我似乎總是想以最節能的方式,用自然界里最平常的東西來造各種東西。—— 艾倫·麥席森·圖靈
發展歷程
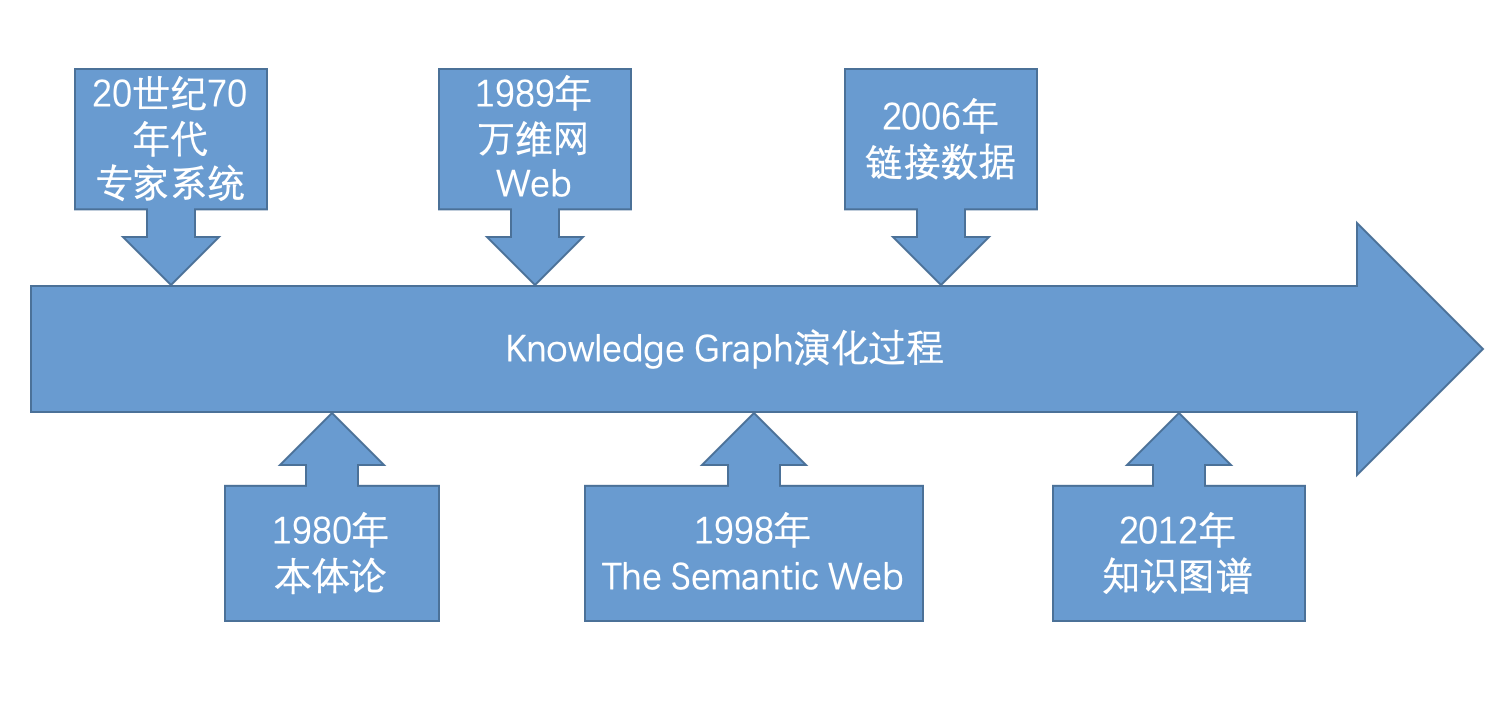
知識圖譜(Knowledge Graph)的歷程發展可以追溯到20世紀70年代誕生的專家系統,專家系統是一個具有大量的專門知識與經驗的程序系統,它應用人工智能技術和計算機技術,根據某領域一個或多個專家提供的知識和經驗,進行推理和判斷,模擬人類專家的決策過程,以便解決那些需要人類專家處理的復雜問題。
1984年,Douglas Lenat設立的Cyc是本體知識庫。
1989年,Tim Berners-Lee發明了萬維網。
1998年,Tim Berners-Lee再次提出語義網,語義網是能夠根據語義進行判斷的智能網絡,實現人與電腦之間的無障礙溝通。它好比一個巨型的大腦,智能化程度極高,協調能力非常強大。
2006年,Tim Berners-Lee提出鏈接數據(Linked Data)的概念,數據不僅僅發布於語義網中,而要建立起數據之間的鏈接從而形成一張巨大的鏈接數據網。
2007年,DBpedia項目是目前已知的第一個大規模開放域鏈接數據。
2012年,Google提出了知識圖譜的概念。
構建
隨着感知智能的慢慢成熟,人工智能進入從感知智能(主要集中在圖像、視頻、語音方面)向認知智能(自然語言處理、知識推理、因果分析等)升級之路,而知識圖譜是認知智能領域中最主要的技術之一。
在知識圖譜構建技術挑戰中,領域內知識表示建模、實體識別與實體鏈接、關系事件抽取、隱性關系發現等技術是當前研究的熱點。
構建知識圖譜流程包含信息抽取、知識表示、知識融合、知識推理四個階段。從最原始的結構化、半結構化、非結構化數據出發,采用一系列自動或者半自動的技術手段,通過批式和流式進行構建。
結構化數據一般存在於關系性數據庫中,但是也存在數據質量差,數據標准不統一,元數據缺少等問題。通過數據清洗,數據標准化,異構數據源的融合等過程來構造知識圖譜。
非結構化需要用到實體識別和關系抽取等步驟。實體識別后需要進行實體鏈接,實體鏈接是將已識別出的實體與已有知識庫中對應實體進行鏈接,有基於規則的算法和基於深度學習的方法。關系抽取更具挑戰性,涉及指代消解等難點,比如,一段文本中有很多代詞的指定,這些代詞需要找到具體的實體,從中再抽取到關系,越來越多的人使用深度強化學習等技術應用於關系抽取,提高其抽取的效果。
構建隱性關系,顯性關系指原始數據直接抽取出來的關系,隱性關系是通過數據挖掘、圖挖掘等計算出來的關系。
應用
目前知識圖譜在多個不同的領域得到了廣泛應用,主要集中在社交網絡、金融、人力資源與招聘、保險、廣告、物流、零售、醫療、電子商務等領域。
掃碼關注,或搜索大數據與知識圖譜:
