簡介
GlusterFS是一個可伸縮的分布式文件系統,適用於雲存儲和媒體流等數據密集型任務。實現了全部標准POSIX接口,並用fuse實現虛擬化,讓用戶看起來就像是本地磁盤一樣。能夠處理千數量級的客戶端。
特征:
- 容量可以按比例的擴展,且性能卻不會因此而降低。
- 廉價且使用簡單,完全抽象在已有的文件系統之上。
- 擴展和容錯設計的比較合理,復雜度較低
- 適應性強,部署方便,對環境依賴低,使用,調試和維護便利
安裝
在生產中,網絡要求全部千兆環境,gluster 服務器至少有 2 塊網卡,1 塊網卡綁定供 gluster 使用,剩余一塊分配管理網絡 IP,用於系統管理。如果有條件購買萬兆交換機,服務器配置萬兆網卡,存儲性能會更好。網絡方面如果安全性要求較高,可以多網卡綁定。
【注意】GlusterFS將動態生成的配置文件存儲在/var/lib/glusterd,如果GlusterFs無法寫入此文件,會導致集群不穩定,或者脫機。建議為創建單獨的分區,以減少發生這種情況的機會。
- 每個主機至少有兩個磁盤,一個用於安裝操作系統,一個用於GlusterFS存儲。
- 設置NTP,確保集群時間統一。
系統環境
| IP | 主機名 |
|---|---|
| 192.168.229.130 | server1 |
| 192.168.229.131 | server2 |
| 192.168.229.132 | server3 |
- 時間同步
[root@server1 ~]# ntpdate 0.asia.pool.ntp.org
-
配置各主機可通過主機名解析IP地址 [略]
-
格式化磁盤
三個節點都要執行此操作
[root@server1 ~]# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1310656 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242624, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@server1 ~]# mkdir -p /data/brick1
[root@server1 ~]# echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstab
[root@server1 ~]# mount -a && mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=1005092k,nr_inodes=251273,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_prio,net_cls)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
configfs on /sys/kernel/config type configfs (rw,relatime)
/dev/mapper/cl-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
selinuxfs on /sys/fs/selinux type selinuxfs (rw,relatime)
systemd-1 on /proc/sys/fs/binfmt_misc type autofs (rw,relatime,fd=33,pgrp=1,timeout=300,minproto=5,maxproto=5,direct)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
hugetlbfs on /dev/hugepages type hugetlbfs (rw,relatime,seclabel)
mqueue on /dev/mqueue type mqueue (rw,relatime,seclabel)
/dev/sda1 on /boot type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,seclabel,size=203216k,mode=700)
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
[root@server1 ~]#
可以看到 /dev/sdb1 已經掛在到 /data/brick1
安裝GlusterFS
安裝glusterfsyum倉庫
yum install centos-release-gluster41.noarch
[root@server3 ~]# cat /etc/yum.repos.d/CentOS-Gluster-4.1.repo
# CentOS-Gluster-4.1.repo
#
# Please see http://wiki.centos.org/SpecialInterestGroup/Storage for more
# information
[centos-gluster41]
name=CentOS-$releasever - Gluster 4.1 (Long Term Maintanance)
baseurl=http://mirror.centos.org/$contentdir/$releasever/storage/$basearch/gluster-4.1/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Storage
[centos-gluster41-test]
name=CentOS-$releasever - Gluster 4.1 Testing (Long Term Maintenance)
baseurl=http://buildlogs.centos.org/centos/$releasever/storage/$basearch/gluster-4.1/
gpgcheck=0
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-SIG-Storage
安裝軟件
yum install glusterfs-server
啟動glusterfs
[root@server1 ~]# systemctl start glusterd.service
[root@server1 ~]# systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/usr/lib/systemd/system/glusterd.service; disabled; vendor preset: disabled)
Active: active (running) since Mon 2019-06-10 11:23:13 EDT; 7s ago
Process: 4506 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 4507 (glusterd)
CGroup: /system.slice/glusterd.service
└─4507 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Jun 10 11:23:13 server1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Jun 10 11:23:13 server1 systemd[1]: Started GlusterFS, a clustered file-system server.
[root@server1 ~]#
glusterd服務充當Gluster彈性卷管理器,監視glusterfs進程,並協調動態卷操作,例如跨多個存儲服務器添加和刪除卷。
將存儲主機加入受信任主機池
在任意開啟glusterd服務的主機上,將其他主機加入到受信任主機池
[root@server1 ~]# gluster peer probe server2
peer probe: success.
[root@server1 ~]# gluster peer probe server3
peer probe: success.
[root@server1 ~]#
查看主機池中主機狀態
[root@server1 ~]# gluster peer status
Number of Peers: 2
Hostname: server2
Uuid: b1d87a2d-83bb-4412-9d21-c22007ce2c33
State: Accepted peer request (Connected)
Hostname: server3
Uuid: 033444d4-886d-4a18-a051-3c537b9d75f5
State: Accepted peer request (Connected)
[root@server1 ~]#
【注意】 一旦主機池建立,只能由主機池中的主機添加新的主機,不能由新主機探測已經存再的主機池
設置一個GlusterFS卷
- 在所有的節點上執行
mkdir /data/brick1/gv1
- 在任一台服務器上執行
gluster volume create gv1 replica 3 server1:/data/brick1/gv1 server2:/data/brick1/gv1 server3:/data/brick1/gv1
gluster volume start gv1
- 確認volume啟動成功
[root@server1 brick1]# gluster volume info
Volume Name: gv1
Type: Replicate
Volume ID: 5bfedb9a-b5df-4564-bbdc-20f57ad2f260
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 3 = 3
Transport-type: tcp
Bricks:
Brick1: server1:/data/brick1/gv1
Brick2: server2:/data/brick1/gv1
Brick3: server3:/data/brick1/gv1
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
performance.client-io-threads: off
測試GlusterFS 卷
在其中一台服務器掛載卷。通常,是從外部機器(稱為“客戶機”)執行此操作。
由於使用這種方法將需要在客戶機上安裝額外的包,所以此處將使用其中一個服務器作測試。
mount -t glusterfs server1:/gv1 /mnt
for i in `seq -w 1 100`; do cp -rp /var/log/messages /mnt/copy-test-$i; done
查看客戶端掛載點
[root@server1 brick1]# ls -lA /mnt/copy* | wc -l
100
查看每個server的 GlusterFS 掛載點
[root@server1 brick1]# ls -lA /data/brick1/gv1/copy*
正常應該可以在每個server上看到100個文件
GlusterFS卷
分布式卷
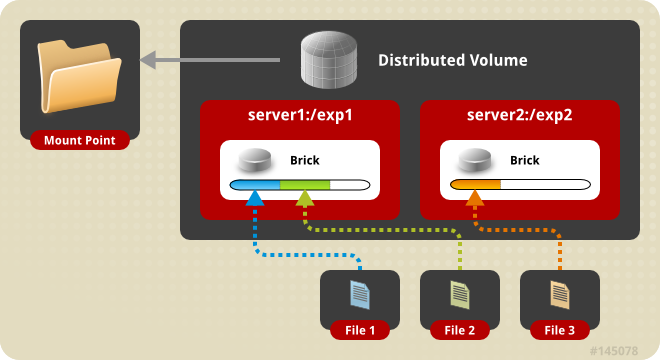
這是默認的glusterfs卷i。如果沒有指定卷的類型,則在創建卷時,默認選項是創建分布式卷。在這里,文件分布在卷中的各個bricks上。因此,file1可以只存儲在brick1或brick2中,但不能同時存儲在這兩個文件中。因此沒有數據冗余。這樣一個存儲卷的目的是方便和廉價地擴展卷大小。然而,這也意味着磚塊故障將導致數據完全丟失,必須依賴底層硬件來保護數據丟失。
創建一個三節點的分布式卷
[root@server1 brick1]# mkdir /data/brick1/exp2
[root@server1 brick1]# gluster volume create test-volume server1:/data/brick1/exp2 server2:/data/brick1/exp2 server3:/data/brick1/exp2
volume create: test-volume: success: please start the volume to access data
查看volume信息
[root@server1 brick1]# gluster volume info
Volume Name: test-volume
Type: Distribute
Volume ID: 6ca102ae-9de8-4b74-a203-d008575a3e16
Status: Created
Snapshot Count: 0
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: server1:/data/brick1/exp2
Brick2: server2:/data/brick1/exp2
Brick3: server3:/data/brick1/exp2
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
復制式卷
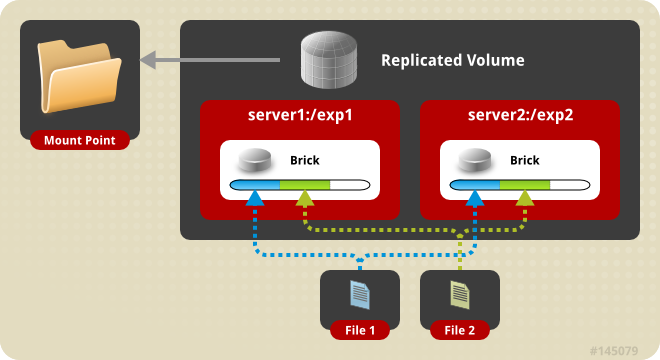
Replicated: 復制式卷,類似 RAID 1
在復制卷中,解決了分布式卷中面臨的數據丟失問題。在創建卷時,replica 數必須等於 volume 中 brick 所包含的存儲服務器數,可用性高,這種卷的一個主要優點是,即使一個塊失敗,仍然可以從它的復制塊訪問數據。這樣的卷用於更好的可靠性和數據冗余。
創建具有兩個server的復制卷
[root@server1 brick1]# gluster volume create test-volume3 replica 2 transport tcp server1:/data/brick1/test1/ server2:/data/brick1/test1/
Replica 2 volumes are prone to split-brain. Use Arbiter or Replica 3 to avoid this. See: http://docs.gluster.org/en/latest/Administrator%20Guide/Split%20brain%20and%20ways%20to%20deal%20with%20it/.
Do you still want to continue?
(y/n) y
volume create: test-volume3: success: please start the volume to access data
糾錯卷
Dispersed Volume基於ErasureCodes(糾錯碼)提供了對磁盤或服務器故障的空間有效保護。它將原始文件的編碼片段存儲到每個塊中,以一種只需要片段子集就可以恢復原始文件的方式存儲。在不丟失對數據訪問的情況下,可以丟失的塊的數量由管理員在卷創建時配置。
類似於RAID5/6。通過配置Redundancy(冗余)級別提高可靠性,在保證較高的可靠性同時,可以提升物理存儲空間的利用率。
分布式糾錯卷
分布式復制卷
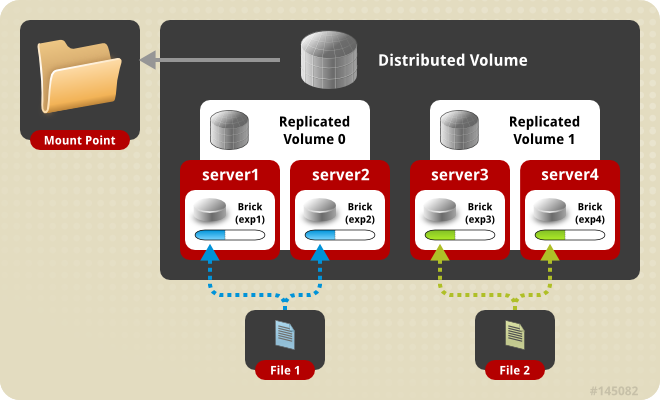
Distributed Replicated: 分布式的復制卷,最少需要4台服務器才能創建。 brick 所包含的存儲服務器數必須是 replica 的倍數,兼顧分布式和復制式的功能。
指定brick的順序也很重要,因為相鄰的磚塊會成為彼此的復制品。當由於冗余和可伸縮存儲而需要高可用性數據時,使用這種類型的卷。所以如果有8個brick和2個replica,那么前兩個brick就會變成彼此的復制品,然后是下兩個brick,以此類推。
創建volume 時 replica 2 server = 4 個節點
創建一個有兩個replica的分布式復制卷
# gluster volume create test-volume replica 2 transport tcp server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
Creation of test-volume has been successful
Please start the volume to access data
FUSE
GlusterFS是一個用戶空間文件系統,它利用FUSE(用戶空間中的文件系統)與內核VFS交互。長期以來,用戶空間文件系統的實現被認為是不可能的。FUSE就是為解決這個問題而開發的。FUSE是一個內核模塊,它支持內核VFS和非特權用戶應用程序之間的交互,並且它有一個可以從用戶空間訪問的API。使用這個API,幾乎可以使用您喜歡的任何語言編寫任何類型的文件系統,因為FUSE和其他語言之間有許多綁定。
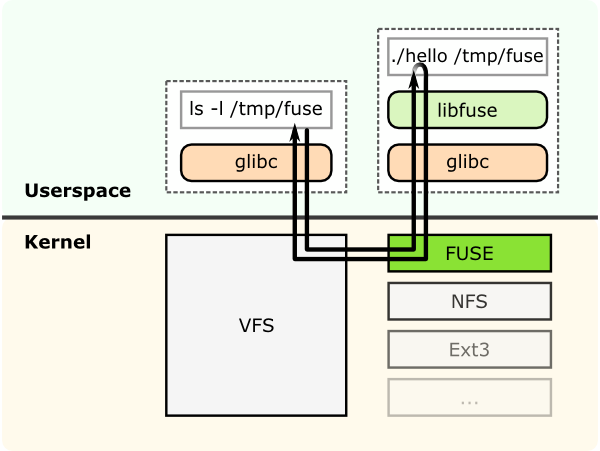
這顯示了一個文件系統“hello world”,它被編譯為一個二進制“hello”。
它使用文件系統掛載點/tmp/fuse執行。然后用戶在掛載點/tmp/fuse上發出ls -l命令。這個命令通過glibc到達VFS,由於mount /tmp/fuse對應於基於fuse的文件系統,所以VFS將其傳遞給fuse模塊。FUSE內核模塊在用戶空間(libfuse)中通過glibc和FUSE庫之后,將與實際的文件系統二進制文件“hello”進行聯系。結果由“hello”通過相同的路徑返回,並到達ls -l命令。
FUSE內核模塊與FUSE庫(libfuse)之間的通信是通過一個特殊的文件描述符進行的,該文件描述符是通過打開/dev/fuse. .獲得的這個文件可以打開多次,獲得的文件描述符被傳遞到掛載的syscall,以便將描述符與掛載的文件系統匹配起來。
Translators(未完成)
Translating “translators”:
translator將用戶請求轉換為存儲請求
1對1,1對多,1對零(例如緩存)

https://www.cnblogs.com/myvic/p/6816924.html
https://docs.gluster.org/en/latest/Quick-Start-Guide/Quickstart/
https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/