平均負載
1,執行 top 或者 uptime 命令 來了解系統負載
uptime

分析顯示 當前時間,系統運行時間,正在登錄用戶數
平均負載是指單位時間內,系統處於可運行狀態和不可中斷狀態的平均進程數,也就是平均活躍進程數,它和 CPU 使用率並沒有直接關系
可運行狀態的進程,是指正在使用 CPU 或者正在等待 CPU 的進程,也就是我們常用ps 命令看到的,處於 R 狀態(Running 或 Runnable)的進程
不可中斷狀態的進程則是正處於內核態關鍵流程中的進程,並且這些流程是不可打斷的,比如最常見的是等待硬件設備的 I/O 響應,也就是我們在 ps 命令中看到的 D 狀態(Uninterruptible Sleep,也稱為 Disk Sleep)的進程
比如,當一個進程向磁盤讀寫數據時,為了保證數據的一致性,在得到磁盤回復前,它是不能被其他進程或者中斷打斷的,這個時候的進程就處於不可中斷狀態。如果此時的進程被打斷了,就容易出現磁盤數據與進程數據不一致的問題。
所以,不可中斷狀態實際上是系統對進程和硬件設備的一種保護機制。
平均負載其實就是平均活躍進程數。平均活躍進程數,直觀上的理解就是單位時間內的活躍進程數,但它實際上是活躍進程數的指數衰減平均值。
比如當平均負載為 2 時,意味着什么呢?
在只有 2 個 CPU 的系統上,意味着所有的 CPU 都剛好被完全占用。
在 4 個 CPU 的系統上,意味着 CPU 有 50% 的空閑。
而在只有 1 個 CPU 的系統中,則意味着有一半的進程競爭不到 CPU
平均負載為多少時合理
平均負載最理想的情況是等於 CPU 個數。所以在評判平均負載時,首先你要知道系統有幾個 CPU,這可以通過 top 命令或者從文件 /proc/cpuinfo 中讀取
[root@node-1 home]# grep 'model name' /proc/cpuinfo | wc -l
8
當平均負載比 CPU 個數還大的時候,系統已經出現了過載
均負載有三個數值,到底該參考哪一個呢?
三個不同時間間隔的平均值,其實給我們提供了,分析系統負載趨勢的數據來源,讓我們能更全面、更立體地理解目前的負載狀況
如果 1 分鍾、5 分鍾、15 分鍾的三個值基本相同,或者相差不大,那就說明系統負載很平穩。
但如果 1 分鍾的值遠小於 15 分鍾的值,就說明系統最近 1 分鍾的負載在減少,而過去15 分鍾內卻有很大的負載。
反過來,如果 1 分鍾的值遠大於 15 分鍾的值,就說明最近 1 分鍾的負載在增加,這種增加有可能只是臨時性的,也有可能還會持續增加下去,所以就需要持續觀察。一旦 1分鍾的平均負載接近或超過了 CPU 的個數,就意味着系統正在發生過載的問題,這時就得分析調查是哪里導致的問題,並要想辦法優化了
平均負載多高時,需要我們重點關注呢?
當平均負載高於 CPU 數量 70% 的時候,你就應該分析排查負載高的問題了。一旦負載過高,就可能導致進程響應變慢,進而影響服務的正常功能
但 70% 這個數字並不是絕對的,最推薦的方法,還是把系統的平均負載監控起來,然后根據更多的歷史數據,判斷負載的變化趨勢。當發現負載有明顯升高趨勢時
平均負載與 CPU 使用率
平均負載是指單位時間內,處於可運行狀態和不可中斷狀態的進程數。所以,它不僅包括了正在使用 CPU 的進程,還包括等待 CPU 和等待I/O 的進程, 而 CPU 使用率,是單位時間內 CPU 繁忙情況的統計,跟平均負載並不一定完全對應。比如:
CPU 密集型進程,使用大量 CPU 會導致平均負載升高,此時這兩者是一致的;
I/O 密集型進程,等待 I/O 也會導致平均負載升高,但 CPU 使用率不一定很高;
大量等待 CPU 的進程調度也會導致平均負載升高,此時的 CPU 使用率也會比較高
平均負載案例分析
准備
規格:2U8G
預先安裝 stress 和 sysstat 包
工具:iostat、mpstat、pidstat
stress 是一個 Linux 系統壓力測試工具,
sysstat 包含了常用的 Linux 性能工具,用來監控和分析系統的性能。這個包的兩個命令 mpstat 和 pidstat。
mpstat 是一個常用的多核 CPU 性能分析工具,用來實時查看每個 CPU 的性能指標,以及所有 CPU 的平均指標。
pidstat 是一個常用的進程性能分析工具,用來實時查看進程的 CPU、內存、I/O 以及上下文切換等性能指標
場景一:CPU 密集型進程
第一個終端運行 stress 命令,模擬一個 CPU 使用率 100% 的場景
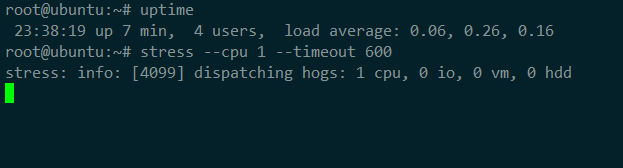
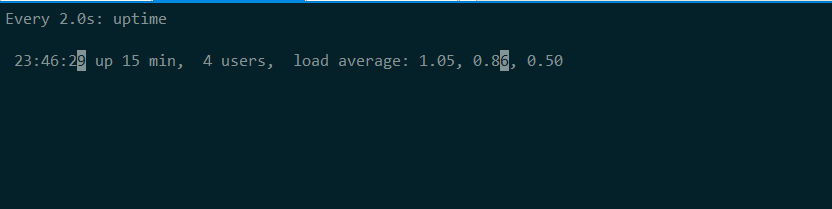
在第二個終端運行 uptime 查看平均負載的變化情況
watch是周期性的執行下個程序,並全屏顯示執行的結果。
1.命令格式:
watch[]參數[命令]
2.命令功能:
可以將命令的輸出結果輸出到標准輸出設備,多用於周期性執行命令/定時執行命令
3.命令參數:
-n或--interval watch 缺省每2秒運行一下程序,多用於周期性執行命令/定時執行命令。
-d或-differences 用 -d 或--differences選項watch 會高亮顯示變化的區域。而-d = cumulative 選項會把變動過的地方(不管最近的那次有沒有變動)都會高亮顯示出來。
-t或-no-title 會關閉watch 命令在頂部的時間間隔命令,
4.使用實例:
實例1:每隔一秒高亮顯示網絡鏈接數的變化情況
命令 watch -n 1 -d netstat -ant
實例2:每隔一秒高亮顯示命令鏈接數的變化情況
命令 watch -n 1 -d ' pstree | grep http '
每隔一秒高亮顯示http 鏈接數的變化情況,后面接的命令若帶有管道符,需要加“將命令區域歸整”。
實例3:實時查看模擬攻擊客戶機建立起來的鏈接數
命令 watch 'netstat -an | grep:21 | \grep<模擬攻擊客戶機的IP> wc -1'
實例4:檢測當前目錄中 scf ' 的文件的變化
命令:watch -d ' ls -l | grep scf '
實例5:10秒一次輸出系統的平均負載
命令:watch -n 10 ' cat /proc/loadavg'
在第三個終端運行 mpstat 查看 CPU 使用率的變化情況:
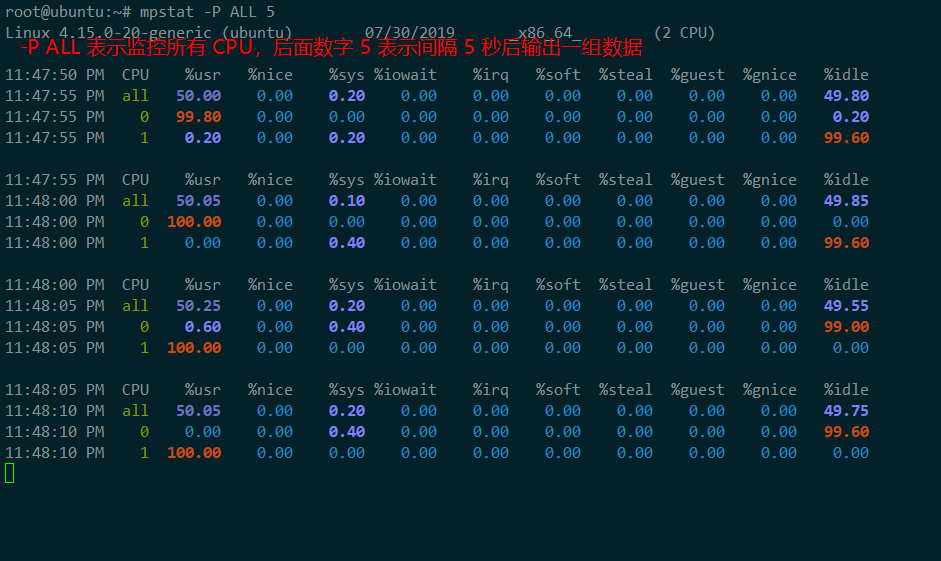
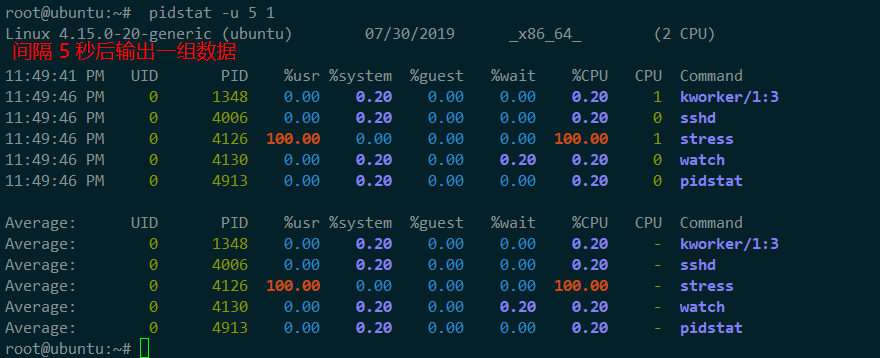
終端二中可以看到,1 分鍾的平均負載會慢慢增加到 1.00,而從終端三中還可以看到,正好有一個 CPU 的使用率為 100%,但它的 iowait 只有 0。這說明,平均負載的升高正是由於 CPU 使用率為 100%
使用pidstat 來查詢哪個進程在使用cpu:
場景二:I/O 密集型進程
1,加壓
root@ubuntu:~# stress -i 1 --timeout 600
stress: info: [5125] dispatching hogs: 0 cpu, 1 io, 0 vm, 0 hdd
2,查看uptime
watch -d uptime
3,mpstat 查看 CPU 使用率的變化情況
root@ubuntu:~# mpstat -P ALL 5
Linux 4.15.0-20-generic (ubuntu) 07/30/2019 _x86_64_ (2 CPU)
11:54:19 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:54:24 PM all 0.80 0.00 49.40 0.00 0.00 0.10 0.00 0.00 0.00 49.70
11:54:24 PM 0 0.20 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.60
11:54:24 PM 1 1.40 0.00 98.60 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11:54:24 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:54:29 PM all 0.70 0.00 49.60 0.00 0.00 0.00 0.00 0.00 0.00 49.70
11:54:29 PM 0 0.20 0.00 0.20 0.00 0.00 0.00 0.00 0.00 0.00 99.60
11:54:29 PM 1 1.20 0.00 98.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00
4,查看哪個進程占用
root@ubuntu:~# pidstat -u 5 1
Linux 4.15.0-20-generic (ubuntu) 07/30/2019 _x86_64_ (2 CPU)
11:57:37 PM UID PID %usr %system %guest %wait %CPU CPU Command
11:57:42 PM 0 8 0.00 0.20 0.00 0.00 0.20 0 rcu_sched
11:57:42 PM 0 4006 0.00 0.20 0.00 0.00 0.20 0 sshd
11:57:42 PM 0 4130 0.20 0.00 0.00 0.20 0.20 0 watch
11:57:42 PM 0 5126 1.80 98.20 0.00 0.00 100.00 1 stress
11:57:42 PM 0 5632 0.00 0.20 0.00 0.00 0.20 0 pidstat
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 8 0.00 0.20 0.00 0.00 0.20 - rcu_sched
Average: 0 4006 0.00 0.20 0.00 0.00 0.20 - sshd
Average: 0 4130 0.20 0.00 0.00 0.20 0.20 - watch
Average: 0 5126 1.80 98.20 0.00 0.00 100.00 - stress
Average: 0 5632 0.00 0.20 0.00 0.00 0.20 - pidstat