MySQL必知必會
- 聯結的使用, 子查詢, 正則表達式和基於全文本的搜索, 存儲過程, 游標, 觸發器, 表約束.
了解SQL
數據庫基礎
- 電子郵件地址薄里查找名字時, 因特網搜索站點上進行搜索, 驗證名字和密碼, 都會用到數據庫.
- 數據庫是一個以某種有組織的方式存儲的數據集合.
- 把數據庫想象成一個文件櫃, 這個文件櫃存放數據的物理位置, 不管數據是以什么形式存在以及如何組織的.
- 數據庫(database)保存有組織的數據的容器(通常是一個文件或一組文件).
- 在數據庫領域中, 保存相關資料的特定文件稱為表(table): 一種結構化的文件, 可以用來存儲某種特定類型的數據.
- 表可以存儲顧客清單, 產品目錄, 信息清單等.
- 存儲在表中的數據是一種類型的數據或一個清單.
- 數據庫中的每個表都有一個名字, 用來標識自己, 此名字是唯一的, 這表示數據庫中沒有其他表具有相同的名字.
- 數據庫名與表名結合.
- 模式(schema): 關於數據庫和表的布局及特性的信息, (可以存什么樣的數據, 數據如何分解, 各部分信息如何命名等).
- 表由列組成, 列中存儲着表中某部分的信息.
- 列(column): 表中的一個字段, 所有表都是由一個或多個列組成的.
- 數據庫中的每個列都有相應的數據類型, 數據類型(datatype)定義列可以存儲的數據種類.
- 行(row): 表中的數據是按行存儲, 所保存的每個記錄存儲在自己的行內, 表中的一個記錄. 比如一行代表一個顧客.
- 數據庫記錄(record).
- 主鍵(primary key): 一列, 其值能夠唯一區分表中每個行. 唯一標識表中每行的這個列(或這組列)稱為主鍵.
- 主鍵用來表示特定的一行.
- 任意兩行都不具有相同的主鍵值;
- 每個行都必須具有一個主鍵值(主鍵列不允許NULL值).
什么是SQL
- SQL(sequel)是結構化查詢語言(Structured Query Language)的縮寫, SQL是一種專門用來與數據庫通信的語言.
- SQL有如下的優點:
- SQL不是某個特定數據庫供應商專有的語言.
- SQL簡單易學(它的語句都是由描述性很強的英語單詞組成, 而且這些單詞數目不多).
- SQL盡管看上去很, 但它實際上是一種強有力的語言, 靈活使用其語言元素, 可以進行非常復雜和高級的數據庫操作.
MySQL簡介
DBMS(data base manage system)數據庫管理系統
- 基於共享文件系統的DBMS;
- 基於客戶機-服務器的DBMS;
- MySQL, Oracle以及Microsoft SQL Server等數據庫是基於客戶機-服務器的數據庫.
- 服務器部分是負責所有數據訪問和處理的一個軟件 --- 運行在稱為數據庫服務器的計算機上.
- 數據添加, 數據刪除, 數據更新在服務器軟件上完成.
- 服務器根據需要過濾, 丟棄和排序數據.
- 客戶即是與用戶打交道的軟件.
- MySQL是一個客戶機—服務器DBMS,因此,為了使用MySQL,需要有一個客戶機,即你需要用來與MySQL打交道(給MySQL提供要執行的命令)的一個應用.
- 每個MySQL安裝都有一個名為 mysql 的簡單命令行實用程序.
- 命名用;或\g結束, 僅按Enter不執行命令.
- help或\h獲得幫助.
- 輸入quit或exit退出命令行實用程序.
- MySQL Administrator(MySQL管理器)是一個圖形交互客戶機, 用來簡化MySQL服務器的管理.
- MySQL Query Browser為一個圖形交互客戶機,用來編寫和執行MySQL命令.
使用MySQL
- 在執行命令之前登錄到DBMS, 登錄名可以與網絡登錄名不相同, MySQL在內部保存自己的用戶列表, 並且把每個用戶與各種權限關聯起來.
- 為了連接到MySQL, 需要以下信息:
- 主機名(計算機名) --- 如果連接到本地MySQL服務器, 為localhost;
- 端口(如果使用默認端口3306之外的端口);
- 一個合法的用戶名.
- 用戶口令(如果需要).
- 使用一個USE關鍵字選擇數據庫; --- USE語句並不返回任何結果.
- 使用SHOW命令顯示數據庫/表/列/用戶/權限等信息.
SHOW DATABASES--- 返回數據庫的一個列表.SHOW TABLES--- 返回當前選擇的數據庫內可用表的列表.SHOW COLUMNS FROM customers--- 用來顯示表列, 需要給定一個表名.DESCRIBE語句是SHOW COLUMNS FROM的一種快捷方式.
SHOW STATUS--- 用於顯示廣泛的服務器狀態信息.SHOW CREATE DATABASE和SHOW CREATE TABLE--- 分別用來顯示創建特定數據庫或表的MySQL語句.SHOW GRANTS--- 用來顯示授予用戶的安全權限.SHOW ERRORS和SHOW WARNINGS--- 用來顯示服務器錯誤或講稿消息.HELP SHOW--- 顯示SHOW語句.
檢索數據
SELECT語句從表中檢索一個或多個數據列.- 想選擇什么, 以及從什么地方選擇.
SELECT prod_name--- 從products表中檢索一個名為prod_name的列. 返回的數據可能是亂序的.- 用分號
;表示一條MySQL語句的結束. - SQL語句不區分大小寫, SELECT與select是相同的.
- 關鍵字使用大寫, 所有列和表名使用小寫.
- 用分號
- 檢索多個列:
SELECT關鍵字中給出多個逗號分隔;SELECT prod_id, prod_name, prod_price FROM products;.
SELECT * FROM products--- 檢索所有列.DISTINCT關鍵字返回不同的值.SELECT DISTINCT vend_id FROM products--- 檢索不同id的行, 相同的id會被忽略.
LIMIT限制返回結果.SELECT prod_name FROM products LIMIT 5;--- 返回值不多於5行.SELECT prod_name FROM products LIMIT 5,5;--- 返回值從第5行開始的下5行. 第一個數是開始的位置, 第二個數是要檢索的行數.- 第一行是行0. 行數不夠只返回能返回的行數.
LIMIT 4 OFFSET 3--- 從行3開始取4行, 與LIMIT 3 4一個意思.
- 使用完全限定的表名:
SELECT products.prod_name FROM products;--- 玩玩限定列名.- 表名也可以是完全限定的,
SELECT products.prod_name FROM crashcourse.products;. (假定products位於crashcourse數據庫中).
排序檢索數據
ORDER BY根據需要排序檢索出數據.- 檢索出的數據一般將以它在底層表中出現的順序顯示. --- 最初添加到表中的數據順序.
- 關系數據庫設計理論認為, 如果不明確規定排序順序, 則不應該假定檢索出的數據的順序有意義.
SELECT prod_name FROM products ORDER BY prod_name;--- 以名字的進行排序.- ORDER BY 子句中使用的列將是為顯示所選擇的列. 用非檢索的列排序數據是完全合法的.
- 按多個列進行排序:
SELECT prod_id, prod_price, prod_name FROM products ORDER BY prod_price, prod_name;.
- 利用
DESC關鍵字指定排序方向為降序,SELECT prod_id, prod_price, prod_name FROM products ORDER BY prod_price DESC;.- DESC 關鍵字只應用到直接位於其前面的列名.
- 關鍵字是 ASC ( ASCENDING ), 在升序排序時可以指定它; --- 默認是升序的.
SELECT prod_price FROM products ORDER BY prod_price DESC LIMIT 1;--- prod_price DESC 保證行是按照由最昂貴到最便宜檢索的, 而LIMIT 1 告訴MySQL僅返回一行.
過濾數據
WHRER子句指定搜索條件. --- 根據特定操作或報告的需要提取表數據的子集.- 只檢索所需數據需要指定搜索條件(search criteria), 搜索條件也稱為過濾條件(filter condition).
SELECT prod_name, prod_price FROM products WHERE prod_price = 2.5;--- 只返回 prod_price 值為 2.50 的行.
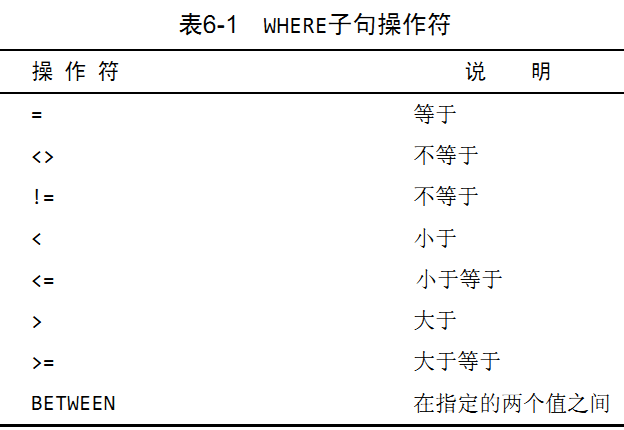
- 檢查單個值:
SELECT prod_name, prod_price FROM products WHERE prod_name = 'fuses';--- 它返回 prod_name 的值
為 Fuses 的一行.SELECT prod_name, prod_price FROM products WHERE prod_price < 10;--- 價格小於10的行.
- 不匹配檢查:
SELECT vend_id, prod_name FROM products WHERE vend_id <> 1003;等價與SELECT vend_id, prod_name FROM products WHERE vend_id != 1003;.
- 范圍值檢查:
- 為了檢查每個范圍的值, 可使用BETWEEN操作符, 需要兩個值, 即范圍的開始值和結束值.
SELECT prod_name, prod_price FROM products WHERE prod_price BETWEEN 5 AND 10;.
- 空值檢查:
- NULL無值(no value), 它與字段包含0, 空字符串或僅僅包含空格不同.
SELECT prod_name FROM products WHERE prod_price IS NULL;--- 返回沒有價格(空 prod_price 字段,不是價格為 0 )的所有產品,由於表中沒有這樣的行,所以沒有返回數據.
數據過濾
- 組合WHERE子句:
- AND子句的方式或OR子句的方式使用.
- 操作符(operator) 用來聯結或改變 WHERE 子句中的子句的關鍵字。也稱為邏輯操作符(logical operator).
SELECT prod_id, prod_price, prod_name FROM products WHERE vend_id = 1003 AND prod_price <= 10;. --- AND用在WHERE子句中用來知識檢索滿足所有給定條件的行.SELECT prod_id, prod_price, prod_name FROM products WHERE vend_id = 1002 OR prod_price vend_id = 1003;--- OR 操作符告訴DBMS匹配任一條件而不是同時匹配兩個條件.
- SQL(像多數語言一樣)在處理 OR 操作符前, 優先處理 AND 操作符。 --- 使用圓括號明確地分組相應的操作符. 不要過分依賴默認計算次序.
- IN 操作符:
- IN 操作符用來指定條件范圍, 范圍中的每個條件都可以進行匹配.
- IN 取合法值的由逗號分隔的清單, 全都括在圓括號中.
SELECT prod_name, prod_price FROM products WHERE vend_id IN(1002, 1003) ORDER BY prod_name;.- IN操作符的優點:
- 子啊使用長的合法選項清單時, IN操作符的語法更清楚且更直觀.
- 在使用IN時, 計算的次序更容易管理(因為使用的操作符更少).
- IN操作符一般比OR操作符清單執行更快.
- IN操作符的最大優點是可以包含其他SELECT語句, 使得能夠更動態地建立WHERE子句.
- IN WHERE子句中用來指定要匹配值的清單的關鍵字, 功能與OR相當.
- NOT操作符:
- NOT能否定它之后所跟的任何條件.
SELECT prod_name, prod_price FROM products WHERE vend_id NOT IN(1002, 1003) ORDER BY prod_name;.- MySQL支持使用NOT對IN、BETWEEN和EXISTS子句取反, 這與多數其他DBMS允許使用NOT對各種條件取反有很大的差別.
用通配符進行過濾
- LIKE操作符進行通配搜索, 以便對數據進行復雜過濾.
- 通配符(wildcard) 用來匹配值的一部分的特殊字符.
- 搜索模式(search pattern) 由字面值、通配符或兩者組合構成的搜索條件.
- 通配符本身實際是SQL的 WHERE 子句中有特殊含義的字符.
- LIKE 指示MySQL, 后跟的搜索模式利用通配符匹配而不是直接相等匹配進行比較.
- %表示任何字符出現任意次數,
SELECT prod_id, prod_name FROM products WHERE prod_name LIKE 'jet%';. - 通配符可在搜索模式中任意位置使用,並且可以使用多個通配符.
- %代表搜索模式中給定位置的0個、1個或多個字符.
- 下划線(_)通配符:
- _只匹配單個字符而不是多個字符.
- 通配符搜索一般比其他搜索所花時間更長:
- 不要過度使用通配符.
- 在確定需要使用通配符時, 除非絕對有必要, 否則不要把他們用在搜索模式的開始處.
- 仔細注意通配符的位置.
正則表達式進行搜索
- 正則表達式是用來匹配文本的特殊的串(字符集合).
- 正則表達式的作用是匹配文本,將一個模式(正則表達式)與一個文本串進行比較.
SELECT prod_name FROM products WHERE prod_name REGEXP '1000' ORDER BY prod_name;--- 利用關鍵字REGEXP進行正則表達式.- 為了區分關鍵字, 使用BINARY關鍵字.
SELECT prod_name FROM products WHERE prod_name REGEXP '1000|2000' ORDER BY prod_name;--- 匹配兩個條件.- []匹配幾個字符之一. [^123]卻匹配除這些字符以外的任何東西.
- [0-9]匹配范圍. 用雙斜杠表示匹配特殊字符, 比如
\\-表示查找-,\\.表示查找.;- \f --- 換頁.
- \n --- 換行.
- \r --- 回車.
- \v --- 縱向制表.
- 匹配字符類, 預定義的字符集, 稱為字符類(character class);
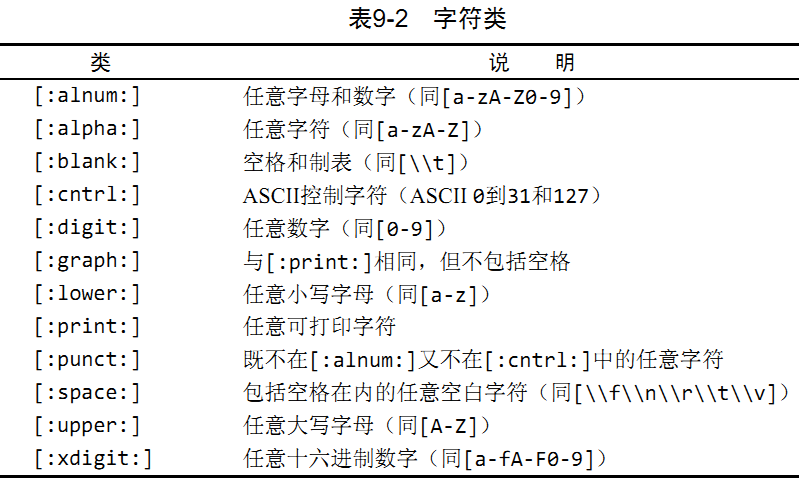

- ^ 匹配串的開始. LIKE 匹配整個串而 REGEXP 匹配子串.
創建計算字段
- 存儲在數據庫中的數據一般不是應用程序所需要的格式.
- 需要直接從數據庫中檢索出轉換、計算或格式化過的數據.
- 計算字段並不實際存在於數據庫表中, 計算字段是運行時在SELECT語句內創建.
- 字段(field) 基本上與列(column)的意思相同, 經常互換使用, 不過數據庫列一般稱為列,而術語字段通常用在計算字段的連接上.
- 拼接(concatenate) 將值聯結到一起構成單個值. MySQL則使用 Concat() 函數來實現.
- Concat() 拼接串,即把多個串連接起來形成一個較長的串.
- 使用MySQL的 RTrim() 函數來完成刪除數據右側多余的空格來整理數據.
- LTrim() (去掉串左邊的空格)以及Trim() (去掉串左右兩邊的空格).
- 別名(alias)是一個字段或值的替換名。別名用 AS 關鍵字賦予.
- AS vend_title 。它指示SQL創建一個包含指定計算的名為 vend_title 的計算字段.
- 別名有時也稱為導出列(derived column).
- 執行算術運算:
SELECT prod_id, quantity, item_price, quantity*item_price AS expended_price FROM orderitens WHERE order_num = 20005
使用數據處理函數
-
SQL支持利用函數來處理數據。函數一般是在數據上執行的,它給數據的轉換和處理提供了方便.
-
使用函數:
- 用於處理文本串(刪除或填充值, 轉換值為大寫或小寫)的文本函數.
- 用於在數值數據上進行算術操作(絕對值, 進行代數運算)的數值函數.
- 用於處理日期和時間值並從這些值中提取特定成分的日期和時間函數.
- 返回DBMS正使用的特殊信息(用戶登錄信息, 檢查版本)的系統函數.




-
Soundex()函數進行搜索時, 可以匹配所有發音類似的字符串.
-
Date(order_date)指示僅提取列的日期部分.
聚集函數
-
聚集函數(aggregate function) 運行在行組上, 計算和返回單個值的函數.

-
AVG() 只能用來確定特定數值列的平均值, 而且列名必須作為函數參數給出.
-
使用 COUNT(*) 對表中行的數目進行計數, 不管表列中包含的是空值( NULL )還是非空值.
-
使用 COUNT(column) 對特定列中具有值的行進行計數, 忽略NULL 值.
-
MAX() 函數忽略列值為 NULL 的行.
-
對所有的行執行計算,指定 ALL 參數或不給參數(因為 ALL 是默認行為).
-
只包含不同的值, 指定 DISTINCT 參數. --- 排序了相同的值.
-
組合聚集函數:
SELECT COUNT(*) AS num_items, MIN(prod_price) AS price_min, MAX(prod_price) AS price_max, AVG(prod_price) AS price_avg FROM products;
分組數據
- GROUP BY子句和HAVING子句.
- 分組是在 SELECT 語句的 GROUP BY 子句中建立的.
SELECT vend_id, COUNT(*) AS num_prods
FROM products
GROUP BY vend_id;
-
通過ID號進行分組.
-
HAVING非常類似於WHERE, WHERE過濾行, HAVING過濾組.
-
WHERE 在數據分組前進行過濾, HAVING 在數據分組后進行過濾.
SELECT vend_id, COUNT(*) AS num_prods FROM products WHERE prod_price >= 10 GROUP BY vend_id HAVING COUNT(*) >= 2; -
分組和排序(ORDER BY 和 GROUP BY)
SELECT order_num, SUM(quantity*item_price) AS ordertotal FROM orderitems GROUP BY order_num HAVING SUM(quantity*item_price) >= 50;- 進行排序
SELECT order_num, SUM(quantity*item_price) AS ordertotal FROM orderitems GROUP BY order_num HAVING SUM(quantity*item_price) >= 50 ORDER BY ordertotal; -
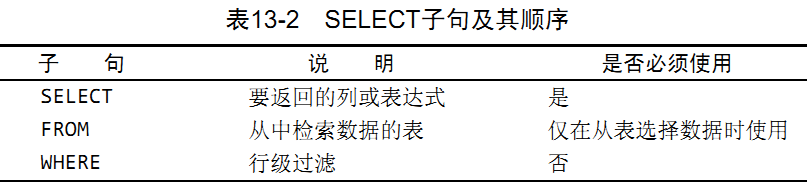
SELECT子句順序:

使用子查詢
- SELECT語句是SQL的查詢, SQL還允許創建子查詢(subquery), 即嵌套在其他查詢中的查詢.
SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id = 'TNT2');
聯結表
-
SQL最強大的功能之一就是能在數據檢索查詢的執行中聯結(join)表.
-
關系表的設計就是要保證把信息分解成多個表, 一類數據一個表.
-
外鍵為某個表中的一列, 它包含另一個表的主鍵值, 定義了兩個表之間的關系.
-
分解數據為多個表能更有效地存儲, 更方便地處理, 並且具有更大的可伸縮性.
-
使用聯結從多個數據表中檢索出數據.
-
聯結是一種機制, 用來在一條 SELECT語句中關聯表, 因此稱之為聯結.
SELECT vend_name, prod_name, prod_price FROM vendors, products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name, prod_name; -
在一條 SELECT 語句中聯結幾個表時, 相應的關系是在運行中構造的.
創建高級聯結
- 使用不同類型的聯結
- 內部聯結或等值聯結(equijoin)的簡單聯結.
- 自聯結:
SELECT p1.prod_id, p1.prod_name FROM products AS p1, products AS p2 WHERE p1.vend_id = p2.vend_id AND p2.prod_id = 'DTNTR';- 用自聯結而不用子查詢. --- 聯結比處理子查詢更快.
- 自然聯結:
- 自然聯結排除多次出現, 使每個列只返回一次.
- 外部聯結: 一個表中的行與另一個表中的行相關聯, 聯結包含了那些在相關表中沒有關聯行的行.
- 在使用OUTER JOIN語法時, 必須使用RIGHT或LEFT關鍵字指定包括其所有行的表.
SELECT customers.cust_id, orders,order_num FROM customers LEFT OUTER JOIN orders ON customers.cust_id = orders.cust_id;
- 帶聚集函數的聯結.
- 使用聯結和聯結條件:
- 注意使用的聯結類型.
- 保證使用正確的聯結條件, 否則將返回不正確的數據.
- 應該總是提供聯結條件, 否則會得出笛卡爾積.
- 一個聯結中可以包含多個表, 甚至可以采用不同的聯結類型.
組合查詢
- MySQL也允許執行多個查詢(多條 SELECT 語句), 並將結果作為單個, 查詢結果集返回.
- 組合查詢通常稱為並( union ) 或復合查詢(compound query).
- 需要用到組合查詢的地方:
- 在單個查詢中從不同的表返回類似結構的數據.
- 對單個表之賜你個多個查詢, 按單個查詢返回數據.
- 利用UNION操作符來組合數條SQL查詢.
SELECT vend_id, prod_id, prod_price FROM products WHERE prod_price <= 5 UNION SELECT vend_id, prod_id, prod_price FROM products WHERE vend_id IN (1001, 1002); - UNION 規則:
- UNION 必須由兩條或兩條以上的 SELECT 語句組成,語句之間用關鍵字 UNION 分隔.
- UNION 中的每個查詢必須包含相同的列、表達式或聚集函數.
- 列數據類型必須兼容:類型不必完全相同, 但必須是DBMS可以隱含地轉換的類型.
- UNION 從查詢結果集中自動去除了重復的行.
- 如果想返回所有匹配行,可使用 UNION ALL 而不是 UNION.
- 在用 UNION 組合查詢時, 只能使用一條 ORDER BY 子句,它必須出現在最后一條 SELECT 語句之后.
全文搜索
-
全文搜索功能進行高級的數據查詢和選擇.
- MyISAM支持全文搜索, InnoDB不支持全文搜索.
-
性能: 通配符和正則表達式匹配通常要求嘗試表中的所有行, 比較耗時.
- 使用通配符和正則表達式匹配, 很難(而且並不總是能)明確地控制匹配什么和不匹配什么.
- 智能化的選擇結果的方法.
-
使用全文本搜索時, MySQL不需要分別查看每個行, 不需要分別分析和處理每個詞.
-
SELECT 可與 Match() 和 Against() 一起使用以實際執行搜索.
-
CREATE TABLE 語句定義表 productnotes 並列出它所包含的列即可.
-
在定義之后,MySQL自動維護該索引。在增加、更新或刪除行時, 索引隨之自動更新.
SELECT note_text FROM productnotes WHERE Match(note_text) Against('rabbit');- 傳 遞 給 Match() 的 值 必 須 與FULLTEXT() 定義中的相同.
-
行越多越好 表中的行越多(這些行中的文本就越多), 使用查詢擴展返回的結果越好.
- 查詢擴展用來設法放寬所返回的全文本搜索結果的范圍;
Against('anvils' WITH QUERY EXPANSION);--- 查詢擴展.
-
布爾文本搜索:
- 要匹配的詞;
- 要排斥的詞;
- 排列提示;
- 表達式分組;
- 另一些內容.
- 即使沒有 FULLTEXT 索引也可以使用.
SELECT note_text FROM productnotes WHERE Match(note_text) Against('heavy -rope*' IN BOOLEAN MODES); .
. -
全文本搜索的使用說明:
- 在索引全文本數據時,短詞被忽略且從索引中排除.
- 帶有一個內建的非用詞(stopword)列表, 這些詞在索引全文本數據時總是被忽略.
- 許多次出現頻率很高, 索索他們沒有用處(返回太多的結果).
- 表中的行數少於3行, 全文搜索不返回結果.
- 忽略詞中的單引用. --- don't被認為是dont.
- 不具有詞分割符的語言不能恰當地返回全文搜索結果.
- 僅在MyISAM數據庫引擎中支持全文本搜索.
插入數據
- INSERT是用來插入(或添加)行到數據庫表的:
- 插入完整的行;
- 插入行的一部分;
- 插入多行;
- 插入某些查詢的結果.
- INSERT語句一般不會產生輸出.
更新和刪除數據
- 更新數據 --- UPDATE語句. 要更新的表; 列名和他們的新值; 確定要更新行的過濾條件.
- 更新表中特定行;
- 更新表中所有行.
UPDATE customers SET cust_emial = 'elmer@fudd.com' WHERE cust_id = 10005; - 刪除數據: DELETE語句
DELETE FROM customers WHERE cust_id = 10006;DELETE FROM 要求指定從中刪除數據的表名, WHERE 子句過濾要刪除的行.
- 許多SQL程序員使用 UPDATE 或 DELETE 時所遵循的習慣:
- 除非確實打算更新和刪除每一行,否則絕對不要使用不帶 WHERE子句的 UPDATE 或 DELETE 語句.
- 保證每個表都有主鍵, 盡可能像 WHERE 子句那樣使用它.
- 在對 UPDATE 或 DELETE 語句使用 WHERE 子句前,應該先用 SELECT 進行測試,保證它過濾的是正確的記錄,以防編寫的 WHERE 子句不正確.
- 使用強制實施引用完整性的數據庫, 這樣MySQL將不允許刪除具有與其他表相關聯的數據的行.
創建和操作表
- 使用具有交互式創建和管理表的工具 或 表也可以直接用MySQL語句操縱.
- 利用CREATE TABLE創建表, 必須給出下列信息:
- 新表的名字, 在關鍵字CREATE TABLE 之后給出.
- 表列的名字和定義, 用逗號分隔.
CREATE TABLE custeomers ( cust_id int NOT NULL AUTO_INCREMENT, cust_name char(50) NOT NULL, PRIMARY KEY (cust_id) ## 主鍵值 ) ENGING=InnoDB; - 主鍵值必須唯一, 表中的每個行必須具有唯一的主鍵值.
- AUTO_INCREMENT 告訴MySQL,本列每當增加一行時自動增量.
- DEFAULT 關鍵字指定.
- MySQL有一個具體管理和處理數據的內部引擎.
- 如果省略 ENGINE= 語句, 則多數SQL語句都會默認使用它。
- InnoDB 是一個可靠的事務處理引擎,它不支持全文本搜索;
- MEMORY 在功能等同於 MyISAM ,但由於數據存儲在內存(不是磁盤)中, 速度很快(特別適合於臨時表).
- MyISAM 是一個性能極高的引擎, 它支持全文本搜索(參見第18章), 但不支持事務處理.
- RENAME TABLE語句可以重命名一個表.
RENAME TABLE customers2 TO customers;.
- ALTER TABLE 用來更改表列(或其他諸如約束或索引等對象).
- DROP TABLE 用來完整地刪除一個表. --- 永久刪除該表.
使用視圖
- 視圖是虛擬的表, 視圖只包含使用時動態檢索數據的查詢.
- 使用視圖:
- 視圖用CREATE VIEW語句來創建.
- 使用SHOW CREATE VIEW viewname; 來查看創建視圖的語句.
- 用DROP刪除視圖, 其語法為DROP VIEW viewname;
- CREATE OR REPLACE VIEW來更新視圖.
使用存儲過程
- 執行一個處理需要針對許多表的多條MySQL語句.
- 存儲過程簡單來說,就是為以后的使用而保存的一條或多條MySQL語句的集合.
CALL productpricing(@pricelow, @pricehigh, @priceaverage); # 執行名為productpricing的存儲過程, 計算並返回產品的最低, 最高和平均價格. CREATE PROCEDURE productpriting() BEGIN SELECT Avg(prod_price) AS priceaverage FROM products; END;
使用游標
- 游標(cursor)是一個存儲在MySQL服務器上的數據庫查詢, 它不是一條 SELECT 語句,而是被該語句檢索出來的結果集.
- 游標主要用於交互式應用,其中用戶需要滾動屏幕上的數據, 並對數據進行瀏覽或做出更改。
- 游標用 DECLARE 語句創建, DECLARE 命名游標, 並定義相應的 SELECT 語句,根據需要帶 WHERE 和其他子句.
CREATE PROCEDURE processoerders() BEGIN -- 聲明一個游標 DECLARE ordernumbers CURSOR FOR SELECT order_num FROM orders; END; - OPEN ordernumbers; --- 打開游標;
- CLOSE ordernumbers; --- 關閉游標.
使用觸發器
- 觸發器是MySQL響應以下任意語句而自動執行的一條MySQL語句(或位於 BEGIN 和 END 語句之間的一組語句).
- DELETE;
- INSERT;
- UPDATE.
- 觸發器用 CREATE TRIGGER 語句創建.
CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added'; - 更新觸發器:
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors FOR EACH ROW SET new.VEND_STATE = Upper(NEW.vend_state);
管理事務處理
- 利用COMMIT和ROLLBACK語句來管理事務處理.
- 事務處理(transaction processing)可以用來維護數據庫的完整性, 它保證成批的MySQL操作要么完全執行,要么完全不執行.
- 關於事物處理的幾個術語:
- 事務(transaction): 指一組SQL語句;
- 回退(rollback): 指撤銷指定SQL語句的過程;
- 提交(commit): 指將未存儲的SQL語句結果寫入數據庫表;
- 保留點(savepoint): 指事務處理中設置的臨時占位符(place-holder), 你可以對它發布回退(與回退整個事務處理不同).
START TRANSACTION標識事務的開始.- 一般的MySQL語句都是直接針對數據庫表執行和編寫的.
全球化和本地化
- 數據庫表用來存儲和檢索數據.
- 重要術語:
- 字符集: 為字母和符號的集合.
- 編碼: 為某個字符集成員的內部表示.
- 校對: 為規定字符如何比較的指令.
SHOW CHARACTER SET--- 查看所支持的字符集完整列表.- 使用 Cast() 或 Convert ()函數進行字符集之間的轉換.
安全管理
- CREATE USER 語句創建一個新用戶賬號.
數據庫維護
- ANALYZE TABLE, 用來檢查表鍵是否正確;
- CHECK TABLE 用來針對許多問題對表進行檢查.
改善性能
- MySQL(與所有DBMS一樣)具有特定的硬件建議.
- 關鍵的生產DBMS應該運行在自己的專用服務器上。
- MySQL是用一系列的默認設置預先配置的,從這些設置開始通常是很好的。但過一段時間后你可能需要調整內存分配、緩沖區大小等.
- SHOW VARIABLES 查看當前設置;
- SHOW STATUS 查看相應狀態.
- MySQL一個多用戶多線程的DBMS,換言之,它經常同時執行多個任務;
- 總是有不止一種方法編寫同一條 SELECT 語句。應該試驗聯結、並、子查詢等,找出最佳的方法.
- 使用 EXPLAIN 語句讓MySQL解釋它將如何執行一條 SELECT 語句.
- 存儲過程執行得比一條一條地執行其中的各條MySQL語句快.
- 必須索引數據庫表以改善數據檢索的性能.
- 通過使用多條SELECT 語句和連接它們的 UNION 語句,你能看到極大的性能改進.
- 索引改善數據檢索的性能,但損害數據插入、刪除和更新的性能.
- LIKE 很慢。一般來說,最好是使用 FULLTEXT 而不是 LIKE.
- 數據庫是不斷變化的實體。一組優化良好的表一會兒后可能就面目全非了。由於表的使用和內容的更改,理想的優化和配置也會改變.