
本文源自參考《Think in Java》,多篇博文以及閱讀源碼的總結
前言
Java的集合其實就是各種基本的數據結構(棧,隊列,hash表等),基於業務需求進而演變出的Java特有的數據結構(因為不僅僅是基本數據結構)。現在,我們以數據結構的視角來看看Java的集合到底是什么樣子。並分析他們的性能。
一 JAVA集合體系
JAVA的集合體系分為兩類,Collection接口和Map接口
主要分為三種:
- Set。無插入順序的不重復數據集接口(集合演變而來)
- List。有插入順序的數據集接口(隊列演變而來)
- Map。Key-Value的鍵值對數據集接口(Hash表演變而來)
其中Set和List繼承自Collection接口,Map則就是Map接口。
接口中都定義了一些基本增刪改查的方法。
具體繼承體系如下圖:
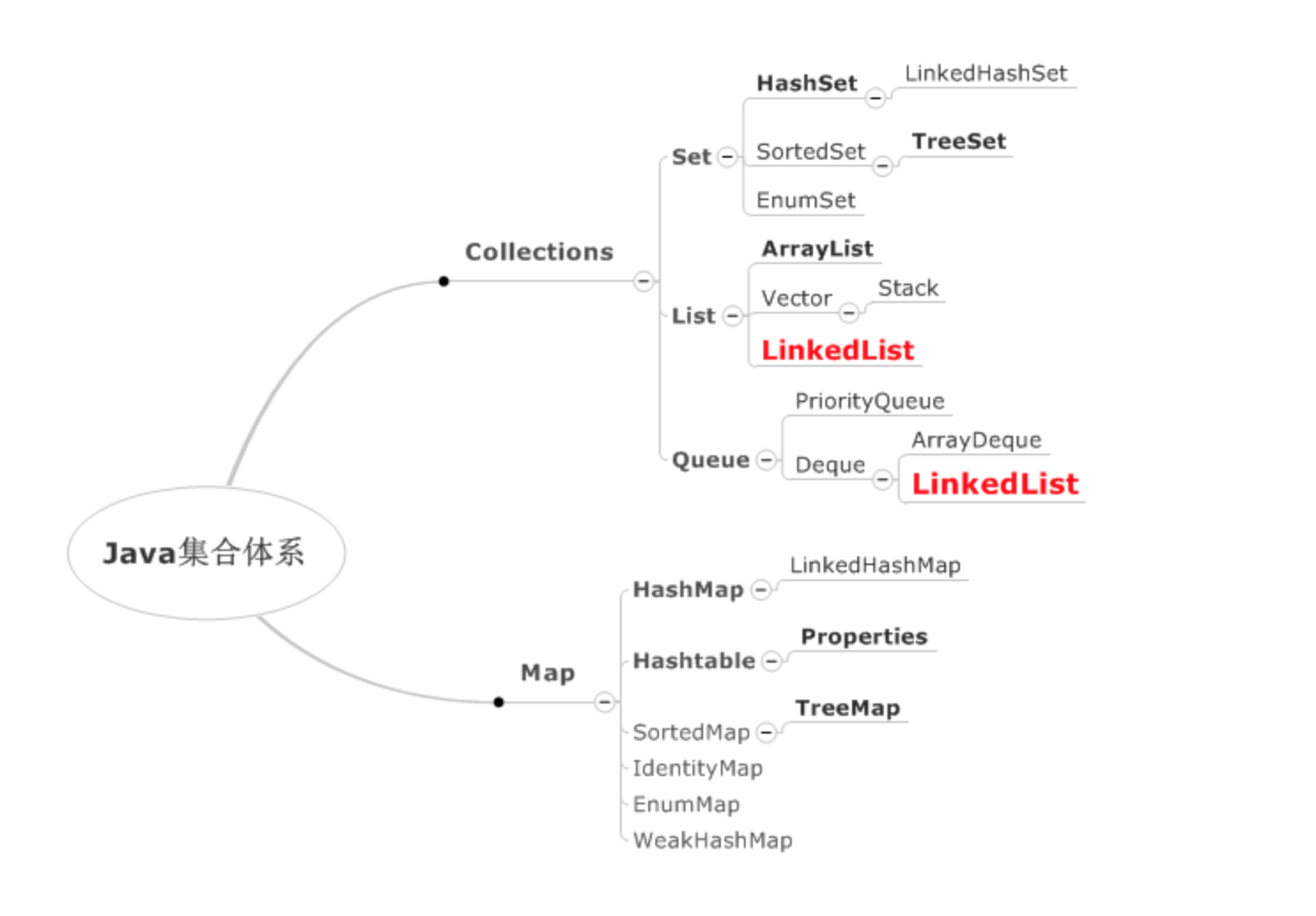
基本可以從名字知道集合的內部數據結構。
- 看后綴,有Set,List,Map后綴的集合,代表着該集合的基本結構,所以會具有以上所說的特性。
- 看前綴,前綴往往代表着該數據結構的具體實現方式。一般有這幾種:
- Hash或者Array,代表着以哈希(基本)數組實現的數據結構。
- Linked,代表着集合內各個數據之間存在鏈表關系。
- Tree或者Sorted,代表着內部使用紅黑樹實現了排序。(需要提供Comparator或者實現Comparable)
下面大略說下每個集合的數據結構,懶得貼源碼了。
1.1 List
最常用的List就是ArrayList和LinkedList了,在此不討論並發的List集合。
討論下底層源碼對它們的具體實現。
1.1.1 ArrayList
使用JAVA的基本數組實現的動態數組集合,源碼底層維護着List的容量與實際長度。
因為使用的基本數組,不像哈希數組一樣需要考慮哈希碰撞問題,因此負載因子默認為1。當List數組容量不夠時才進行擴容,擴容的倍數為1.5倍。
通過Arrays.copyOf方法,返回復制的新數組。Arrays.copyOf底層調用的System.arraycopy方法。而在ArrayList初始化時,如果不指定初始數組長度,在JDK1.6之后默認初始長度為0,在JDK1.6之前則默認為10。在JDK1.6后,ArrayList在第一次擴容時,如果擴容長度不足10,則會直接擴容到10。
具體集合怎么使用就不廢話了。
1.1.2 LinkedList
這是一個雙向鏈表,其中節點用的是LinkedList的內部類。和數據結構中的鏈表差不多。可以用它實現棧和隊列。
1.1.3 ArrayList與LinkedList比較
很明顯,ArrayList是某種程度上的哈希表,適合隨機讀,但是不適合在集合中間插入和刪除(會造成后續數據的位移)。
而LinkedList適合在頭尾部插入刪除,不適合隨機讀。
值得一提的是ArrayList隨機讀的時間復雜度是O(1),LinkedList是O(n)。而ArrayList在中間插入和刪除的時間復雜度是O(n),LinekdList在中間插入刪除時間復雜度也是O(n)
可以明顯看出來ArrayList在插入刪除上和LinkedList理論上所用的時間是一個級別的,但是ArrayList慢於LinkedList是因為在修改集合后需要進行其他數組數據的移動,而LinkedList則是查找節點花費了O(n),不需要額外移動數據,所以在同樣數據量時,LinkedList進行數據修改優於ArrayList。
1.2 Map
最常用的Map就是HashMap和TreeMap。
1.2.1 HashMap
HashMap是底層用哈希數組實現的Map。HashMap就是一個個Entry(Key-Value鍵值對)存儲在一個哈希數組上(Entry是HashMap的內部類)。
哈希數組的使用不可避免的需要考慮哈希碰撞問題,常用的解決方案有:
- 拉鏈法
- 再哈希法
- 開放地址法
- 建立公共溢出區。
在JDK里,使用的就是拉鏈法解決的哈希碰撞問題,因此每個哈希數組上的數組元素(又被稱為桶——bucket),都是一個鏈表的表頭。這樣基本保證了HashMap的平均查找時間是O(1)。
HashMap的負載因子為0.75
但是當出現頻繁哈希碰撞時,會導致某個鏈表過長進而導致了查找時間會趨近於O(n)。對此JDK原本的解決方案是設置負載因子為0.75。當哈希表總負載量達到0.75時,就會進行擴容,擴容為原本的2倍。這樣當數據平均下來后,不太容易出現過長的鏈表(因為擴容會分解鏈表重新放入桶中)。
但是這並沒有解決特殊情況下查找效率的問題,只是讓這種特殊情況更難以出現了。
JDK1.8中 HashMap出現了紅黑樹
因此在JDK1.8中又做出了改進,當某個桶中的鏈表的長度大於8時。鏈表會重構成一個紅黑樹。這樣保證了HashMap的最壞時間復雜度也僅僅是O(logn)。同時負載因子引起的擴容也保證了紅黑樹的重構不會頻繁發生,不會因為頻繁建樹導致過多的性能開銷。
HashMap的初始化與擴容
另外值得一說的就是HashMap在不知道初始長度進行初始化時,JDK1.6前默認長度為16,JDK1.6后默認長度為0。基本在JDK1.6中,需要初始化底層容器的集合都做出了這種優化。不會提前構造底層容器造成開銷,會等到使用時才進行底層的初始化。
而HashMap默認長度設置為16,並且每次擴容都是2倍。這是為了方便底層的哈希數組進行取模時的運算,可以把取模的除法運算改寫成位移運算,提升性能。
並且在JDK1.8中,HashMap關於取模運算還做了另一個優化。在JDK1.8之前,每次哈希數組擴容時,鏈表里的數據都會再次進行哈希運算。而在JDK1.8后,不需要再進行運算了,只需要在每個桶中選擇一半數據往后移動oldLength位就行(oldLength是集合在擴容前的容量)。
1.2.2 TreeMap
而另一個常用的Map——TreeMap,底層就是用JAVA寫了一個紅黑樹,感覺沒什么好說的。有興趣的可以回去翻翻數據結構的書。
1.2.3 LinkedHashMap
HashMap的每個Node還會以插入順序相互關聯成為雙向鏈表。
1.3 Set
Set主要是SortedSet和HashSet。打開源碼一看,分別new了一個TreeMap和HashMap,然后把數據存在了Key里。嗯,這就是Set的底層實現了。