學習筆記,參考原作者
數據清洗是數據分析的第一步, 經常需要花費大量的時間來清洗數據或者轉換格式。
一、數據預處理
1. 部署環境,導入分析包和數據
import pandas as pd
import numpy as np
DataDF=pd.read_csv('C:/Users/jzgao/Desktop/ecommerce-data/data.csv',encoding = "ISO-8859-1",dtype = str)
# dtype = str,最好讀取的時候都以字符串的形式讀入,不然可能會使數據失真
# 比如一個0010008的編號可能會讀取成10008
# encoding = "ISO-8859-1" -- 用什么解碼,一般會默認系統的編碼,如果是中文就用 "utf-8"
2. 嘗試去理解這份數據集
我們可以通過對數據集提問來判斷這份數據能不能滿足解答我們的問題,數據是否干凈需不需要進一步處理,問題包括但不限於:
數據集多少數據?
包含了什么字段?字段格式是什么?
字段分別代表什么意義
字段之間的關系是什么?可以用做什么分析?或者說能否滿足了對分析的要求?
有沒有缺失值;如果有的話,缺失值多不多?
現有數據里面有沒有臟數據?尤其需要注意人工輸入的數據,經常會出現名稱寫錯,多輸入空格等等的情況
3. 下面我們就結合代碼來看一下數據
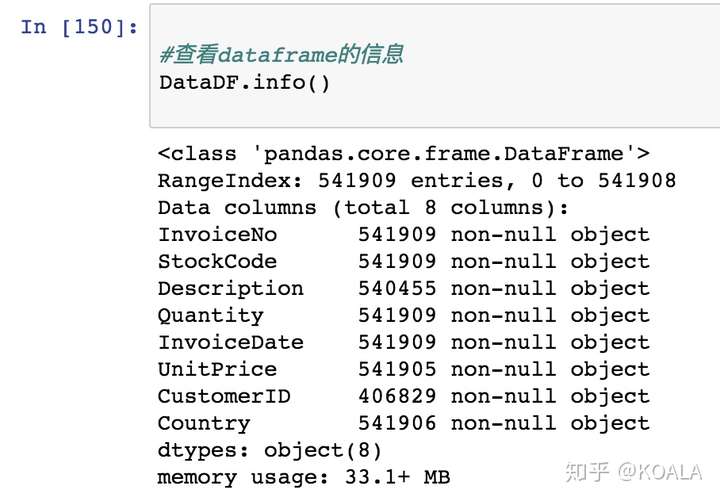
# 1.從宏觀一點的角度去看數據:查看dataframe的信息
DataDF.info()
```python # 2.檢查缺失數據 # 如果你要檢查每列缺失數據的數量,使用下列代碼是最快的方法。 # 可以讓你更好地了解哪些列缺失的數據更多,從而確定怎么進行下一步的數據清洗和分析操作。 DataDF.isnull().sum().sort_values(ascending=False) ```

```python # 3.抽出一部分數據來,人工直觀地理解數據的意義,盡可能地發現一些問題 DataDF.head() ```
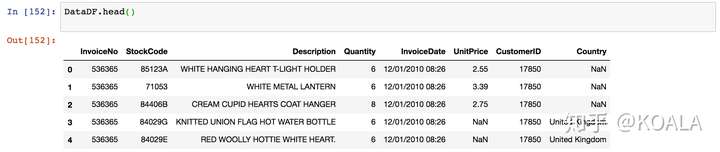
可以看到:
1)InvoiceDate 的時間出現具體時分,可以刪去
2)Description 大概率是人工填寫的數據,一般都會有比較多格式問題。
猜測會存在有標點符號摻雜/大小寫不一致等問題,所以進一步這些人工填寫數據的去重項拎出來研究一下
# 查看這個商品名稱的去重項
DataDF['Description'].unique()

```python # 設置輸出全部的內容 # threshold就是設置超過了多少條,就會呈現省略 #(比如threshold=10的意思是超過10條就會省略) np.set_printoptions(threshold=np.inf) DataDF['Description'].unique() ```

發現有很多空格的問題
根據第一步數據預處理后,整理一下該數據集有下列問題需要處理:
1)調整數據類型:由於一開始用到了 str 來導入,打算后期再更換格式,需要調整數據類型。
2)修改列名:該數據的名稱不易於理解,需要改列名
3)選擇部分子集:因為有部分列在數據分析中不需要用到
4)可能存在邏輯問題需要篩選:比如 Unit Price 為負
5)格式一致化:Description 可能會存在有標點符號摻雜/大小寫不一致/空格重復出現等問題
6)消滅空值:CustomerID、Description、Country 和 UnitPrice 都出現了 NaN 值,需要去掉
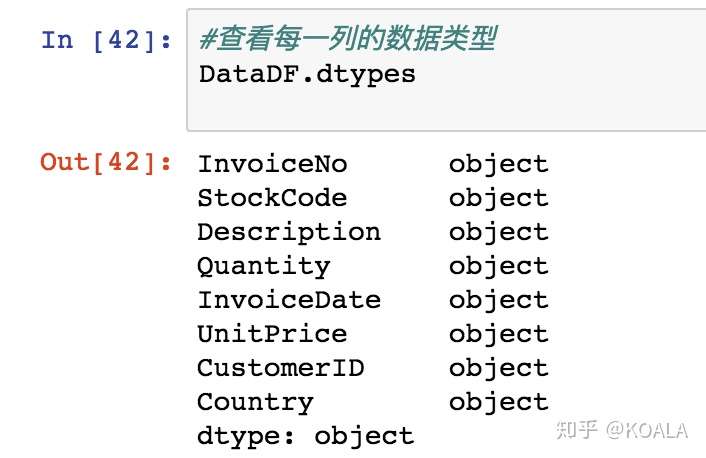
**二、調整數據類型**
DataDF.dtypes
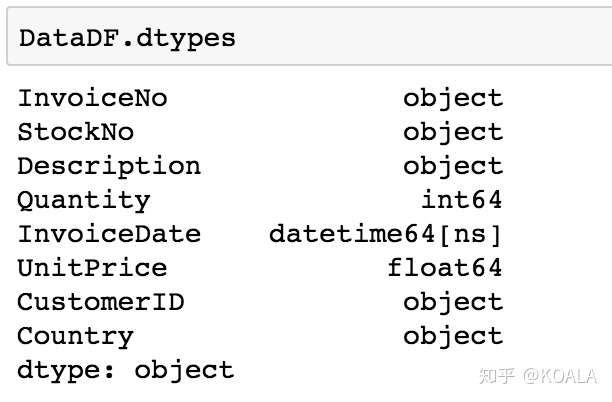
```python # 字符串轉換為數值(整型) DataDF['Quantity'] = DataDF['Quantity'].astype('int') # 字符串轉換為數值(浮點型) DataDF['UnitPrice'] = DataDF['UnitPrice'].astype('float')
DataDF.dtypes
<br>
<br>
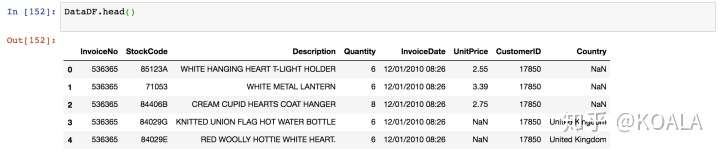
**三、修改列名**
```python
DataDF.head(10)
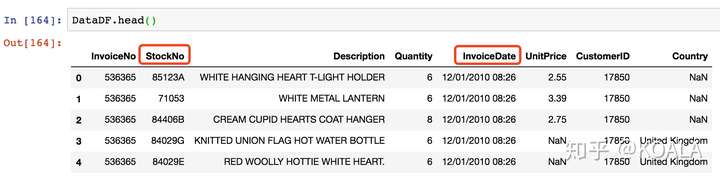
```python # 建立字典字典:舊列名和新列名對應關系 colNameDict = {'InvolceDate':'SaleDate','StockCode':'StockNo'} # !! ⚠️一定要舊列名放在冒號前 # 每組對應關系以[逗號]隔開 DataDF.rename(columns = colNameDict,inplace=True)
DataDF.head(10)
<br>
<br>
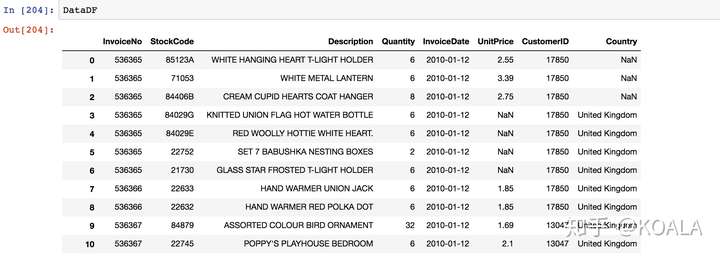
**四、選擇部分子集**
```python
DataDF
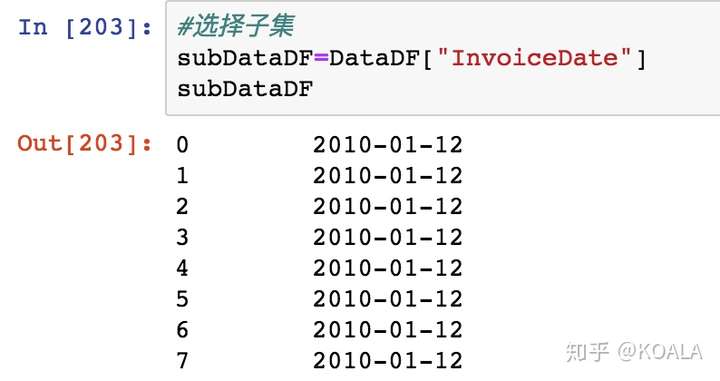
```python #選擇子集,選擇其中一列 subDataDF1=DataDF["InvoiceDate"]
subDataDF1
<br>
<br>
```python
#選擇子集,選擇其中兩列
subDataDF2=DataDF[["InvoiceDate","UnitPrice"]]
subDataDF2
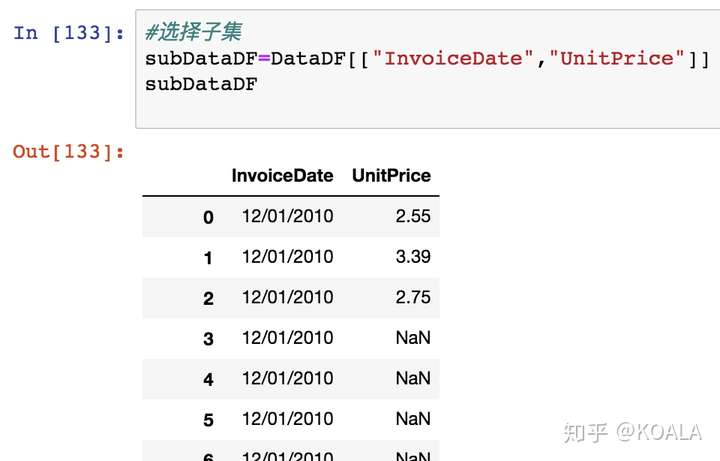
利用切片篩選數據功能 df.loc
loc 這個代碼有點像 Excel 里面的鼠標左鍵,可以隨意拉動你需要的數據進行切片。
以逗號作為隔開的界限,左邊為 index,右邊為 column
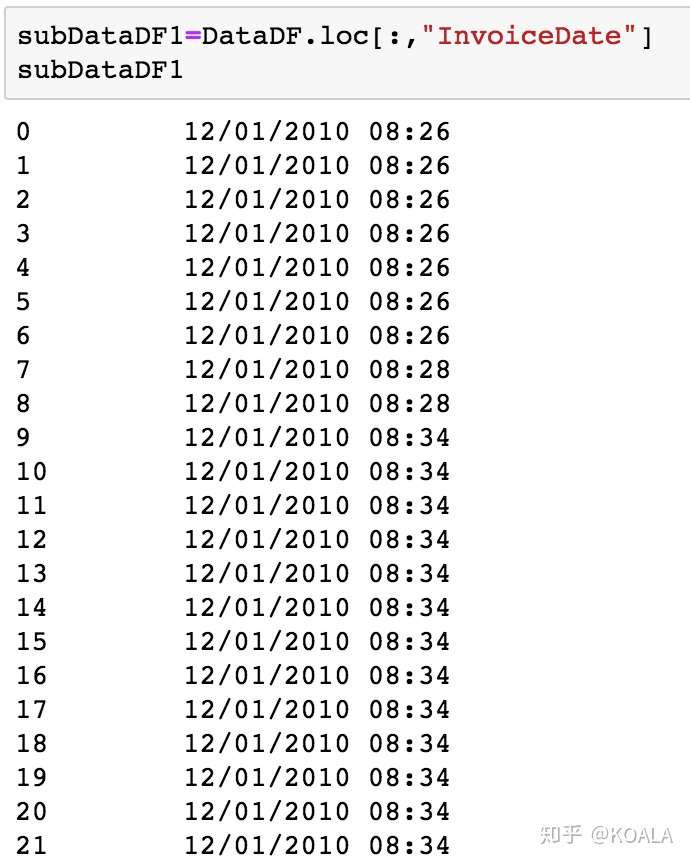
subDataDF3=DataDF.loc[:,"InvoiceDate"]
subDataDF3
#單一個冒號意味着不作限制的全選
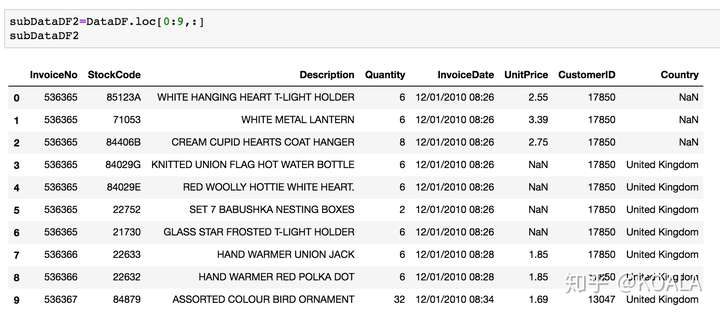
```python subDataDF4=DataDF.loc[0:9,:] subDataDF4 ```
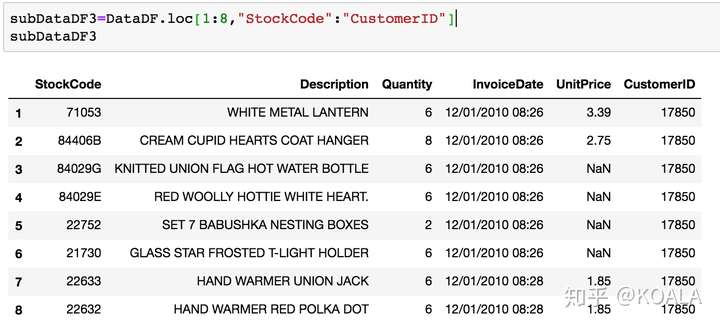
```python subDataDF5=DataDF.loc[1:8,"StockNo":"CustomerID"] subDataDF5 ```
五、邏輯問題需要篩選
還是 Dataframe.loc 這個函數的知識點。
由於 loc 還可以判斷條件是否為 True
DataDF.loc[:,'UnitPrice']>0
一般來說價格不能為負,所以從邏輯上來說如果價格是小於 0 的數據應該予以篩出
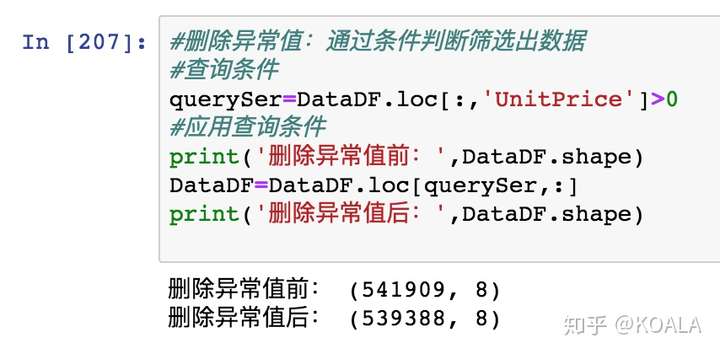
#刪除異常值:通過條件判斷篩選出數據
#查詢條件
querySer=DataDF.loc[:,'Quantity']>0
#應用查詢條件
print('刪除異常值前:',DataDF.shape)
DataDF=DataDF.loc[querySer,:]
print('刪除異常值后:',DataDF.shape)
六、格式一致化
1. 大小寫/去除空格
將數據中 Descrption 列中所有內容改成大寫:
DataDF['Description']= DataDF['Description'].str.upper()
DataDF.head()
類似的代碼還有 字符串修改方法:
str().
upper()
lower()
title()
lstrip()
strip()
# str.strip()把字符串頭和尾的空格,以及位於頭尾的 \n \t 之類給刪掉。
DataDF['Description']= DataDF['Description'].str.strip()
2. 去除字符串符號 去亂碼
3. 空格分割
#定義函數:分割InvoiceDate,獲取InvoiceDate
#輸入:timeColSer InvoiceDate這一列,是個Series數據類型
#輸出:分割后的時間,返回也是個Series數據類型
def splitSaletime(timeColSer):
timeList=[]
for value in timeColSer:
#例如2018/01/01 12:50,分割后為:2018-01-01
dateStr=value.split(' ')[0]
timeList.append(dateStr)
#將列表轉行為一維數據Series類型
timeSer=pd.Series(timeList)
return timeSer
最后再賦值回去
DataDF.loc[:,'InvoiceDate']=splitSaletime(DataDF.loc[:,'InvoiceDate'])
七、處理缺失值
python 缺失值有 3 種:
1)Python 內置的 None 值
2)在 pandas 中,將缺失值表示為 NA,表示不可用 not available。
3)對於數值數據,pandas 使用浮點值 NaN(Not a Number)表示缺失數據。 后面出來數據,如果遇到錯誤:說什么 float 錯誤,那就是有缺失值,需要處理掉
那 None 和 NaN 有什么區別呢:
None 是 Python 的一種數據類型,
NaN 是浮點類型
兩個都用作空值
print(type(None))
print(type(NaN))

1. 去除缺失值
# 再一次提醒檢查缺失數據
DataDF.isnull().sum().sort_values(ascending=False)
去除缺失值的知識點:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# 默認(axis=0)是逢空值剔除整行,設置關鍵字參數axis=1表示逢空值去掉整列
# 'any'如果一行(或一列)里任何一個數據有任何出現Nan就去掉整行,
# 'all'一行(或列)每一個數據都是Nan才去掉這整行
DataDF.dropna(how='any')
DataDF.dropna(how='all')
# 更精細的thresh參數,它表示留下此行(或列)時,要求有多少[非缺失值]
DataDF.dropna(thresh = 6 )
2. 填充缺失內容:某些缺失值可以進行填充,方法有以下四種:
-
以業務知識或經驗推測(默認值)填充缺失值
-
以同一指標的計算結果(均值、中位數、眾數等)填充缺失值
-
用相鄰值填充缺失值
-
以不同指標的計算結果填充缺失值
去除缺失值的知識點:
1) 用默認值填充- df.fillna (' ')
我們應該去掉那些不友好的 NaN 值。但是,我們應該用什么值替換呢?這個時候可能要結合你對這個數據集的理解,看填充什么數據才是比較合適,以下是一下常用的方法。
在這個數據集中,我們大致判斷 CustomerID 如果是不太重要的,就我們可以用使用 "" 空字符串或其他默認值。
DataDF.Country= DataDF.Country.fillna('Not Given')
2) 以同一指標的計算結果(均值、中位數、眾數等)填充缺失值
平均值- df.fillna (df.mean ())
使用數字類型的數據有可能可以通過這樣的方法來去減少錯誤。
比如,這個案例里面的價格。如果用 0 或者 "Not Given" 等來去填充都不太合適,但這個大概的價格是可以根據其他數據估算出來的。
DataDF.UnitPrice = DataDF.UnitPrice.fillna(DataDF.UnitPrice.mean())
3)除此,還有一種常見的方法,就是用相鄰的值進行填充,
這在時間序列分析中相當常見,用前面相鄰的值向后填充,也可以用后面相鄰的值向前填充。
print(DataDF)
print(DataDF.UnitPrice.fillna(method='ffill')) # 前向后填充
print(DataDF.UnitPrice.fillna(method='bfill')) # 后向前填充
4) 以不同指標的計算結果填充缺失值
關於這種方法年齡字段缺失,但是有屏蔽后六位的身份證號可以推算具體的年齡是多少。