Linux內存主要用來存儲系統和應用程序的指令,數據,緩存等
一,內存映射
1,內核給每個進程提供一個獨立的虛擬機地址空間,並且這個地址空間是連續的
2,虛擬地址空間內部又被分為內核空間和用戶空間
3,32位和64位系統的虛擬地址空間
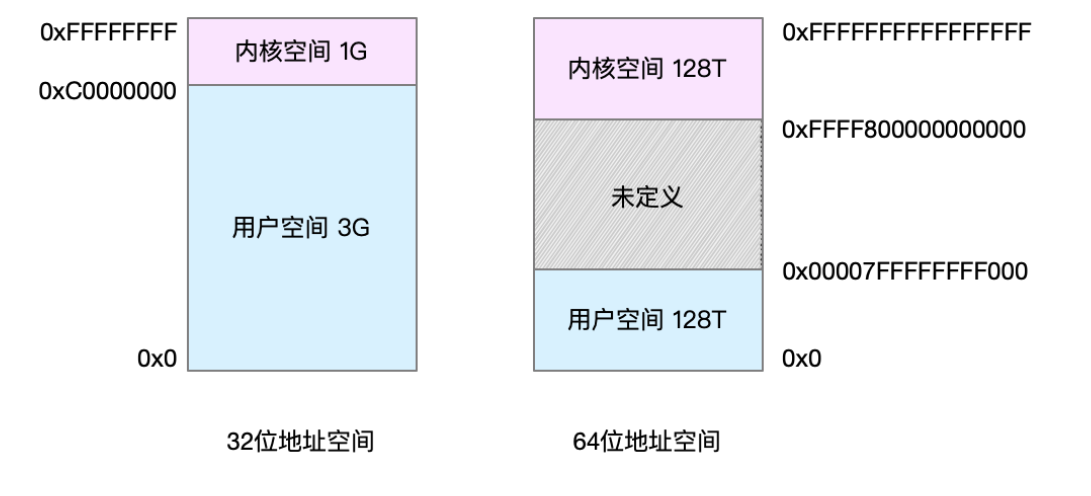 32 位系統的內核空間占用 1G,位於最高處,剩下的 3G 是用戶空間。而 64 位系統的內核空間和用戶空間都是 128T,分別占據整個內存空間的最高和最低處,剩下的中間部分是未定義的
32 位系統的內核空間占用 1G,位於最高處,剩下的 3G 是用戶空間。而 64 位系統的內核空間和用戶空間都是 128T,分別占據整個內存空間的最高和最低處,剩下的中間部分是未定義的
4,進程在用戶態時,只能訪問用戶空間內存;只有進入內核態后,才可以訪問內核空間內存
5,只有實際使用的虛擬內存才會被分配物理內存,通過內存映射來管理
6,內存映射,就是將虛擬內存地址映射到物理內存地址。為了完成內存映射,內核為每個進程都維護了一張 表,記錄虛擬地址與物理地址的映射關系
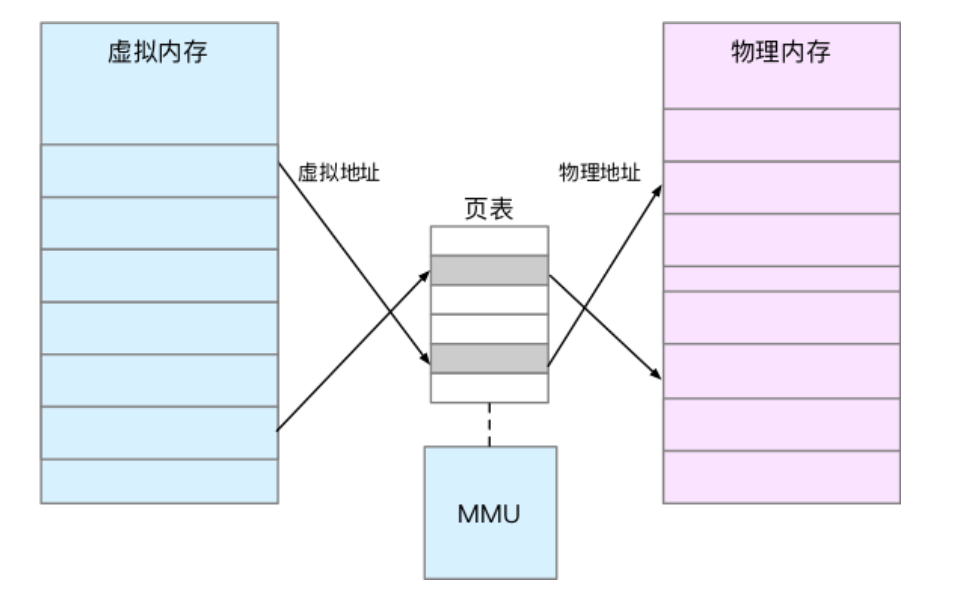
7,頁表存儲在內存管理單元[MMU](https://blog.csdn.net/u010442934/article/details/79900449)中
8,進程訪問虛擬地址在頁表中查不到時,系統會產生一個缺頁異常
9,TLB(Translation Lookaside Buffer,轉譯后備緩沖器)會影響 CPU 的內存訪問性能 ,TLB是MMU中頁表的高速緩存,。於進程的虛擬地址空間是獨立的,而 TLB 的訪問速度又比 MMU 快得多,所以,通過減少進程的上下文切換,減少 TLB 的刷新次數,就可以提高 TLB 緩存的使用率,進而提高 CPU 的內存訪問性能
10,MMU 並不以字節為單位來管理內存,而是規定了一個內存映射的最小單位,也就是頁,通常是 4 KB 大小,每一次內存映射,都需要關聯 4 KB 或者 4KB整數倍的內存空間
11, 為了解決頁表項過多的問題,Linux 提供了兩種機制,也就是多級頁表和大頁(HugePage)
多級頁表
多級頁表是把內存分成區塊來管理,將原來的映射關系改成區塊索引和區塊內的偏移,由於虛擬內存空間通常只使用了一小部分,那么多級頁表就只保存這些使用中的區塊,這樣就可以減少頁表的項數
其中Linux就用了四級頁表來管理內存頁
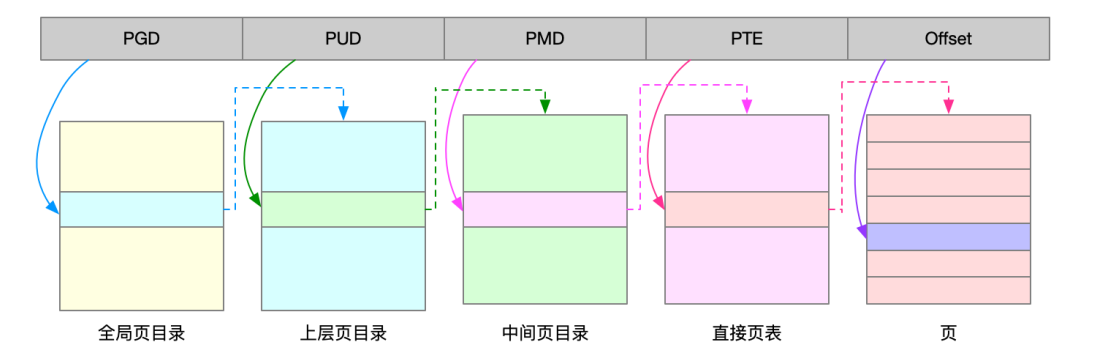
虛擬地址被分了5部分,前四個表項用於選擇頁,最后一部分用於頁內偏移
大頁
就是比普通頁更大的內存塊,常見的大小有 2MB 和 1GB。大頁通常用在使用大量內存的進程上,比如 Oracle、DPDK 等
大頁內存使用相關指令
cat /sys/devices/system/node/node*/meminfo | fgrep Huge
#查看各個numa節點的大頁內存情況。
grep Huge /proc/meminfo
#查看大頁內存使用情況
numactl --hradware
#查看系統numa架構,cpu分配情況
echo 64 > /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
#為numa0節點分配64個2m的大頁
mkdir -p /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
#掛載大頁,重啟后失效
#永久掛在大頁內存
vim /etc/fstab
nodev /mnt/huge hugetlbfs defaults 0 0 #掛載2M大頁
nodev /mnt/huge_1GB hugetlbfs pagesize=1GB 0 0 #掛載1G的大頁
#查看大頁內存掛載情況
cat /proc/mounts
#查找正在使用大頁的進程
find /proc/*/smaps | xargs grep -ril "anon_hugepage"
#取消掛載
umount /dev/hugepages
umount /mnt/huge
參考 linux大頁內存
二,虛擬內存空間分布
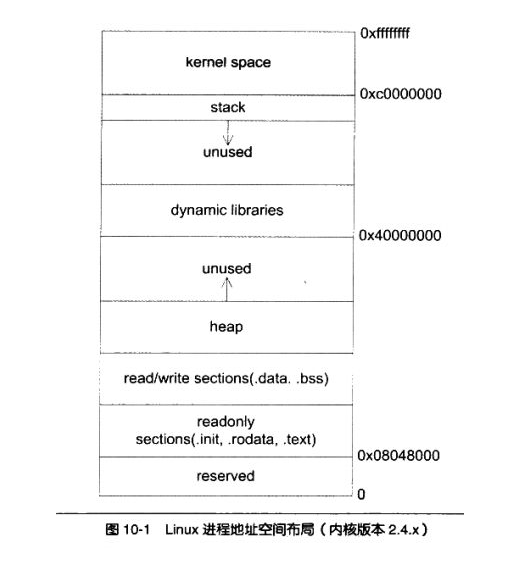
1,32 位系統 內存地址空間分布

用戶空間內存,從低到高分別是五種不同的內存段
- 只讀段:包括代碼和常量等。
- 數據段:包括全局變量等。
- 堆:包括動態分配的內存,從低地址開始向上增長。
- 文件映射段,包括動態庫、共享內存等,從高地址開始向下增長。
- 棧,包括局部變量和函數調用的上下文等。棧的大小是固定的,一般是 8 MB
在這五個內存段中,堆和文件映射段的內存是動態分配的。使用 C 標准庫的malloc() 或者 mmap() ,就可以分別在堆和文件映射段動態分配內存
其他地方有以下的布局介紹
2,代碼段
代碼段中存放可執行的指令,在內存中,為了保證不會因為堆棧溢出被覆蓋,將其放在了堆棧段下面。通常來講代碼段是共享的,這樣多次反復執行的指令只需要在內存中駐留一個副本即可,比如 C 編譯器,文本編輯器等。代碼段一般是只讀的,程序執行時不能隨意更改指令,也是為了進行隔離保護。
3、初始化數據段
初始化數據段有時就稱之為數據段。數據段是一個程序虛擬地址空間的一部分,包括一全局變量和靜態變量,這些變量在編程時就已經被初始化。數據段是可以修改的,不然程序運行時變量就無法改變了,這一點和代碼段不同。
數據段可以細分為初始化只讀區和初始化讀寫區。這一點和編程中的一些特殊變量吻合。比如全局變量 int global n = 1就被放在了初始化讀寫區,因為 global 是可以修改的。而 const int m = 2 就會被放在只讀區,很明顯,m 是不能修改的。
4、未初始化數據段
未初始化數據段有時稱之為 BSS 段,BSS 是英文 Block Started by Symbol 的簡稱,BSS 段屬於靜態內存分配。存放在這里的數據都由內核初始化為 0。未初始化數據段從數據段的末尾開始,存放有全部的全局變量和靜態變量並被,默認初始化為 0,或者代碼中沒有顯式初始化。比如 static int i; 或者全局 int j; 都會被放到BSS段。
5、棧
棧 (stack) 是現代計算機程序里最為重要的概念之一,幾乎每一個程序都使用了棧,沒有棧就沒有函數,沒有局部變量,也就沒有我們如今能夠看見的所有的計算機語言。在
傳統的棧的定義:
在經典的計算機科學中,棧被定義為一個特殊的容器,用戶可以將數據壓入棧中(入棧,push,也可以將已經壓入棧中的數據彈出(出棧, pop),但棧這個容器必須遵守一條規則:先入棧的數據后出棧(First In Last Out, FIFO),多多少少像疊成一疊的書:先疊上去的書在最下面:因此要最后才能取出。
在計算機系統中,棧則是一個具有以上屬性的動態內存區域。程序可以將數據壓入棧中,也可以將數據從棧頂彈出。壓棧操作使得棧增大,而彈出操作使棧減小
在i386下,棧頂由稱為 esp 的寄存器進行定位。壓棧的操作使棧頂的地址減小,彈出的操作使棧頂地址增大。
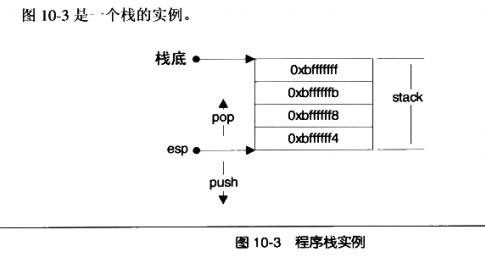
這里棧底的地址是 0xbffff,而 esp 寄存器標明了棧頂,地址為 0xbifff4。
在棧上壓入數據會導致 esp 減小,彈出數據使得 esp 增大。
棧在程序運行中具有舉足輕重的地位。最重要的,棧保存了一個函數調用所需要的維護信息,這常常被稱為堆棧幀(Stack Frame)或活動記錄(Activate Record),堆棧幀一般包括如下幾方面內容:
1、函數的返回地址和參數。
2、臨時變量:包括函數的非靜態局部變量以及編譯器自動生成的其他臨時變量。
3、保存的上下文:包括在函數調用前后需要保持不變的寄存器。
6、堆
相對於棧,堆這片內存面臨着一個稍微復雜的行為模式:在任意時刻,程序可能發出請求,要么申請一段內存,要么釋放一段已經申請過的內存,而且申請的大小從幾個字節到數 GB 都是有可能的,我們不能假設程序會一次申請多少堆空間,因此,堆的管理顯得較為復雜。
為什么需要堆?
光有棧,對於面向過程的程序設計還遠遠不夠,因為棧上的數據在函數返回的時候就會被釋放掉,所以無法將數據傳遞至函數外部。而全局變量沒有辦法動態地產生,只能在編譯的時候定義,有很多情況下缺乏表現力,在這種情況下,堆(Heap)是一種唯一的選擇。
堆是一款巨大的內存空間,常常占據整個虛擬空間的絕大部分,在這片空間里,程序可以請求一塊連續的內存,並自由地使用,這塊內存在程序主動放棄之前都活一直保持有效,下面是一個申請堆空間最簡單的例子:
int main()
{
char* p = (char*) malloc(233);
free(p);
return 0;
}
在第 3 行用 malloc 申請了 233 個字節的空間之后,程序可以自由地使用這 233個字節,直到程序用free函數釋放它。
那么 malloc 到底是怎么實現的呢?
有一種做法是,把進程的內存管理交給操作系統內核去做,既然內核管理着進程的地址空間,那么如果它提供一個系統調用,可以讓程序使用這個系統調用申請內存,不就可以了嗎?
當然這是一種理論上可行的做法,但實際上這樣做的性能比較差,原因在於每次程序申請或者釋放堆空間都需要進行系統調用。
我們知道系統調用的性能開銷是很大的,當程序對堆的操作比較頻繁時,這樣做的結果是會嚴重影響程序的性能的。
比較好的做法就是:程序向操作系統申請一塊適當大小的堆空間,然后由程序自己管理這塊空間,而具體來講,管理着堆空間分配的往往是程序的運行庫。
運行庫相當於是向操作系統 “批發” 了一塊較大的堆空間,然后 “零售” 給程序用。
當全部“售完”或程序有大量的內存需求時,再根據實際需求向操作系統“進貨”。
當然運行庫在向程序零售堆空間時,必須管理它批發來的堆空間,不能把同一塊地址出售兩次,導致地址的沖突。
7、Linux 進程堆管理
進程的地址空間中,除了可執行文件,共享庫和棧之外,剩余的未分配的空間都可以用來作為堆空間。
Linux 系統下,提供兩種堆空間分配方式,兩個系統調用:brk() 系統調用 和 mmap() 系統調用
這兩種方式分配的都是虛擬內存,沒有分配物理內存。在第一次訪問已分配的虛擬地址空間的時候,發生缺頁中斷,操作系統負責分配物理內存,然后建立虛擬內存和物理內存之間的映射關系。
在標准 C 庫中,提供了malloc/free函數分配釋放內存,這兩個函數底層是由 brk,mmap,munmap 這些系統調用實現的。
brk() 系統調用
C 語言形式聲明:int brk() {void* end_data_segment;}
brk() 的作用實際上就是設置進程數據段的結束地址,即它可以擴大或者縮小數據段(Linux 下數據段和 BBS 合並在一起統稱數據段)。
如果我們將數據段的結束地址向高地址移動,那么擴大的那部分空間就可以被我們使用,把這塊空間拿過來使用作為堆空間是最常見的做法。
mmap() 系統調用
和 Windows 系統下的 VirtualAlloc 很相似,它的作用就是向操作系統申請一段虛擬地址空間,(堆和棧中間,稱為文件映射區域的地方)這塊虛擬地址空間可以映射到某個文件。
glibc 的 malloc 函數是這樣處理用戶的空間請求的:對於小於 128KB 的請求來說,它會在現有的堆空間里面,按照堆分配算法為它分配一塊空間並返回;對於大於128KB 的請求來說,它會使用 mmap() 函數為它分配一塊匿名空間,然后在這個匿名空間中為用戶分配空間。
聲明如下:
void* mmap{
void* start;
size_t length;
int prot;
int flags;
int fd;
off_t offset;
}
mmap 前兩個參數分別用於指定需要申請的空間的起始地址和長度,如果起始地址設置 0,那么 Linux 系統會自動挑選合適的起始地址。
prot/flags 參數:用於設置申請的空間的權限(可讀,可寫,可執行)以及映射類型(文件映射,匿名空間等)。
最后兩個參數用於文件映射時指定的文件描述符和文件偏移的。
了解了 Linux 系統對於堆的管理之后,可以再來詳細這么一個問題,那就是 malloc 到底一次能夠申請的最大空間是多少?
為了回答這個問題,就不得不再回頭仔細研究一下之前的圖一。我們可以看到在有共享庫的情況下,留給堆可以用的空間還有兩處。第一處就是從 BSS 段結束到 0x40 000 000 即大約 1GB 不到的空間;
第二處是從共享庫到棧的這塊空間,大約是 2GB 不到。這兩塊空間大小都取決於棧、共享庫的大小和數量。
於是可以估算到 malloc 最大的申請空間大約是 2GB 不到。(Linux 內核 2.4 版本)。
還有其它諸多因素會影響 malloc 的最大空間大小,比如系統的資源限制(ulimit),物理內存和交換空間的總和等。mmap 申請匿名空間時,系統會為它在內存或交換空間中預留地址,但是申請的空間大小不能超過空閑內存+空閑交換空間的總和。
內存分配與回收
分配
malloc() 是 C 標准庫提供的內存分配函數,對應到系統調用上,有兩種實現方式,即brk() 和 mmap()。、
對小塊內存(小於 128K),C 標准庫使用 brk() 來分配,也就是通過移動堆頂的位置來分配內存。這些內存釋放后並不會立刻歸還系統,而是被緩存起來,這樣就可以重復使用。
而大塊內存(大於 128K),則直接使用內存映射 mmap() 來分配,也就是在文件映射段找一塊空閑內存分配出去。
brk() 方式的緩存,可以減少缺頁異常的發生,提高內存訪問效率。不過,由於這些內存沒有歸還系統,在內存工作繁忙時,頻繁的內存分配和釋放會造成內存碎片。
mmap() 方式分配的內存,會在釋放時直接歸還系統,所以每次 mmap 都會發生缺頁異常。在內存工作繁忙時,頻繁的內存分配會導致大量的缺頁異常,使內核的管理負擔增大。這也是 malloc 只對大塊內存使用 mmap 的原因。
當這兩種調用發生后,其實並沒有真正分配內存。這些內存,都只在首次訪問時才分配,也就是通過缺頁異常進入內核中,再由內核來分配內存。
回收
系統也不會任由某個進程用完所有內 存,在發現內存緊張時,系統就會通過一系列機制來回收內存,比如下面這三種方式
1,回收緩存。比如使用LRU算法,回收最近使用最少的內存頁
2,回收不常訪問的內存,把不常用的內存通過交換分區寫進磁盤
3,殺死進程,內存緊張時系統通過OOM,直接殺死占用大量的內存的進程
如何查看內存使用情況
1,free

free 輸出的是一個表格,其中的數值都默認以字節為單位。表格總共有兩行六列,這兩行分別是物理內存 Mem 和交換分區 Swap 的使用情況,而六列中,每列數據的含義分別為:
第一列,total 是總內存大小;
第二列,used 是已使用內存的大小,包含了共享內存;
第三列,free 是未使用內存的大小;
第四列,shared 是共享內存的大小;
第五列,buff/cache 是緩存和緩沖區的大小;
最后一列,available 是新進程可用內存的大小
最后一列的可用內存 available 。available 不僅包含未使用內存,還包括了可回收的緩存,所以一般會比未使用內存更大。不過,並不是所有緩存都可以回收,因為有些緩存可能正在使用中
2,top
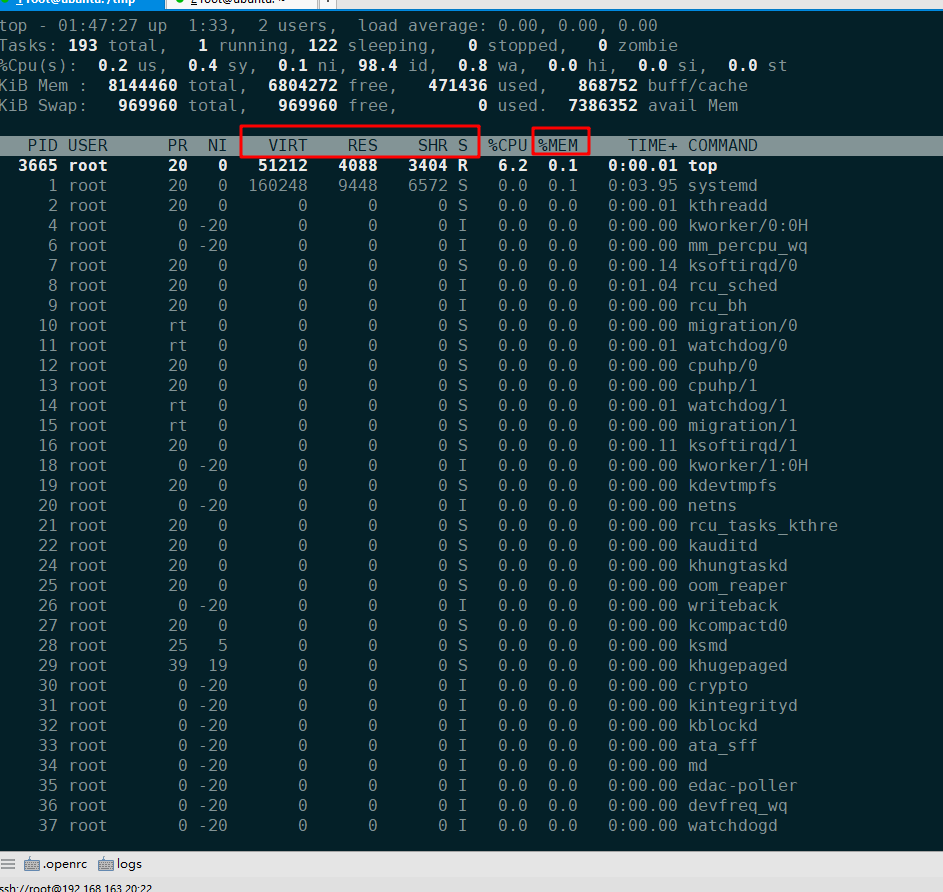
top 輸出界面的頂端,也顯示了系統整體的內存使用情況,這些數據跟 free 類似,我就不再重復解釋。我們接着看下面的內容,跟內存相關的幾列數據,比如 VIRT、RES、SHR 以及 %MEM 等。這些數據,包含了進程最重要的幾個內存使用情況:
VIRT 是進程虛擬內存的大小,只要是進程申請過的內存,即便還沒有真正分配物理內存,也會計算在內。
RES 是常駐內存的大小,也就是進程實際使用的物理內存大小,但不包括 Swap 和共享內存。
SHR 是共享內存的大小,比如與其他進程共同使用的共享內存、加載的動態鏈接庫以及程序的代碼段等。
%MEM 是進程使用物理內存占系統總內存的百分比
另外還需要注意:
第一,虛擬內存通常並不會全部分配物理內存。從上面的輸出,你可以發現每個進程的虛擬內存都比常駐內存大得多。
第二,共享內存SHR並不一定是共享的,比方說,程序的代碼段、非共享的動態鏈接庫,也都算在SHR里。當然,SHR也包括了進程間真正共享的內存。所以在計算多個進程的內存使用時,不要把所有進程的SHR 直接相加得出結果。
本文來源
1,https://zhuanlan.zhihu.com/p/77122692
2,極客時間-Linux性能優化