯示指定字段,則需要傳遞必填寫的字段列表,用逗號分隔,作為屬性fl的值。 | id,content |
| df | ||
| Raw Query Parameters | ||
| wt | 這個參數表示要查看響應結果的寫入程序的類型。選擇一個來獲取所需文檔類型的響應。 | json、xml |
| indent | 返回的結果是否縮進,默認關閉,用 indent=true | on 開啟,一般調試json,php,ruby輸出才有必要用這個參數。 | indent=true | on |
| debugQuery | 設置返回結果是否顯示Debug信息。 | |
| dismax | ||
| edismax | ||
| hl | 開啟高亮顯示 | |
| hl.fl | 要高亮顯示的域 | |
| hl.simple.pre | 高亮顯示的前綴 | |
| hl.simple.post | 高亮顯示的后綴 | |
| spatial | ||
| spellcheck |
至此,solr的安裝與部署就講完了,相信你們對solr也有了一定的了解,這是solr學習的第一篇,我打算一共寫三篇文章來講解solr,分別是【solr的安裝與部署】【solr同步mongodb數據】【ssm項目整合solr】,把我在項目中使用solr的心得都分享出來。
Solr8.2.0下載鏈接:鏈接: https://pan.baidu.com/s/19HQOeXmYAesYH0UfNDwFgA 提取碼: a3qs
