看完這篇就懂了。
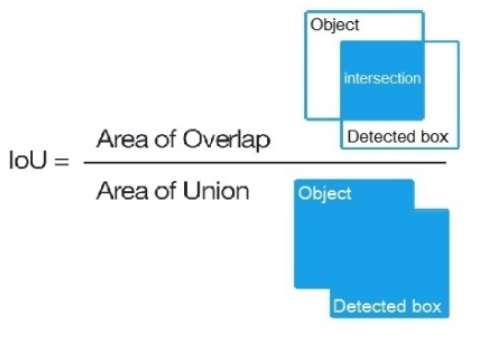
IoU
intersect over union,中文:交並比。指目標預測框和真實框的交集和並集的比例。
mAP
mean average precision。是指每個類別的平均查准率的算術平均值。即先求出每個類別的平均查准率(AP),然后求這些類別的AP的算術平均值。其具體的計算方法有很多種,這里只介紹PASCAL VOC競賽(voc2010之前)中采用的mAP計算方法,該方法也是yolov3模型采用的評估方法,yolov3項目中如此解釋mAP,暫時看不明白可以先跳過,最后再回過頭來看就能明白了。

比如我們現在要在一個給定的測試樣本集中計算貓這個類別的AP,過程如下:
首先,AP要能概括P-R曲線的形狀,其被定義為采用如下公式來計算:
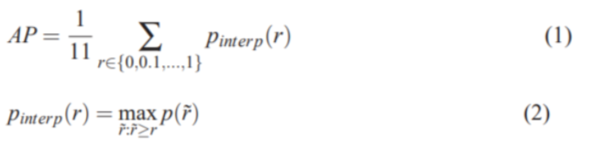
那么,我們先來看看P-R曲線是什么:用藍色筆跡遮住的部分不需要關注。
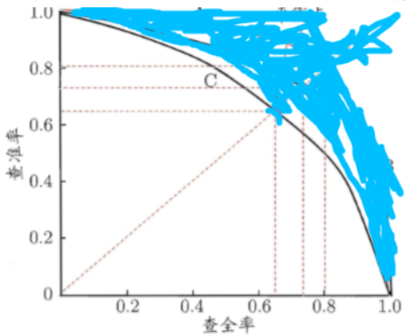
圖中的曲線C就是一條P-R曲線,P表示縱軸的查准率precision,R表示橫軸的召回率或稱為查全率recall。P-R曲線下的面積可以用於評估該曲線對應的模型的能力,也就是說比較2個目標檢測模型哪個更好,可以用P-R曲線面積來比較,面積越大模型越好。然而可能是因為這個面積並不好計算,所以定義了公式(1)來計算出一個叫AP的東西,反正這個東西也能體現出precision和recall對模型能力的綜合影響。
從公式(2)可以知曉,Pinterpo(r)表示所有大於指定召回率r的召回率rhat所對應的的p的最大值。大於某個r的rhat有很多,我們要找到這些rhat中所對應的p是最大的那個,然后返回這個p。公式(1)中規定了r會從0-1.0以0.1為步長取11個值,然后將這11個r對應的11個p累加求算術平均值就得到了AP。所以我們要先得到一組rhat和p,這需要我們先了解recall和precision是如何計算的。
我們先來看看P(precision)和R(recall)的計算公式:
precision = TP / (TP+FP)
recall = TP / (TP+FN)
TP是檢測對了的正樣本,FP是檢測錯了的正樣本,FN是漏檢的正樣本。
對於目標檢測模型一般最后都會輸出一個置信度(如果樣本圖片中有不止一個目標,本例中只選擇貓類別的置信度即可),所以可以設置一個置信度閾值,比如0.6,那么高於0.6的就認為該樣本被檢測為了正樣本(即檢測為貓),這樣我們會得到0.6閾值下的一組正樣本。
然后在這組正樣本的基礎上,設定一個IoU的閾值,其值為0.5(意思是檢測為貓的目標的預測邊界框和真實邊界框的交並比要大於0.5),大於該閾值的認為是TP,其它的認為是FP。然后用測試樣本中真實的正樣本數量減去TP,就得到了FN。
這樣,在置信度閾值為0.6的情況下,我們就得到了一對P(precision)和R(recall),接着我們取不同的置信度閾值,得到更多的P-R對,然后根據公式(2)找到所有大於指定召回率r的召回率rhat所對應的的p的最大值(采用這種方法是為了保證P-R曲線是單調遞減的,避免搖擺),作為當前指定召回率r條件下的最大查准率p,然后根據公式(1)計算出AP。這個AP就是貓這個類別的AP,接着我們可以計算其它類別的AP,然后對這些AP求算術平均值,就得到了mAP。
了解了mAP之后,我們就容易理解為什么目標檢測模型的度量指標不能像圖像分類模型那樣直接計算一遍precision和recall,因為目標檢測任務中會包含多個類別的目標,並且除了給目標分類,還要預測目標的邊界框,所以要加入IoU的概念,並考慮多個類別,而mAP就是在考慮了IoU和多類別之后計算出的度量指標。
參考文獻:
http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
https://github.com/AlexeyAB/darknet