ref: http://www.mobabel.net/%E6%80%BB%E7%BB%93redis%E7%83%AD%E7%82%B9key%E5%8F%91%E7%8E%B0%E5%8F%8A%E5%B8%B8%E8%A7%81%E8%A7%A3%E5%86%B3%E6%96%B9%E6%A1%88/
一、熱點Key問題產生的原因
1、用戶消費的數據遠大於生產的數據(熱賣商品、熱點新聞、熱點評論、明星直播)。
在日常工作生活中一些突發的的事件,例如:雙十一期間某些熱門商品的降價促銷,當這其中的某一件商品被數萬次點擊瀏覽或者購買時,會形成一個較大的需求量,這種情況下就會造成熱點問題。
同理,被大量刊發、瀏覽的熱點新聞、熱點評論、明星直播等,這些典型的讀多寫少的場景也會產生熱點問題。
2、請求分片集中,超過單 Server 的性能極限。
在服務端讀數據進行訪問時,往往會對數據進行分片切分,此過程中會在某一主機 Server 上對相應的 Key 進行訪問,當訪問超過 Server 極限時,就會導致熱點 Key 問題的產生。
二、熱點Key問題的危害
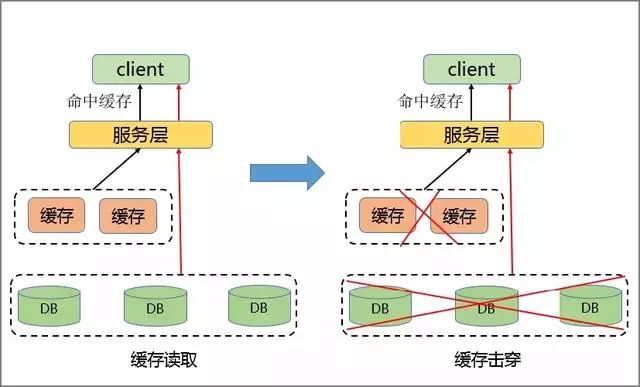
1、流量集中,達到物理網卡上限。
2、請求過多,緩存分片服務被打垮。
3、DB 擊穿,引起業務雪崩。
如前文講到的,當某一熱點 Key 的請求在某一主機上超過該主機網卡上限時,由於流量的過度集中,會導致服務器中其它服務無法進行。
如果熱點過於集中,熱點 Key 的緩存過多,超過目前的緩存容量時,就會導致緩存分片服務被打垮現象的產生。
當緩存服務崩潰后,此時再有請求產生,會緩存到后台 DB 上,由於DB 本身性能較弱,在面臨大請求時很容易發生請求穿透現象,會進一步導致雪崩現象,嚴重影響設備的性能。
三、解決方案
通常的解決方案主要集中在對客戶端和 Server 端進行相應的改造。
1、服務端緩存方案
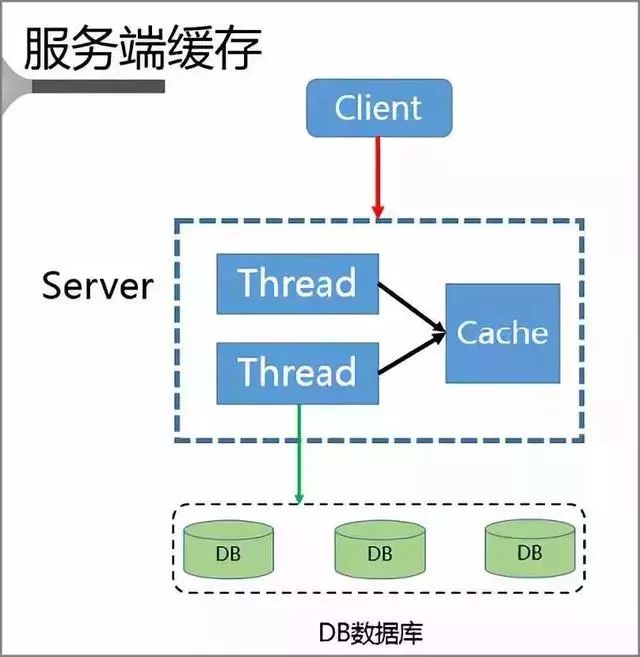
首先 Client 會將請求發送至 Server 上,而 Server 又是一個多線程的服務,本地就具有一個基於 Cache LRU 策略的緩存空間。
當 Server 本身就擁堵時,Server 不會將請求進一步發送給 DB 而是直接返回,只有當 Server 本身暢通時才會將 Client 請求發送至 DB,並且將該數據重新寫入到緩存中。
此時就完成了緩存的訪問跟重建。
但該方案也存在以下問題:
- 緩存失效,多線程構建緩存問題
- 緩存丟失,緩存構建問題
- 臟讀問題
2、使用 Memcache、Redis 方案
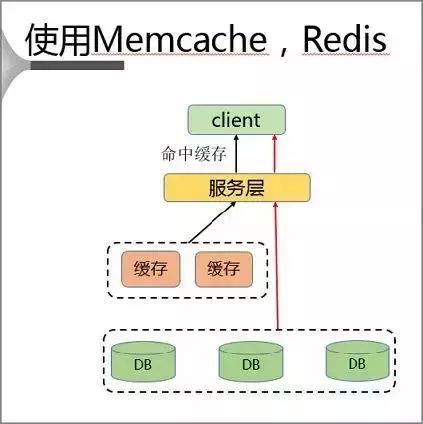
該方案通過在客戶端單獨部署緩存的方式來解決熱點 Key 問題。
使用過程中 Client 首先訪問服務層,再對同一主機上的緩存層進行訪問。
該種解決方案具有就近訪問、速度快、沒有帶寬限制的優點,但是同時也存在以下問題:
- 內存資源浪費
- 臟讀問題
3、使用本地緩存方案
使用本地緩存則存在以下問題:
- 需要提前獲知熱點
- 緩存容量有限
- 不一致性時間增長
- 熱點 Key 遺漏
傳統的熱點解決方案都存在各種各樣的問題,那么究竟該如何解決熱點問題呢?
4、讀寫分離方案解決熱讀
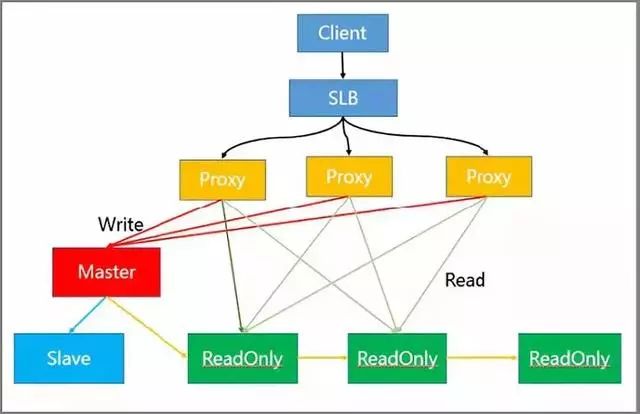
架構中各節點的作用如下:
- SLB 層做負載均衡
- Proxy 層做讀寫分離自動路由
- Master 負責寫請求
- ReadOnly 節點負責讀請求
- Slave 節點和 Master 節點做高可用
實際過程中 Client 將請求傳到 SLB,SLB 又將其分發至多個 Proxy 內,通過 Proxy 對請求的識別,將其進行分類發送。
例如,將同為 Write 的請求發送到 Master 模塊內,而將 Read 的請求發送至 ReadOnly 模塊。
而模塊中的只讀節點可以進一步擴充,從而有效解決熱點讀的問題。
讀寫分離同時具有可以靈活擴容讀熱點能力、可以存儲大量熱點Key、對客戶端友好等優點。
5、熱點數據解決方案
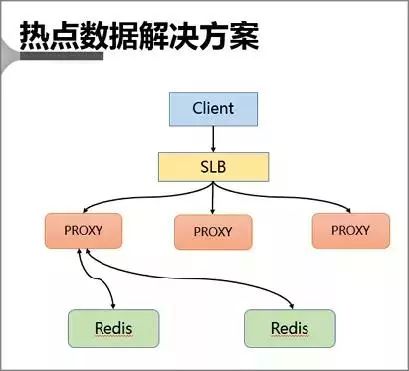
該方案通過主動發現熱點並對其進行存儲來解決熱點 Key 的問題。
首先 Client 也會訪問 SLB,並且通過 SLB 將各種請求分發至 Proxy 中,Proxy 會按照基於路由的方式將請求轉發至后端的 Redis 中。
在熱點 key 的解決上是采用在服務端增加緩存的方式進行。
具體來說就是在 Proxy 上增加本地緩存,本地緩存采用 LRU 算法來緩存熱點數據,后端 db 節點增加熱點數據計算模塊來返回熱點數據。
- Proxy 架構的主要有以下優點:
- Proxy 本地緩存熱點,讀能力可水平擴展
- DB 節點定時計算熱點數據集合
- DB 反饋 Proxy 熱點數據
- 對客戶端完全透明,不需做任何兼容
四、熱點 key 處理
1、熱點數據的讀取
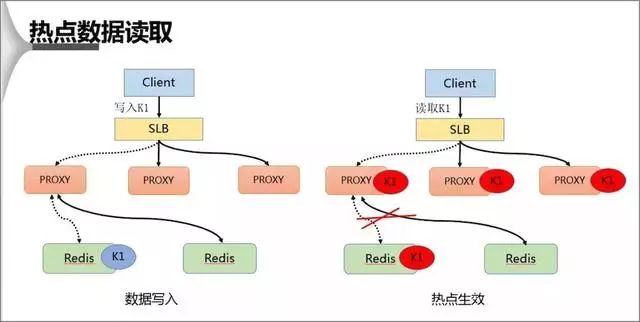
在熱點 Key 的處理上主要分為寫入跟讀取兩種形式,在數據寫入過程當 SLB 收到數據 K1 並將其通過某一個 Proxy 寫入一個 Redis,完成數據的寫入。
假若經過后端熱點模塊計算發現 K1 成為熱點 key 后, Proxy 會將該熱點進行緩存,當下次客戶端再進行訪問 K1 時,可以不經 Redis。
最后由於 proxy 是可以水平擴充的,因此可以任意增強熱點數據的訪問能力。
2、熱點數據的發現
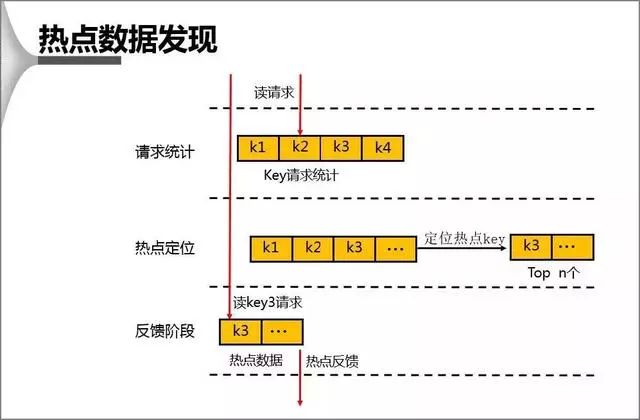
對於 db 上熱點數據的發現,首先會在一個周期內對 Key 進行請求統計,在達到請求量級后會對熱點 Key 進行熱點定位,並將所有的熱點 Key 放入一個小的 LRU 鏈表內,在通過 Proxy 請求進行訪問時,若 Redis 發現待訪點是一個熱點,就會進入一個反饋階段,同時對該數據進行標記。
DB 計算熱點時,主要運用的方法和優勢有:
1、基於統計閥值的熱點統計
2、基於統計周期的熱點統計
3、基於版本號實現的無需重置初值統計方法
4、DB 計算同時具有對性能影響極其微小、內存占用極其微小等優點
五、方案對比
通過上述對比分析可以看出,在解決熱點 Key 上較傳統方法相比都有較大的提高,無論是基於讀寫分離方案還是熱點數據解決方案,在實際處理環境中都可以做靈活的水平能力擴充、都對客戶端透明、都有一定的數據不一致性。
此外讀寫分離模式可以存儲更大量的熱點數據,而基於 Proxy 的模式有成本上的優勢。
六、 案例
其實這里關鍵的一點,就是對於這種熱點緩存,你的系統需要能夠在熱點緩存突然發生的時候,直接發現他,然后瞬間立馬實現毫秒級的自動負載均衡。
那么我們就先來說說,你如何自動發現熱點緩存問題?
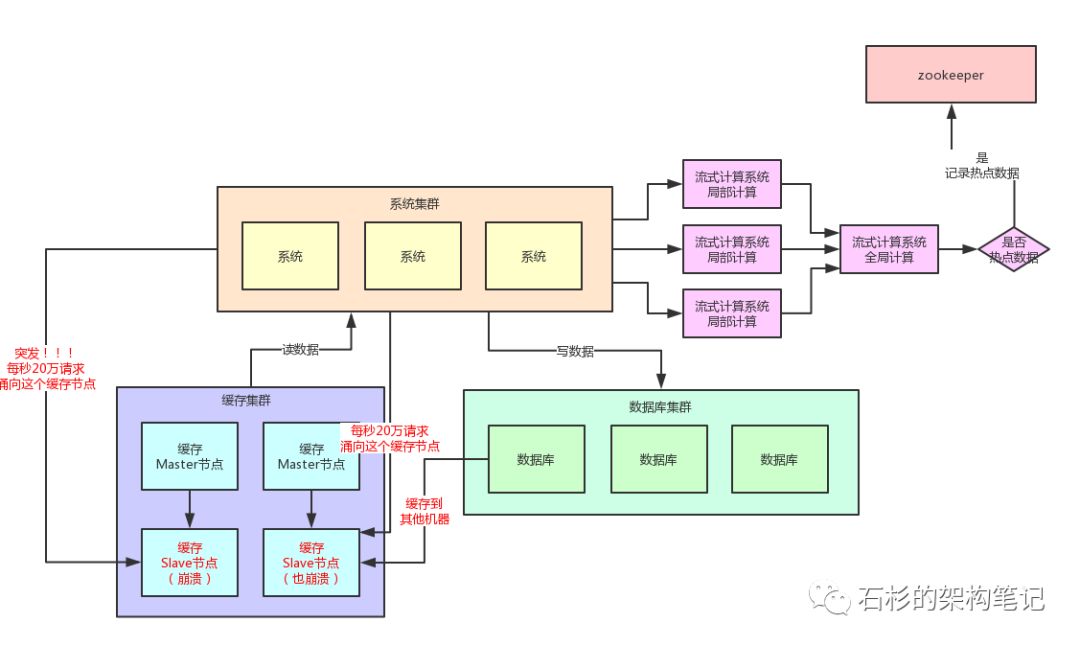
首先你要知道,一般出現緩存熱點的時候,你的每秒並發肯定是很高的,可能每秒都幾十萬甚至上百萬的請求量過來,這都是有可能的。
所以,此時完全可以基於大數據領域的流式計算技術來進行實時數據訪問次數的統計,比如storm、spark streaming、flink,這些技術都是可以的。
然后一旦在實時數據訪問次數統計的過程中,比如發現一秒之內,某條數據突然訪問次數超過了1000,就直接立馬把這條數據判定為是熱點數據,可以將這個發現出來的熱點數據寫入比如zookeeper中。
當然,你的系統如何判定熱點數據,可以根據自己的業務還有經驗值來就可以了。
大家看看下面這張圖,看看整個流程是如何進行的。
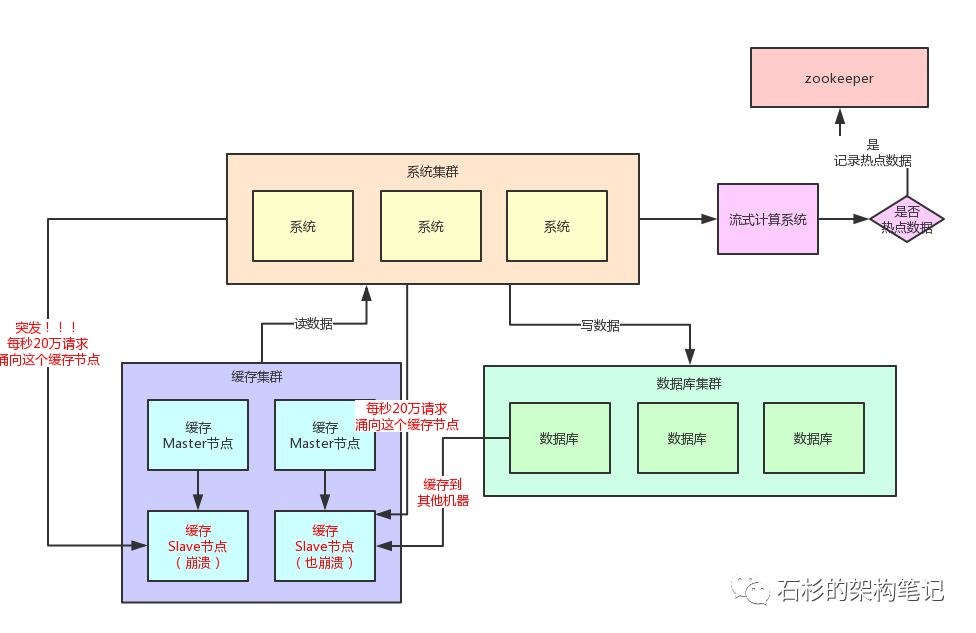
當然肯定有人會問,那你的流式計算系統在進行數據訪問次數統計的時候,會不會也存在說單台機器被請求每秒幾十萬次的問題呢?
答案是否,因為流式計算技術,尤其是storm這種系統,他可以做到同一條數據的請求過來,先分散在很多機器里進行本地計算,最后再匯總局部計算結果到一台機器進行全局匯總。
所以幾十萬請求可以先分散在比如100台機器上,每台機器統計了這條數據的幾千次請求。
然后100條局部計算好的結果匯總到一台機器做全局計算即可,所以基於流式計算技術來進行統計是不會有熱點問題的。
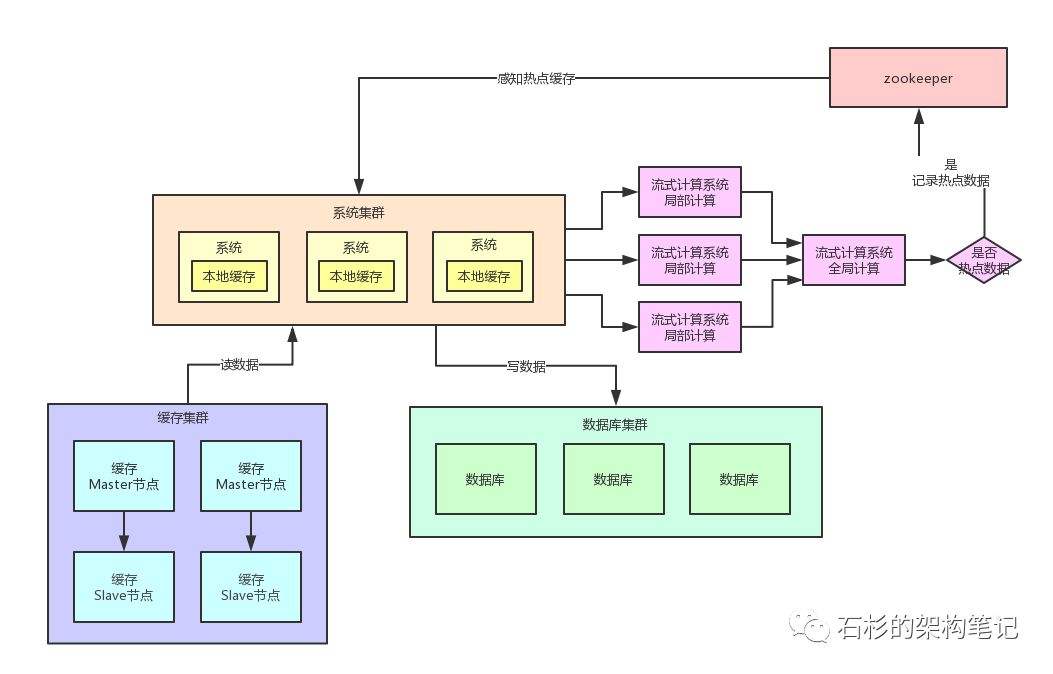
熱點緩存自動加載為JVM本地緩存
我們自己的系統可以對zookeeper指定的熱點緩存對應的znode進行監聽,如果有變化他立馬就可以感知到了。
此時系統層就可以立馬把相關的緩存數據從數據庫加載出來,然后直接放在自己系統內部的本地緩存里即可。
這個本地緩存,你用ehcache、hashmap,其實都可以,一切都看自己的業務需求,主要說的就是將緩存集群里的集中式緩存,直接變成每個系統自己本地實現緩存即可,每個系統自己本地是無法緩存過多數據的。
因為一般這種普通系統單實例部署機器可能就一個4核8G的機器,留給本地緩存的空間是很少的,所以用來放這種熱點數據的本地緩存是最合適的,剛剛好。
假設你的系統層集群部署了100台機器,那么好了,此時你100台機器瞬間在本地都會有一份熱點緩存的副本。
然后接下來對熱點緩存的讀操作,直接系統本地緩存讀出來就給返回了,不用再走緩存集群了。
這樣的話,也不可能允許每秒20萬的讀請求到達緩存機器的一台機器上讀一個熱點緩存了,而是變成100台機器每台機器承載數千請求,那么那數千請求就直接從機器本地緩存返回數據了,這是沒有問題的。
我們再來畫一幅圖,一起來看看這個過程:
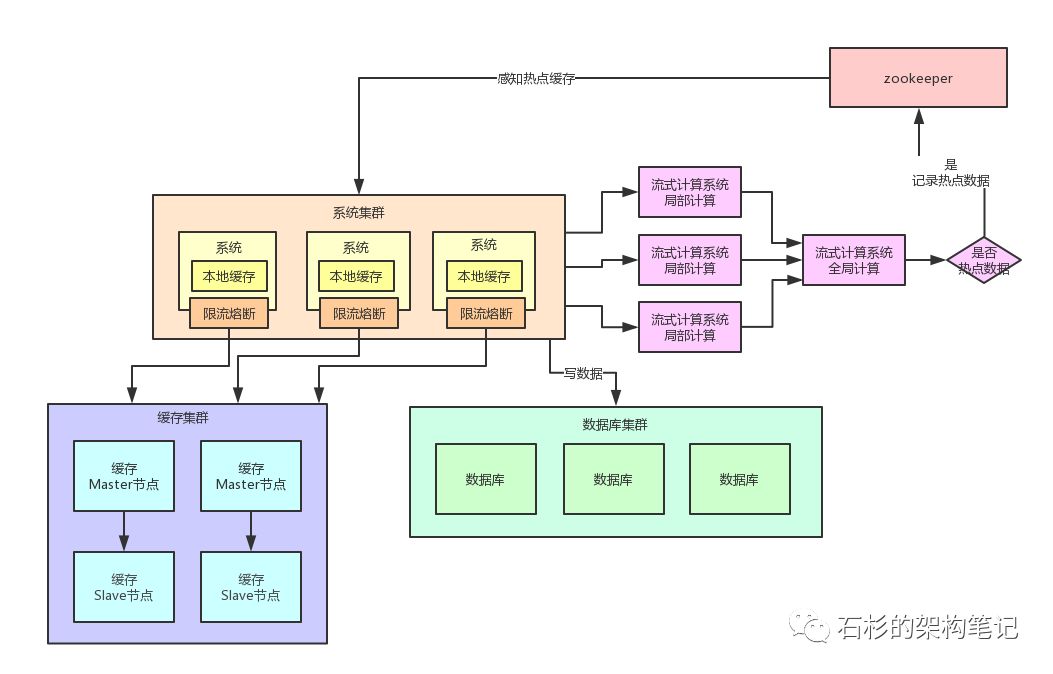
限流熔斷保護
除此之外,在每個系統內部,其實還應該專門加一個對熱點數據訪問的限流熔斷保護措施。
每個系統實例內部,都可以加一個熔斷保護機制,假設緩存集群最多每秒承載4萬讀請求,那么你一共有100個系統實例。
你自己就該限制好,每個系統實例每秒最多請求緩存集群讀操作不超過400次,一超過就可以熔斷掉,不讓請求緩存集群,直接返回一個空白信息,然后用戶稍后會自行再次重新刷新頁面之類的。
通過系統層自己直接加限流熔斷保護措施,可以很好的保護后面的緩存集群、數據庫集群之類的不要被打死,我們來看看下面的圖。
還看到一種方案:
可以用分布式流式計算出熱點數據。