有什么用?
大家看一個例子。
一個文本文件里面存儲了 一些市場職位信息,格式如下所示
Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員
測試開發工程師(C++/python) 上海墨鵾數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員
Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人
測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人
Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人
python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員
現在,我們需要寫一個程序,從這些文本里面抓取 所有職位的薪資。
就是要獲取這樣的結果
2
2.5
1.3
1.1
2.8
2.5
怎么做?
大家先自己思考一下。
這是典型的字符串處理。
分析這里面的規律,可以發現,薪資的數字 后面 都有關鍵字 萬/月 或者 萬/每月
根據我們學過的知識,我們不難寫出下面的代碼
content = ''' Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員 測試開發工程師(C++/python) 上海墨鵾數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員 Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人 測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人 Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人 python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員 '''
# 將文本內容按行放入列表
lines = content.splitlines() for line in lines: # 查找'萬/月' 在 字符串中什么地方
pos2 = line.find('萬/月') if pos2 < 0: # 查找'萬/每月' 在 字符串中什么地方
pos2 = line.find('萬/每月') # 都找不到
if pos2 < 0: continue
# 執行到這里,說明可以找到薪資關鍵字
# 接下來分析 薪資 數字的起始位置
# 方法是 找到 pos2 前面薪資數字開始的位置
idx = pos2-1
# 只要是數字或者小數點,就繼續往前面找
while line[idx].isdigit() or line[idx]=='.': idx -= 1
# 現在 idx 指向 薪資數字前面的那個字,
# 所以薪資開始的 索引 就是 idx+1
pos1 = idx + 1
print(line[pos1:pos2])
運行一下,發現完全可以。
在你高興完之后,我們再看看寫的代碼。
怎么樣?
太麻煩了,是不是。
為了從每行獲取薪資對應的數字,我們 可是 寫了不少行代碼。
這種 從字符串中搜索出某種特征的子串 有沒有更簡單的方法呢?
解決方案就是我們今天要介紹的 正則表達式 。
如果我們使用正則表達式,代碼可以這樣
content = ''' Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員 測試開發工程師(C++/python) 上海墨鵾數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員 Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人 測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人 Python高級開發工程師 上海行動教育科技股份有限公司上海-閔行區2.8萬/月02-18剩余255人 python開發工程師 上海優似騰軟件開發有限公司上海-浦東新區2.5萬/每月02-18滿員 '''
import re p = re.compile(r'([\d.]+)萬/每{0,1}月') for one in p.findall(content): print(one)
運行一下看看,結果是一樣的。
但是代碼卻簡單多了。
正則表達式,是一種語法,用來描述你想搜索的字符串的特征。
下面這行代碼指定了一個正則表達式
p = re.compile(r'([\d.]+)萬/每{0,1}月')
compile 函數的參數,就是正則表達式字符串。
上面的例子里面指定了 搜索子串的特征 是 ([\d.]+)萬/每{0,1}月
為什么這么寫? 我們后面再介紹。
這個函數返回一個compile對象。
compile對象的 findall 方法返回所有匹配的子串,放在一個列表中。
使用正則表達式關鍵的地方在於, 如何寫出正確的表達式語法 。
正則表達式非常強大,語法非常復雜,點擊這里,參考Python官方文檔里面的描述 。具體的使用細節包括語法都在里面。
在線驗證
怎么驗證你寫的表達式 是否能正確匹配到要搜索的字符串呢?
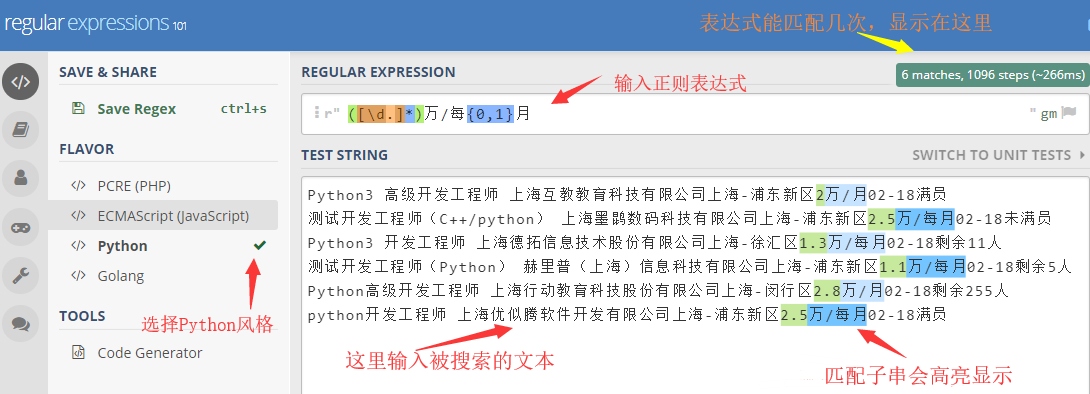
大家可以訪問這個網址: https://regex101.com/
按照下面的示意圖片輸入 搜索文本 和 表達式,查看你的表達式是否能正確匹配到字符串。
常見語法
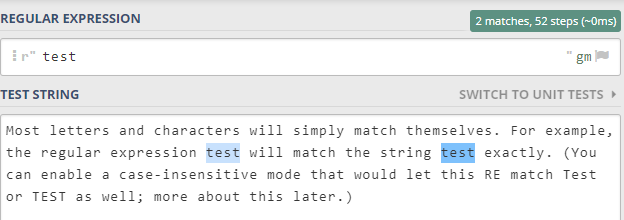
寫在正則表達式里面的普通字符都是表示: 直接匹配它們。
比如 你下面的文本中,如果你要找所有的 test, 正則表達式就非常簡單,直接輸入 test 即可。
如下所示:
漢字也是一樣,要尋找漢字,直接寫在正則表達式里面就可以了。
但是有些特殊的字符,術語叫 metacharacters(元字符)。
它們出現在正則表達式字符串中,不是表示直接匹配他們, 而是表達一些特別的含義。
這些特殊的元字符包括下面這些:
. * + ? \ [ ] ^ $ { } | ( )
我們分別介紹一下它們的含義:
點-匹配所有字符
. 表示要匹配除了 換行符 之外的任何 單個 字符。
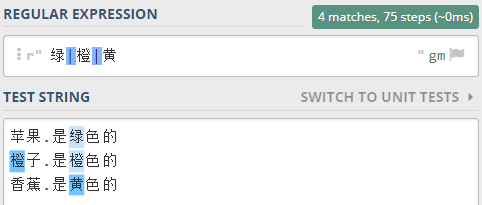
比如,你要從下面的文本中,選擇出所有的顏色。
蘋果是綠色的
橙子是橙色的
香蕉是黃色的
烏鴉是黑色的
也就是要找到所有 以 色 結尾,並且包括前面的一個字符的 詞語。
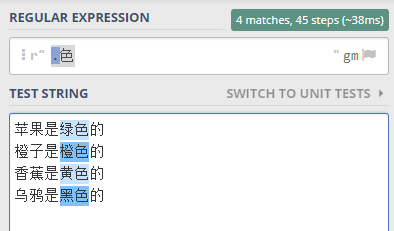
就可以這樣寫正則表達式 .色 。
其中 點 代表了任意的一個字符, 注意是一個字符。
.色 合起來就表示 要找 任意一個字符 后面是 色 這個字, 合起來兩個字的 字符串
驗證一下,如下圖所示
只要表達式正確,就可以寫在Python代碼中,如下所示
content = '''蘋果是綠色的 橙子是橙色的 香蕉是黃色的 烏鴉是黑色的'''
import re p = re.compile(r'.色') for one in p.findall(content): print(one)
運行結果如下
綠色
橙色
黃色
黑色
星號-重復匹配任意次
* 表示匹配前面的子表達式任意次,包括0次。
比如,你要從下面的文本中,選擇每行逗號后面的字符串內容,包括逗號本身。注意,這里的逗號是中文的逗號。
蘋果,是綠色的
橙子,是橙色的
香蕉,是黃色的
烏鴉,是黑色的
猴子,
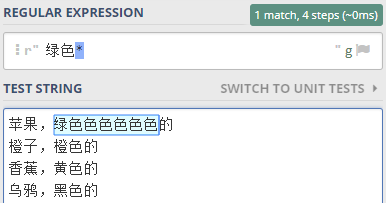
就可以這樣寫正則表達式 ,.* 。
- 緊跟在 . 后面, 表示 任意字符可以出現任意次, 所以整個表達式的意思就是在逗號后面的 所有字符,包括逗號
驗證一下,如下圖所示
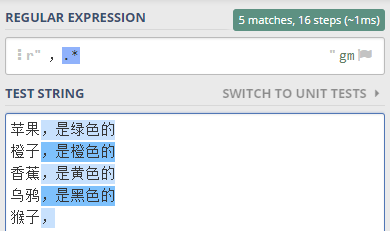
特別是最后一行,猴子逗號后面沒有其它字符了,但是*表示可以匹配0次, 所以表達式也是成立的。
只要表達式正確,就可以寫在Python代碼中,如下所示
content = '''蘋果,是綠色的 橙子,是橙色的 香蕉,是黃色的 烏鴉,是黑色的 猴子,'''
import re p = re.compile(r',.*') for one in p.findall(content): print(one)
運行結果如下
,是綠色的
,是橙色的
,是黃色的
,是黑色的
,
注意, .* 在正則表達式中非常常見,表示匹配任意字符任意次數。
當然這個 * 前面不是非得是 點 ,也可以是其它字符,比如
加號-重復匹配多次
+ 表示匹配前面的子表達式一次或多次,不包括0次。
比如,還是上面的例子,你要從文本中,選擇每行逗號后面的字符串內容,包括逗號本身。
但是 添加一個條件, 如果逗號后面 沒有內容,就不要選擇了。
比如,下面的文本中,最后一行逗號后面 沒有內容,就不要選擇了。
蘋果,是綠色的
橙子,是橙色的
香蕉,是黃色的
烏鴉,是黑色的
猴子,
就可以這樣寫正則表達式 ,.+ 。
驗證一下,如下圖所示
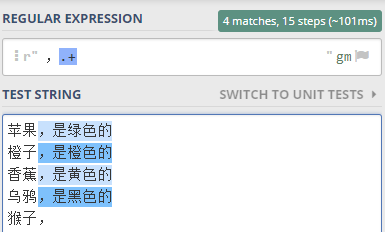
最后一行,逗號后面沒有其它字符了,+表示至少匹配1次, 所以最后一行沒有子串選中。
問號-匹配0-1次
? 表示匹配前面的子表達式0次或1次。
比如,還是上面的例子,你要從文本中,選擇每行逗號后面的1個字符,也包括逗號本身。
蘋果,綠色的
橙子,橙色的
香蕉,黃色的
烏鴉,黑色的
猴子,
就可以這樣寫正則表達式 ,.? 。
驗證一下,如下圖所示
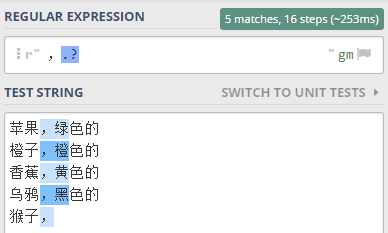
最后一行,逗號后面沒有其它字符了,但是?表示匹配1次或0次, 所以最后一行也選中了一個逗號字符。
花括號-匹配指定次數
花括號表示 前面的字符匹配 指定的次數 。
比如 ,下面的文本
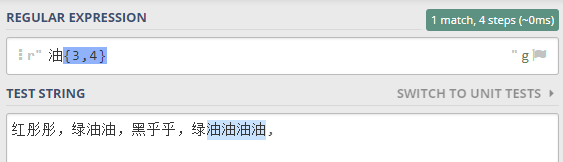
紅彤彤,綠油油,黑乎乎乎乎,綠油油油油
表達式 油{3} 就表示匹配 連續的 油 字 3次
表達式 油{3,4} 就表示匹配 連續的 油 字 至少3次,至多 4 次
就只能匹配 后面的,如下所示:
貪婪模式和非貪婪模式
我們要把下面的字符串中的所有html標簽都提取出來,
source = '<html><head><title>Title</title>'
得到這樣的一個列表
['<html>', '<head>', '<title>', '</title>']
很容易想到使用正則表達式 <.*>
寫出如下代碼
source = '<html><head><title>Title</title>'
import re p = re.compile(r'<.*>') print(p.findall(source))
但是運行結果,卻是
['<html><head><title>Title</title>']
怎么回事? 原來 在正則表達式中, ‘*’, ‘+’, ‘?’ 都是貪婪地,使用他們時,會盡可能多的匹配內容,
所以, <.*> 中的 星號(表示任意次數的重復),一直匹配到了 字符串最后的 </title> 里面的e。
解決這個問題,就需要使用非貪婪模式,也就是在星號后面加上 ? ,變成這樣 <.*?>
代碼改為
source = '<html><head><title>Title</title>'
import re # 注意多出的問號
p = re.compile(r'<.*?>') print(p.findall(source))
對元字符的轉義
反斜杠 \ 在正則表達式中有多種用途。
比如,我們要在下面的文本中搜索 所有點前面的字符串,也包含點本身
蘋果.是綠色的
橙子.是橙色的
香蕉.是黃色的
如果,我們這樣寫正則表達式 .*. , 聰明的你肯定發現不對勁。
因為 點 是一個 元字符, 直接出現在正則表達式中,表示匹配任意的單個字符, 不能表示 . 這個字符本身的意思了。
怎么辦呢?
如果我們要搜索的內容本身就包含元字符,就可以使用 反斜杠進行轉義。
這里我們就應用使用這樣的表達式: .*\.
示例,Python程序如下
content = '''蘋果.是綠色的 橙子.是橙色的 香蕉.是黃色的'''
import re p = re.compile(r'.*\.') for one in p.findall(content): print(one) 運行結果如下 蘋果. 橙子. 香蕉.
匹配某種字符類型
反斜杠后面接一些字符,表示匹配 某種類型 的一個字符。
比如
\d 匹配0-9之間任意一個數字字符,等價於表達式 [0-9]
\D 匹配任意一個不是0-9之間的數字字符,等價於表達式 [^0-9]
\s 匹配任意一個空白字符,包括 空格、tab、換行符等,等價於表達式 [\t\n\r\f\v]
\S 匹配任意一個非空白字符,等價於表達式 [^ \t\n\r\f\v]
\w 匹配任意一個文字字符,包括大小寫字母、數字、下划線,等價於表達式 [a-zA-Z0-9_]
缺省情況也包括 Unicode文字字符,如果指定 ASCII 碼標記,則只包括ASCII字母
\W 匹配任意一個非文字字符,等價於表達式 [^a-zA-Z0-9_]
反斜杠也可以用在方括號里面,比如 [\s,.] 表示匹配 : 任何空白字符, 或者逗號,或者點
方括號-匹配幾個字符之一
方括號表示要匹配 指定的幾個字符之一 。
比如
[abc] 可以匹配 a, b, 或者 c 里面的任意一個字符。等價於 [a-c] 。
[a-c] 中間的 - 表示一個范圍從a 到 c。
如果你想匹配所有的小寫字母,可以使用 [a-z]
一些 元字符 在 方括號內 失去了魔法, 變得和普通字符一樣了。
比如
[akm.] 匹配 a k m . 里面任意一個字符
這里 . 在括號里面不在表示 匹配任意字符了,而就是表示匹配 . 這個 字符
如果在方括號中使用 ^ , 表示 非 方括號里面的字符集合。
比如
content = 'a1b2c3d4e5'
import re p = re.compile(r'[^\d]' ) for one in p.findall(content): print(one)
[^\d] 表示,選擇非數字的字符
輸出結果為:
a
b
c
d
e
起始、結尾位置 和 單行、多行模式
^ 表示匹配文本的 開頭 位置。
正則表達式可以設定 單行模式 和 多行模式
如果是 單行模式 ,表示匹配 整個文本 的開頭位置。
如果是 多行模式 ,表示匹配 文本每行 的開頭位置。
比如,下面的文本中,每行最前面的數字表示水果的編號,最后的數字表示價格
001-蘋果價格-60, 002-橙子價格-70, 003-香蕉價格-80,
如果我們要提取所有的水果編號,用這樣的正則表達式 ^\d+
上面的正則表達式,使用在Python程序里面,如下所示
content = '''001-蘋果價格-60 002-橙子價格-70 003-香蕉價格-80'''
import re p = re.compile(r'^\d+', re.M) for one in p.findall(content): print(one)
注意,compile 的第二個參數 re.M ,指明了使用多行模式,
運行結果如下
001
002
003
如果,去掉 compile 的第二個參數 re.M, 運行結果如下
001
就只有第一行了。
因為單行模式下,^ 只會匹配整個文本的開頭位置。
$ 表示匹配文本的 結尾 位置。
如果是 單行模式 ,表示匹配 整個文本 的結尾位置。
如果是 多行模式 ,表示匹配 文本每行 的結尾位置。
比如,下面的文本中,每行最前面的數字表示水果的編號,最后的數字表示價格
001-蘋果價格-60, 002-橙子價格-70, 003-香蕉價格-80,
如果我們要提取所有的水果編號,用這樣的正則表達式 \d+$
對應代碼
content = '''001-蘋果價格-60 002-橙子價格-70 003-香蕉價格-80'''
import re p = re.compile(r'\d+$', re.MULTILINE) for one in p.findall(content): print(one)
注意,compile 的第二個參數 re.MULTILINE ,指明了使用多行模式,
運行結果如下
60
70
80
如果,去掉 compile 的第二個參數 re.MULTILINE, 運行結果如下
80
就只有最后一行了。
因為單行模式下,$ 只會匹配整個文本的結束位置。
豎線-匹配兩者之一
豎線表示 匹配 前者 或 后者 。
比如 ,
特別要注意的是, 豎線在正則表達式的優先級是最低的, 這就意味着,豎線隔開的部分是一個整體
比如 綠色|橙 表示 要匹配是 綠色 或者 橙 ,
而不是 綠色 或者 綠橙
括號-組選擇
括號稱之為 正則表達式的 組選擇。 是從正則表達式 匹配的內容 里面 扣取出 其中的某些部分
前面,我們有個例子,從下面的文本中,選擇每行逗號前面的字符串,也 包括逗號本身 。
蘋果,蘋果是綠色的
橙子,橙子是橙色的
香蕉,香蕉是黃色的
就可以這樣寫正則表達式 ^.*, 。
但是,如果我們要求 不要包括逗號 呢?
當然不能直接 這樣寫 ^.*
因為最后的逗號 是 特征 所在, 如果去掉它,就沒法找 逗號前面的了。
但是把逗號放在正則表達式中,又會包含逗號。
解決問題的方法就是使用 組選擇符 : 括號。
我們這樣寫^(.*), ,結果如下
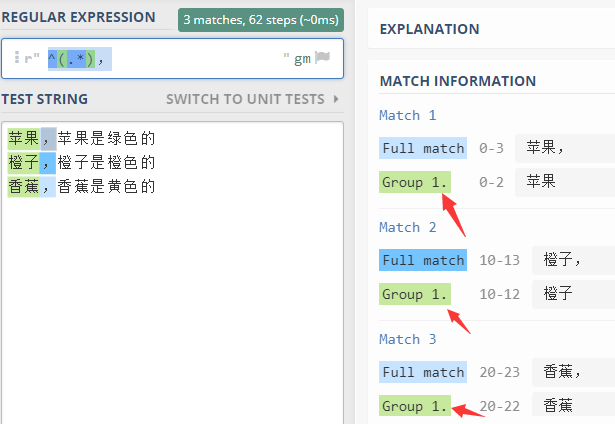
大家可以發現,我們把要從整個表達式中提取的部分放在括號中,這樣 水果 的名字 就被單獨的放在 組 group 中了。
對應的Python代碼如下
content = '''蘋果,蘋果是綠色的 橙子,橙子是橙色的 香蕉,香蕉是黃色的'''
import re p = re.compile(r'^(.*),', re.MULTILINE) for one in p.findall(content): print(one)
分組,還可以多次使用。
比如,我們要從下面的文本中,提取出每個人的 名字 和對應的 手機號
張三,手機號碼15945678901
李四,手機號碼13945677701
王二,手機號碼13845666901
可以使用這樣的正則表達式 ^(.+),.+(\d{11})
可以寫出如下的代碼
content = '''張三,手機號碼15945678901 李四,手機號碼13945677701 王二,手機號碼13845666901'''
import re p = re.compile(r'^(.+),.+(\d{11})', re.MULTILINE) for one in p.findall(content): print(one)
回到開頭的例子
有了上面的知識,我們再來看 本文開始的例子
從下面的文本里面抓取 所有職位的薪資。
Python3 高級開發工程師 上海互教教育科技有限公司上海-浦東新區2萬/月02-18滿員 測試開發工程師(C++/python) 上海墨鵾數碼科技有限公司上海-浦東新區2.5萬/每月02-18未滿員 Python3 開發工程師 上海德拓信息技術股份有限公司上海-徐匯區1.3萬/每月02-18剩余11人 測試開發工程師(Python) 赫里普(上海)信息科技有限公司上海-浦東新區1.1萬/每月02-18剩余5人 我們使用的表達式是 ([\d.]+)萬/每{0,1}月
為什么這么寫呢?
[\d.]+ 表示 匹配 數字或者點的多次出現 這就可以匹配像: 3 33 33.33 這樣的 數字
萬/每{0,1}月 是后面緊接着的,如果沒有這個,就會匹配到別的數字, 比如 Python3 里面的3。
其中 每{0,1}月 這部分表示匹配 每月 每 這個字可以出現 0次或者1次。
聰明的你能想到,還可以用什么來表示這個 每{0,1}月 嗎?
對啦,還可以用 每?月 因為問號表示 前面的字符匹配0次或者1次
使用正則表達式切割字符串
字符串 對象的 split() 方法只適應於非常簡單的字符串分割情形。當你需要更加靈活的切割字符串的時候,就不好用了。
比如,我們需要從下面字符串中提取武將的名字。
我們發現這些名字之間, 有的是分號隔開 ,有的是逗號隔開,有的是空格隔開, 而且分割符號周圍還有不定數量的空格
names = '關羽; 張飛, 趙雲,馬超, 黃忠 諸葛亮'
這時,最好使用正則表達式里面的 split 方法:
import re names = '關羽; 張飛, 趙雲, 馬超, 黃忠 諸葛亮' namelist = re.split(r'[;,\s]\s*', names) print(namelist)
正則表達式 [;,\s]\s* 指定了,分割符為 分號、逗號、空格 里面的任意一種均可,並且 該符號周圍可以有不定數量的空格。