這個世界已然被數據淹沒。多年來,我們系統間流轉和產生的大量數據已讓我們不知所措。 現有的技術都集中在如何解決數據倉庫存儲以及如何結構化這些數據。 這些看上去都挺美好,直到你實際需要基於這些數據實時做決策分析的時候才發現根本不是那么一回事。
Elasticsearch是一款十分強大的開源搜索引擎,可以幫助你在海量數據中搜索到目標,使用機器學習自動發現異常數據,對數據報表等強大功能。
在大數據的時代,掌握強大的實時搜索和分析能力,才能掌握核心競爭力。
如果你使用過Github的搜索功能,應該會深有體會Elasticsearch的強大,從近百億代碼中快速對你的關鍵詞進行匹配,
相比於Hadoop,ES具有更高的性能,而且很容易進行擴展和安裝。
環境搭建
ES需要使用Java的開發環境,所以需要配置JDK環境變量(這個不用多說了吧)。
然后解壓ES安裝包,在cmd中進入ES的bin目錄下,執行elasticsearch.bat即可。
ES使用了9200端口,可以在本地訪問localhost:9200來查看。
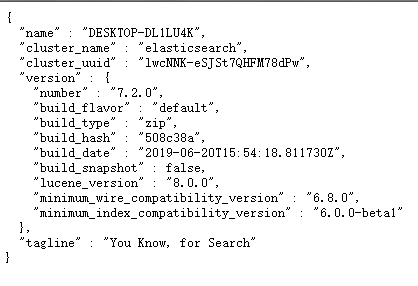
它會返回當前ES的節點信息。
ES的操作都是基於REST API的,我們可以使用一個可視化工具Kibana。
同樣也是解壓,然后在bin目錄下執行kibana.bat。
訪問localhost:5601就可以進入管理平台。
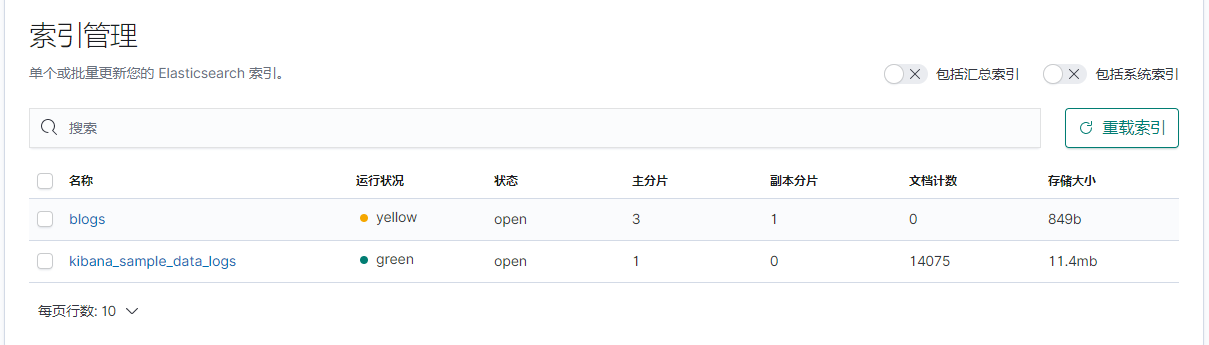
索引是文檔的容器,存放一類文檔的集合,類似於數據庫中表的概念,里面存放了一條條的數據。
在開發工具DEV Tool中我們可以操作索引。
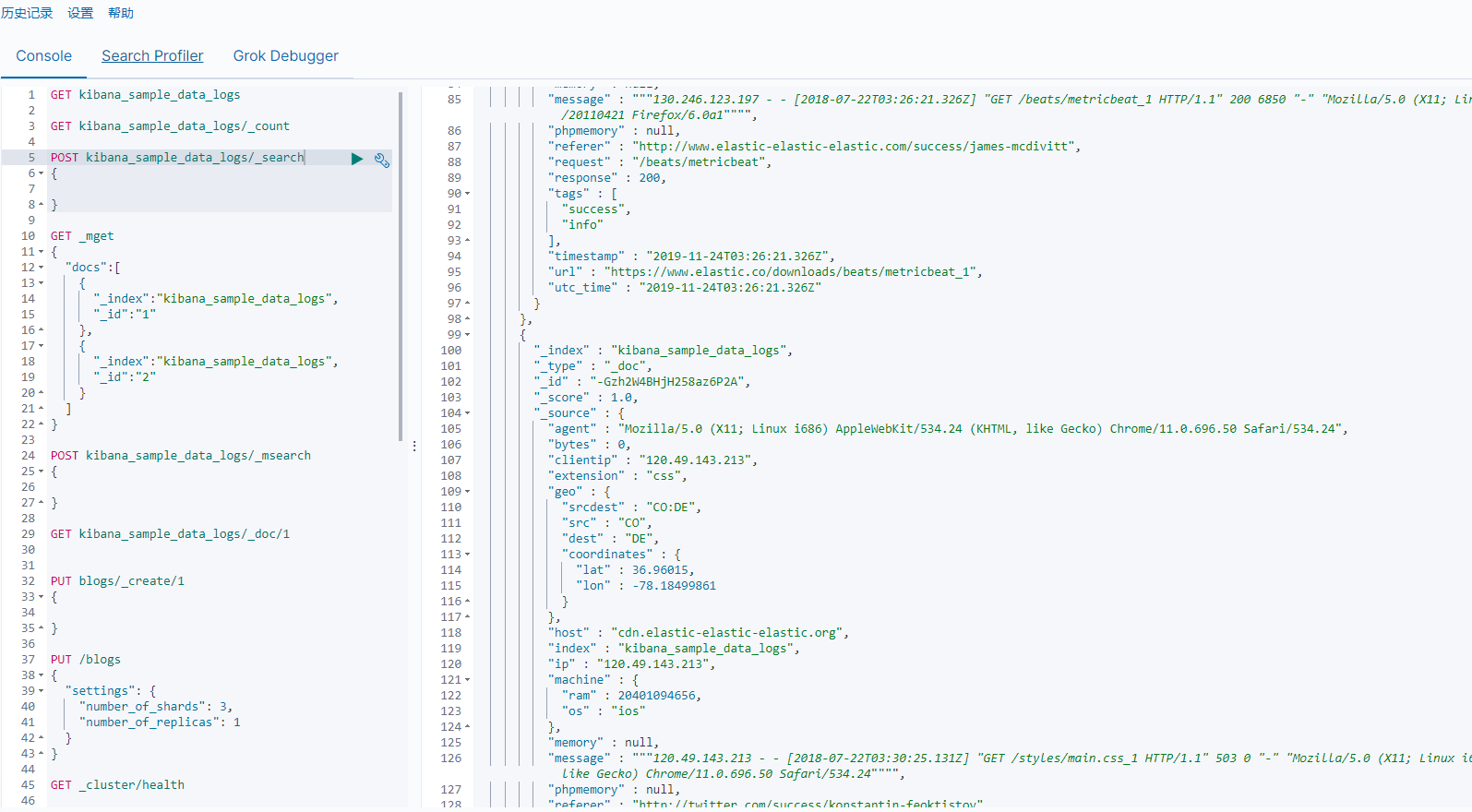
文檔的CRUD
類似於數據庫,ES中也存在了CRUD操作,每一條記錄就是一條文檔。
操作存在Index,Create,Update,Delete,Read。
Index和Create都是創建一條文檔,不過Index的意思是索引(動詞),如果文檔已存在,就刪除現有的,再重新創建,版本增加。Create可以自己制定文檔ID,如果ID存在,就會失敗,如果不存在,就創建新的文檔。

Index和Create請求方式有點繞,最好還是自己在DEV Tool中測試一下。
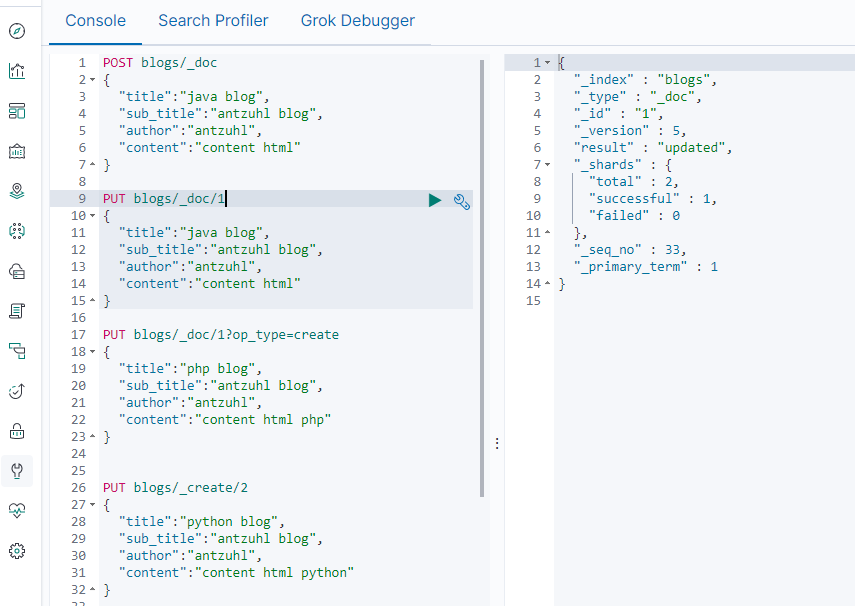
Update方法必須文檔已經存在,對文檔字段進行增量更新,添加字段或修改字段內容,並且版本號增加。
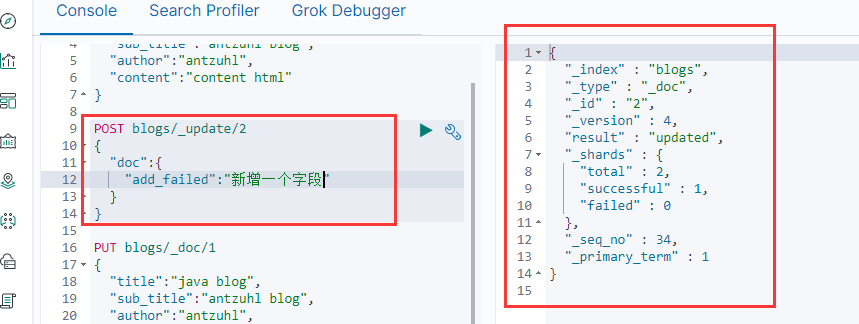
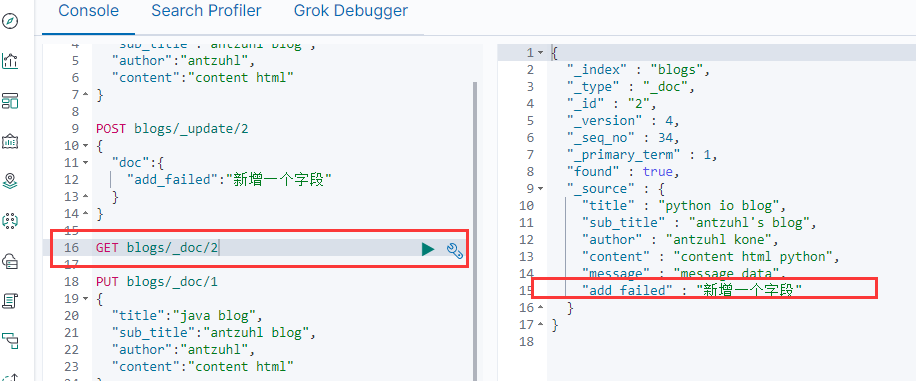
Read方法比較簡單,只需要用GET請求來指定文檔ID即可,如上圖。
Delete方法類似於Read,指定文檔ID即可。
Elasticsearch分詞
ES有一個非常強大的功能,就是內置分詞器,支持數十個國家的語言。
Analysis,文本分析,把全文本轉化為一系列單詞,基於Analyzer實現。
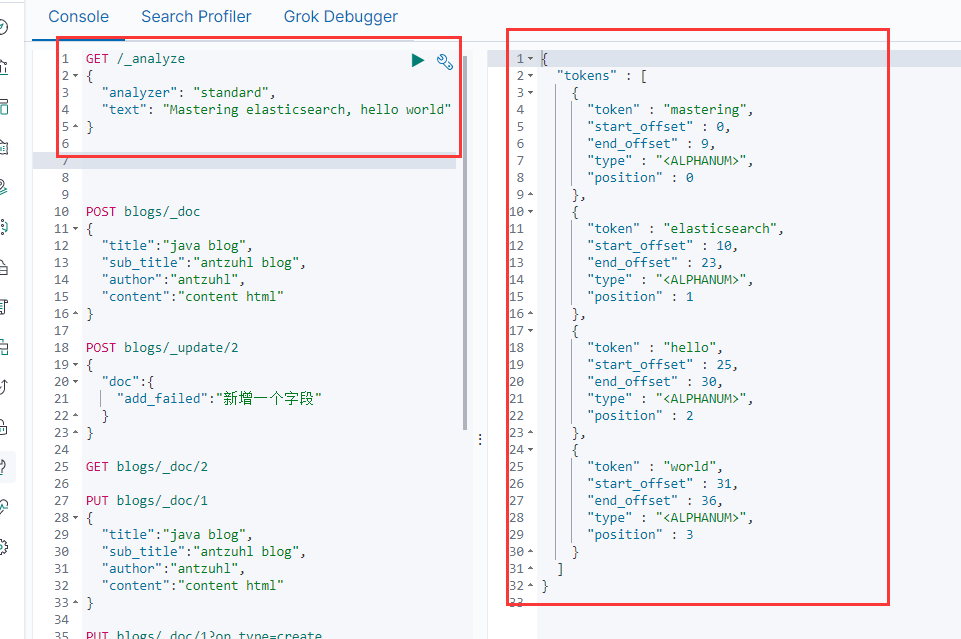
ES中有多種分詞器,standard是按詞切分,將單詞切分成單個token。
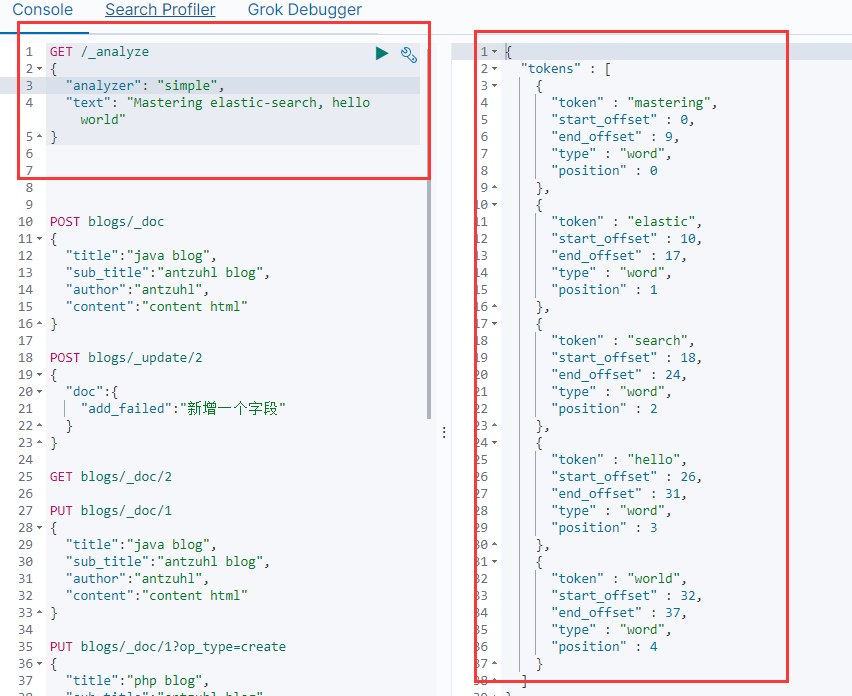
simple會根據非字母的單詞進行拆分,並進行大小寫轉換。
whitespace會按照空格來進行拆分,不做其他處理。
stop想必simple Analyzer會把the,is,a等修飾詞去除。
keyword會直接把一個輸入當做輸出來處理。
pattern是通過正則表達式進行分詞,默認按照\W非字母的符號進行分割,並進行大小寫轉換。
Search-API
在ES中使用Search有多種方法,一種是把參數帶在URL中使用GET方法請求的URI Search,另一種是把請求參數以JSON格式放在Body中的請求方式。
在search時,需要在URL中使用/_search來請求。
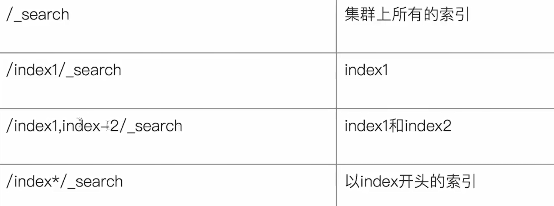
- URI Search
使用q來指定查詢字符串,df指定要查詢的字段,不指定df會默認對所有字段進行查詢。
sort指定根據哪個字段排序,from和size用於分頁,profile可以查看search是如何執行的。
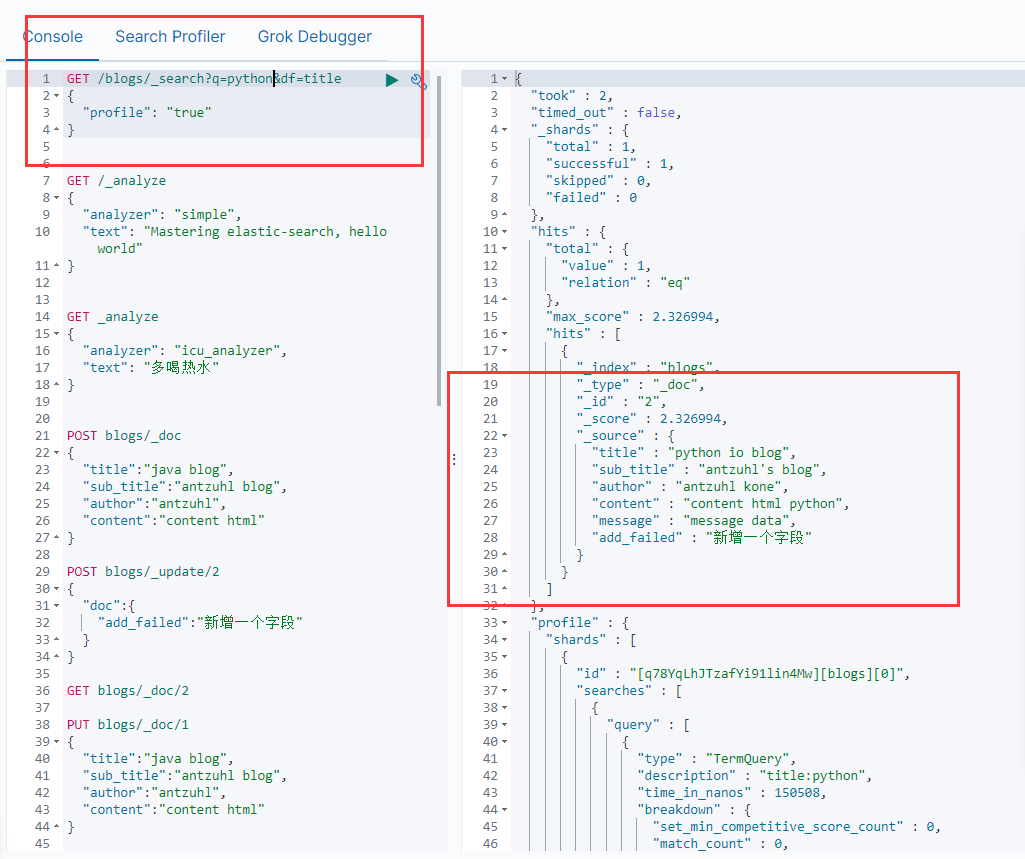
也可以不加df字段,直接使用?q=title:java來指定字段。
q字段查詢的條件如果是兩個單詞,比如說Java Blog,如果要求查詢結果中連續的話,就需要在查詢時用引號包住。
?q=title:"Java Blog", Java AND Blog。
?q=title:Java Blog, title:Java OR 其他字段:Blog。
?q=title:(Java Blog),title:Java OR title:Blog。
?q=title:(Java -Blog),title:Java OR title:Blog。
- Request Body Search
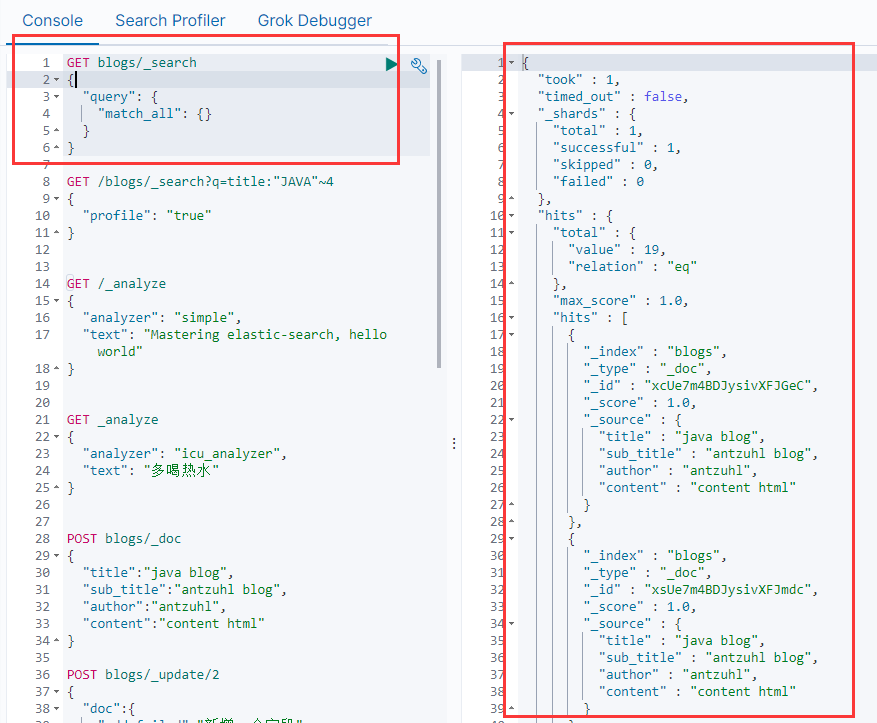
Request Body Search可以做比URI Search更高級的操作。
match_all查詢所有。
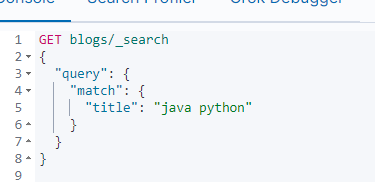
可以使用match進行匹配查詢。
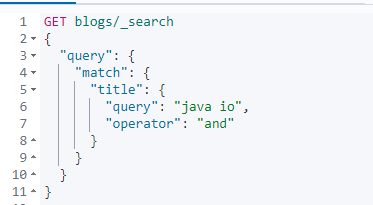
如下默認是java or python。
如果要指定and和or條件,可以指定operator。