linux 串行通信接口驅動框架
在學習linux內核驅動時,不論是看linux相關的書籍,又或者是直接看linux的源碼,總是能在linux中看到各種各樣的框架,linux內核極其龐雜,linux各種框架理解起來並不容易,如果直接硬着頭皮死記硬背,意義也不大。
博主學習東西一直秉持着追本溯源的態度,要弄清一個東西是怎么樣的,如果能夠了解它的發展,了解它為什么會變成這樣,理解起來就非常簡單了。抓住主干,沿着線頭就可以將整個框架慢慢梳理清楚。
從i2c開始
在嵌入式中,不管是單片機還是單板機,i2c作為板級通信協議是非常受歡迎的,尤其是在傳感器的使用領域,其主從結構加上對硬件資源的低要求,穩穩地占據着主導地位。
我們就以i2c協議為例,聊一聊linux內核中串行通信接口框架。
(注:在這篇文章只討論大致框架,並不涉及具體細節,linux內核驅動部分的框架分得很細,無法全部覆蓋,但求建立一個大體的概念)
單片機中的i2c
每個MCU基本上都會集成硬件i2c控制器,在單片機編程中,對於操作硬件i2c控制器,我們只需要操作一些相應的寄存器即可實現數據的收發。
那如果沒有硬件i2c控制器或者i2c控制器不夠用呢?
事情也不麻煩,我們可以使用兩個gpio來軟件模擬i2c協議,代碼不過幾十行,雖然i2c協議本身有一定的復雜性,但是如果僅僅是實現通信,在單片機上還是非常簡單的。
單片機中實現i2c程序
我們不妨回想一下,在單片機中編寫一個i2c驅動程序的流程:
以sht31(這是一個常用的i2c接口的溫濕度傳感器)為例,剛入行的新手程序員可能這樣寫主機程序(偽代碼):
int sht31_read_temprature(){ //讀取溫度值實現函數
設置i2c寫寄存器,發送i2c器件地址
設置i2c寫寄存器,發送i2c寄存器地址
設置i2c讀
temperature = 讀取目標器件發回的數據
return temperature;
}
int sht31_read_humidity(){ //讀取濕度值實現函數
設置i2c寫寄存器,發送i2c器件地址
設置i2c寫寄存器,發送i2c寄存器地址
設置i2c讀
humidity = 讀取目標器件發回的數據
return humidity;
}
....
程序優化
每次讀寫函數都對硬件i2c的寄存器進行設置,很顯然,這樣的代碼有很多重復的部分,我們可以將重復的讀寫部分提取出來作為公共函數,寫成這樣:
array sht31_read_data(sht31數據寄存器地址){
設置i2c寫寄存器,發送i2c器件地址
設置i2c寫寄存器,發送i2c寄存器地址
設置i2c讀
return 讀取目標器件發回的數據;
}
所以,上例中的讀溫濕度就可以寫成這樣:
array sht31_read_temprature(){
return sht31_read_data(sht31溫度數據寄存器地址);
}
array sht31_read_humidity(){
return sht31_read_data(sht31濕度數據寄存器地址);
}
...
經過這一步優化,這個驅動程序就變成了兩層:
- i2c硬件操作部分,比如i2c與設備的讀寫,在同一平台上,硬件讀寫的寄存器操作都是一致的。
- 設備的操作函數,不同的設備有不同的寄存器,對於存儲設備而言就是存取數據,對於傳感器而言就是讀寫傳感器數據,需要讀寫設備時,直接調用第一步中的接口,傳入不同的參數。
可以明顯看到的是,第一步中的i2c操作函數部分可以被抽象出來。
這就是軟件的分層
如果你仔細看了上面的示例,基本上就理解了軟件分層是什么概念,它其實就是不斷地將公共的部分和重復代碼提取出來,將其作為一個統一的模塊,向外提供訪問的接口。
從宏觀上來看程序就被分成了兩部分,由於是調用與被調用的關系,所以層次結構可以更明顯地體現他們之間的關系。
分層的好處
最直觀地看過去,軟件分層第一個好處就是節省代碼空間,代碼量更少,層次更清晰,對於代碼的可讀性和后期的維護都是非常大的好處。
將相關的數據和操作封裝成一個模塊,對外提供接口,屏蔽實現細節,便於移植和協作,因為在移植和修改時,只需要修改當前模塊的代碼,保持對外接口不變即可,減少了移植和維護成本。
舉個例子:在上述的代碼中,如果將sht31換成其他i2c設備,我只需要修改設備的操作函數部分,而i2c的讀寫部分可以復用.又或者同樣的設備,切換成了spi協議通信,那么,設備的操作函數部分可以不用修改,只需要將i2c硬件讀寫換成spi硬件讀寫。
程序的再次優化
在程序的第一次優化中,i2c被抽象出兩層:i2c硬件讀寫層和i2c的應用層(暫且這么命名吧),讀寫層只負責讀寫數據,而應用層則根據不同設備進行不同的讀寫操作,調用讀寫層接口。
划分成讀寫層和驅動層之后,在空間上和程序復用性上已經走了一大步。
但是在之后的開發中又發現一個問題:對於單個的廠商而言,生產的設備往往具有高度相似的寄存器操作方式,比如對於我們常用的sht3x(溫濕度傳感器)而言,這些系列的傳感器設備之間的不同僅僅是測量范圍、測量精度的不同,其他的寄存器配置其實是一樣的,有經驗的程序員就想到可以抽象出這樣一個統一接口來針對所有這些同系列設備:
sht3x_init(int sht3x_type,int measurement_range,int resolution){
switch(sht3x_type){
case sht31:
set_measurement_range(sht31,measurement_range);
set_resolution(sht31,resolution);
break;
case sht35:
set_measurement_range(sht35,measurement_range);
set_resolution(sht35,resolution);
break;
case ...
}
}
僅僅是在設置的時候設置不同的測量范圍和精度,而其他的設置,數據讀寫部分都是完全相同的。
對於這些同系列的設備,我們同樣可以抽象出一個驅動層,以sht3x為例,同系列設備的操作變成這樣:
- i2c硬件讀寫層。
- sht3x的公共操作函數,通過調用上層接口實現初始化、設置溫度閾值等函數。
- 具體設備的操作函數,對於sht31而言,通過傳入sht31的參數,調用上層接口來讀寫sht31中的數據,需要傳入的參數主要是i2c地址,設置精度等sht3x系列之間的差異化部分。
這樣,對於sht3x而言,用戶在使用這一類設備的時候就只需要簡單地調用諸如sht3x_init(u8 i2c_addr),sht3x_set_resolution(u8 resolution)這一類的函數即可完成設備的操作,通過傳入不同的參數執行不同的操作。
這里貼上一個圖來加深理解:

到這里,對於一個單片機上的i2c設備而言,基本上已經有了比較好的層次結構:
- i2c硬件讀寫層
- 驅動層(主要是解決同系列設備驅動重復的寄存器操作問題)
- 設備層(應用程序調用上一層接口實現具體的設備讀寫)
將上述分層的1.2步集成到系統中,用戶只需要調用相應接口直接就可以操作到設備,對用戶來說簡化了操作流程,對系統來說節省了程序空間。
到這里,這一份i2c程序就已經比較完善了,當需要添加sht3x設備時,只需要在設備層添加即可。
當需要添加其他i2c設備時,則需要提供驅動層和設備層的實現而復用硬件讀寫層。
當需要將sht3x驅動程序移植到另一個平台時,只需要修改i2c硬件讀寫層,因為平台之間的i2c讀寫操作可能不一致,驅動層和設備層不需要修改。
整個分層的思想就是復用。大大節省了調試時間,在debug的時候也能很方便地定位是哪一部分出了問題,同時可以將程序發布給其他用戶,其他用戶根據需要可以很方便地進行裁剪移植,避免浪費過多時間在同一件事情上。
再看看linux中的i2c
在單片機上可以碰到的問題,在linux系統上同樣能碰到,單片機上運行的程序一般而言不會太龐大,驅動部分更是所占甚微,所以設備驅動程序的好壞並不會太過於影響程序的執行效率。
但是在linux中,有時需要集成大量的驅動設備到系統中,同時內核代碼是多人維護的模式,所以也必須采用驅動分層的模式來提高內存使用效率,降低程序耦合性。
那么,在linux中是否也是像單片機中一樣分為i2c硬件讀寫層、驅動層、設備層即可呢?
其實大致的思想是一樣的:將硬件讀寫抽象成一層,將同系列產品驅動抽象成一層,將具體設備的添加抽象成頂層,但是具體實現完全不一樣。
與單片機中程序不一樣的是:linux中內核空間和用戶空間是區分開來的,驅動程序將會被加載到內核中,提供接口給用戶進行操作。
從單片機切換到linux的第一種解決方案
不難想到的解決方案是:分層模型不變,將上述分層中的設備層改為由驅動層直接在用戶空間注冊文件接口,用戶程序通過用戶文件對設備進行操作。
於是,分層模型變成了這樣:
- i2c硬件讀寫層
- 驅動層(主要是解決同系列設備驅動重復問題,同時在用戶空間注冊用戶接口以供訪問)
- 應用層(相對於內核而言,等於單片機分層中的設備層,應用程序通過操作文件調用上一層接口實現具體的設備讀寫)
問題就這樣得到解決。
用戶在操作用戶空間文件接口的時候,依次地通過文件接口傳遞目標設備的資源對設備進行初始化,各種設置,然后讀寫即可,對於sht3x而言,這些資源包括i2c地址、精度、閾值等等。
但是,這樣的做法的缺陷是:
- 提高了驅動程序和應用開發的耦合性,同時驅動程序不具有獨立性和安全性,程序的可移植性也很差。
- 同時,此時的驅動層對應的是同系列設備,注冊到用戶空間的接口會更加抽象,用戶需要對驅動程序進行二次開發.
想一想,當用戶需要使用sht31時,用戶還得去閱讀sht31的datasheet來查看並設置各種參數,這樣驅動和用戶程序不分離完全不符合高內聚低耦合的程序思想。
最理想的狀態自然是:
- 驅動程序本身和驅動程序需要的資源由內核統一管理,這樣才能提高驅動和管理資源的獨立性,並且擁有較好的額可移植性和安全性,提供盡量簡單的操作接口給用戶空間。
- 用戶空間只需要直接使用驅動,而不需要對驅動程序進行二次開發。
第二種解決方案
既然驅動部分無法針對單一設備,而是針對諸如sht3x這一類設備,那我們為每個單一設備添加一份描述設備信息來提供資源(i2c地址等),比如sht31、sht35分別提供一份設備描述信息,而一個驅動程序可以對應多份設備描述信息。
當需要使用某個具體設備比如sht31時,再將sht31的設備描述信息和sht3x的驅動程序結合起來,生成一個完整的sht31設備驅動程序,並在用戶空間注冊sht31文件接口,這樣文件接口就可以針對具體的設備而實現具體的操作功能,用戶可以通過簡單的參數選擇而直接使用。
同時將設備描述信息同時注冊到內核中,由內核統一管理,提高了驅動和資源管理的獨立性和安全性,同時移植性能較好。
這樣,在分層模型中,我們將設備描述信息(設備資源)部分和驅動程序放置在同一層,驅動模型就變成了這樣:
- i2c硬件讀寫層
- 驅動部分(提供系列設備的公共驅動部分)-------設備部分(提供單一設備的資源,驅動程序獲取資源進行相應配置,與驅動層為一對多的關系),統稱為驅動層
- 應用層(通過上層提供的接口對設備進行訪問)
這樣的分層有個好處,在第二層驅動層中,直接實現了每個單一設備的程序,對應用層提供簡便的訪問接口,這樣在用戶層不用再進行復雜的設置,就可以直接對設備進行讀寫。
它的分層是這樣的:
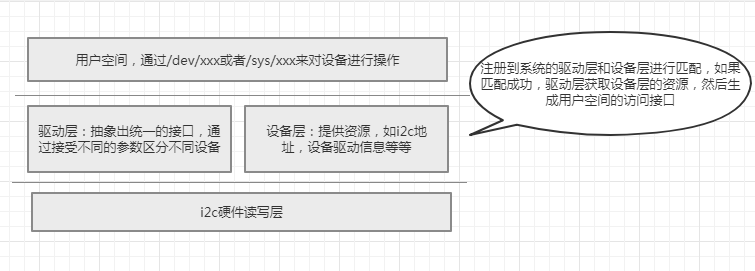
i2c硬件讀寫層
linux i2c設備驅動程序中的硬件讀寫層由struct i2c_adapter來描述,它的內容是這樣的:
struct i2c_adapter {
...
const struct i2c_algorithm algo; / the algorithm to access the bus */
void *algo_data;
int nr;
char name[48];
...
};
其中struct i2c_algorithm *algo結構體中master_xfer函數指針指向i2c的硬件讀寫函數,我們可以簡單地認為一個struct i2c_adapter結構體描述一個硬件i2c控制器。在驅動編寫的過程中,這一層的實現由系統提供。驅動編寫者只需要調用i2c_get_adapter()接口來獲取相應的adapter.
驅動層(中間層,包含設備部分和驅動部分)
linux總線機制
在上面的分層討論中可知:驅動層由驅動部分和設備部分組成,驅動部分由struct i2c_driver描述,而設備部分由struct i2c_device部分組成。
這兩部分雖然被我們分在同一層,但是這是相互獨立的,當添加進一個device或者driver,會根據某些條件尋找匹配的driver或者device,那這一部分匹配誰來做呢?
這就不得不提到linux中的總線機制,i2c總線擔任了這個銜接的角色,誠然,i2c總線也屬於總線的一種,i2c總線在系統啟動時被注冊到系統中,管理i2c設備。
我們先來看看描述總線的結構體:
struct bus_type {
....
const char *name;
int (*match)(struct device *dev, struct device_driver *drv);
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
int (*probe)(struct device *dev);
int (*remove)(struct device *dev);
void (*shutdown)(struct device *dev);
int (*online)(struct device *dev);
int (*offline)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
struct subsys_private *p;
};
struct subsys_private {
...
struct klist klist_devices;
struct klist klist_drivers;
unsigned int drivers_autoprobe:1;
...
};
這個結構體描述了linux中各種各樣的sub bus,比如spi,i2c,platform bus,可以看到,這個結構體中有一系列的函數,在struct subsys_private結構體定義的指針p中,有struct klist klist_devices和struct klist klist_drivers這兩項。
當我們向i2c bus注冊一個driver時,這個driver被添加到klist_drivers這個鏈表中,當向i2c bus注冊一個device時,這個device被添加到klist_devices這個鏈表中。
每有一個添加行為,都將調用總線的match函數,遍歷兩個鏈表,為新添加的device或者driver尋找對應的匹配,一旦匹配上,就調用probe函數,在probe函數中執行設備的初始化和創建用戶操作接口。
應用層
在總線的(或者驅動部分的)probe函數被執行時,在/dev目錄下創建對應的文件,例如/dev/sht3x,用戶程序通過讀寫/dev/sht3x文件來操作設備。
同時,也可以在/sys目錄下生成相應的操作文件來操作設備,應用層直接面對用戶,所以接口理應是簡單易用的。
驅動開發者的工作
一般來說,如果只是開發i2c驅動,而不需要為新的芯片移植驅動的話,我們只需要在驅動層做相應的工作,並向應用層提供接口。i2c硬件讀寫層已經集成在系統中。
抽象化仍在進行中
上文中提到,當驅動開發者想要開發驅動時,在驅動層編寫一個driver部分,添加到i2c總線中,同時編寫一個device部分,添加到i2c總線中。
driver部分主要包含了所有的操作接口,而device部分提供相應的資源。
但是,隨着設備的增長,同時由於device部分總是靜態定義在文件中,導致這一部分占用的內核空間越來越大,而且,最主要的問題時,對於資源來說,大多都是一些重復的定義:比如時鍾、定時器、引腳中斷、i2c地址等同類型資源。
按照一貫的風格,對於大量的重復定義,我們必須對其進行抽象化,於是linus一怒之下對其進行大刀闊斧的整改,於是設備樹橫空出世,是的,設備樹就是針對各種總線(i2c bus,platform bus等等)的device資源部分進行整合。
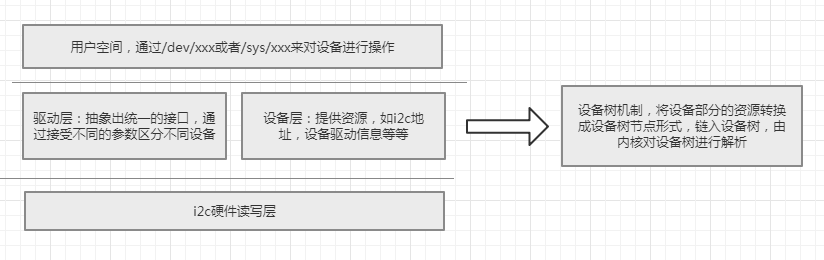
將設備部分的靜態描述轉換成設備樹的形式,由內核在加載時進行解析,這樣節省了大量的空間。
如果有興趣可以看看博主的設備樹解析篇:linux設備樹解析--從dtb格式開始
小結
總的來說,分層即是一種抽象,將重復部分的代碼不斷地提取出來作為一個獨立的模塊,因為模塊之間是調用與被調用的關系,所以看起來就是一種層次結構。
高內聚,低耦合,這是程序設計界的六字箴言。
不管是linux還是其他操作系統,又或者是其他應用程序,將程序模塊化都是一種很好的編程習慣,linux內核的層次結構也是這種思想的產物。
這篇文章只是簡單地分析了linux分層機制的由來,從原理上理解為什么會有這樣的層次結構,事實上,由於linux系統的復雜性,linux的驅動框架並非這么簡單地分成三個部分,博主只是抽去了大部分細節,展現了最粗獷的框架。
接下來,博主還會帶你走進linux內核代碼,剖析整個i2c框架的函數調用流程。
好了,關於linux驅動框架的討論就到此為止啦,如果朋友們對於這個有什么疑問或者發現有文章中有什么錯誤,歡迎留言
原創博客,轉載請注明出處!
祝各位早日實現項目叢中過,bug不沾身.