第10章 Hive實戰之谷粒影音10.1 需求描述10.2 項目10.2.1 數據結構10.2.2 ETL原始數據10.3 准備工作10.3.1 創建表10.3.2 導入ETL后的數據到原始表10.3.3 向ORC表插入數據10.4 業務分析10.4.1 統計視頻觀看數Top1010.4.2 統計視頻類別熱度Top1010.4.3 統計出視頻觀看數最高的20個視頻的所屬視頻類別以及對應視頻類別的個數10.4.4 統計視頻觀看數Top50所關聯視頻的所屬類別rank10.4.5 統計每個類別中的視頻熱度Top10,以Music為例10.4.6 統計每個類別中視頻流量Top10,以Music為例10.4.7 統計上傳視頻最多的用戶Top10以及他們上傳的觀看次數在前20的視頻10.4.8 統計每個類別視頻觀看數Top10第11章 常見錯誤及解決方案
第10章 Hive實戰之谷粒影音
10.1 需求描述
統計硅谷影音視頻網站的常規指標,各種TopN指標:
- 統計視頻觀看數Top10
- 統計視頻類別熱度Top10
- 統計出視頻觀看數最高的20個視頻的所屬視頻類別以及對應視頻類別的個數
- 統計視頻觀看數Top50所關聯視頻的所屬類別Rank
- 統計每個類別中的視頻熱度Top10
- 統計每個類別中視頻流量Top10
- 統計上傳視頻最多的用戶Top10以及他們上傳的視頻
- 統計每個類別視頻觀看數Top10
10.2 項目
10.2.1 數據結構
1、視頻表
| 字段 | 備注 | 詳細描述 |
|---|---|---|
| video id | 視頻唯一id | 11位字符串 |
| uploader | 視頻上傳者 | 上傳視頻的用戶名String |
| age | 視頻年齡 | 視頻在平台上的整數天 |
| category | 視頻類別 | 上傳視頻指定的視頻分類 |
| length | 視頻長度 | 整形數字標識的視頻長度 |
| views | 觀看次數 | 視頻被瀏覽的次數 |
| rate | 視頻評分 | 滿分5分 |
| ratings | 流量 | 視頻的流量,整型數字 |
| conments | 評論數 | 一個視頻的整數評論數 |
| related ids | 相關視頻id | 相關視頻的id,最多20個 |
2、用戶表
| 字段 | 備注 | 字段類型 |
|---|---|---|
| uploader | 上傳者用戶名 | string |
| videos | 上傳視頻數 | int |
| friends | 朋友數量 | int |
10.2.2 ETL原始數據
通過觀察原始數據形式,可以發現,視頻可以有多個所屬分類,每個所屬分類用&符號分割,且分割的兩邊有空格字符,同時相關視頻也是可以有多個元素,多個相關視頻又用“\t”進行分割。為了分析數據時方便對存在多個子元素的數據進行操作,我們首先進行數據重組清洗操作。即:將所有的類別用“&”分割,同時去掉兩邊空格,多個相關視頻id也使用“&”進行分割。
0、添加依賴pom.xml
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
1、ETL之ETLUtil
package com.atguigu;
import org.apache.hadoop.yarn.webapp.hamlet.Hamlet;
/**
* @author chenmingjun
* @date 2019-03-01 15:48
*/
public class ETLUtil {
public static String oriString2ETLString(String ori) {
// 0.切割數據
String[] fields = ori.split("\t");
// 1.過濾臟數據(不符合要求的數據)
if (fields.length < 9) {
return null;
}
// 2.將類別字段中的" " 替換為""(即去掉類別字段中的空格)
fields[3] = fields[3].replace(" ", "");
// 3.替換關聯視頻字段分隔符"\t"替換為"&"
StringBuffer sb = new StringBuffer();
for (int i = 0; i < fields.length; i++) {
// 關聯視頻字段之間的數據
if (i < 9) {
if (i == fields.length -1) {
sb.append(fields[i]);
} else {
sb.append(fields[i] + "\t");
}
} else {
// 關聯視頻字段的數據
if (i == fields.length -1) {
sb.append(fields[i]);
} else {
sb.append(fields[i] + "&");
}
}
}
// 得到的數據格式為:bqZauhidT1w bungloid 592 Film&Animation 28 374550 4.19 3588 1763 QJ5mXzC1YbQ&geEBYTZ4EB8
return sb.toString();
}
}
2、ETL之Mapper
package com.atguigu;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author chenmingjun
* @date 2019-02-28 23:32
*/
public class VideoETLMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1.獲取一行數據
String ori = value.toString();
// 2.清洗數據
String etlString = ETLUtil.oriString2ETLString(ori);
// 3.寫出
if (StringUtils.isBlank(etlString)) {
return;
}
k.set(etlString);
context.write(k, NullWritable.get().get());
}
}
3、ETL之Runner
package com.atguigu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* @author chenmingjun
* @date 2019-03-01 16:55
*/
public class VideoETLRunner implements Tool {
private Configuration conf = null;
public void setConf(Configuration conf) {
this.conf = conf;
}
public Configuration getConf() {
return this.conf;
}
public int run(String[] args) throws Exception {
// 1、獲取配置信息對象以及封裝任務
// Configuration conf = new Configuration();
Job job = Job.getInstance(getConf());
// 2、設置jar的加載路徑
job.setJarByClass(VideoETLRunner.class);
// 3、設置map和reduce類
job.setMapperClass(VideoETLMapper.class);
// job.setReducerClass(WordcountReducer.class);
// 4、設置map輸出的key和value類型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
// 5、設置最終輸出的key和value類型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// 6、設置輸入和輸出路徑
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 因為這里我們不使用Reduce
job.setNumReduceTasks(0);
// 7、提交job
// job.submit();
boolean result = job.waitForCompletion(true);
return result ? 0 : 1;
}
public static void main(String[] args) {
int resultCode = 0;
try {
resultCode = ToolRunner.run(new VideoETLRunner(), args);
if (resultCode == 0) {
System.out.println("Success!");
} else {
System.out.println("Fail!");
}
System.exit(resultCode);
} catch (Exception e) {
e.printStackTrace();
System.exit(1);
}
}
}
4、打好jar包,修改jar包名稱為VideoETL.jar,然后將要清洗的數據和VideoETL.jar從本地上傳至Linux系統上,再將要清洗的數據推送至HDFS集群上。操作如下:
[atguigu@hadoop102 datas]$ hadoop fs -put user/ /guliData/input
[atguigu@hadoop102 datas]$ hadoop fs -put video/ /guliData/input
5、執行ETL
[atguigu@hadoop102 hadoop-2.7.2]$ bin/yarn jar /opt/module/datas/VideoETL.jar com.atguigu.VideoETLRunner /guliData/input/video/2008/0222 /guliData/output/video/2008/0222
10.3 准備工作
10.3.1 創建表
創建原始表:gulivideo_ori,gulivideo_user_ori
創建目標表:gulivideo_orc,gulivideo_user_orc
gulivideo_ori:
create table gulivideo_ori(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
row format delimited
fields terminated by "\t" -- 字段與字段之間的數據按/t分割
collection items terminated by "&" -- 數組中的數據是按&分割
stored as textfile;
gulivideo_user_ori:
create table gulivideo_user_ori(
uploader string,
videos int,
friends int
)
row format delimited
fields terminated by "\t"
stored as textfile;
gulivideo_orc:
create table gulivideo_orc(
videoId string,
uploader string,
age int,
category array<string>,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
clustered by(uploader) into 8 buckets -- 按照字段uploader分成8個桶
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc;
gulivideo_user_orc:
create table gulivideo_user_orc(
uploader string,
videos int,
friends int
)
row format delimited
fields terminated by "\t"
stored as orc;
10.3.2 導入ETL后的數據到原始表
gulivideo_ori:
load data inpath '/guliData/output/video/2008/0222' into table gulivideo_ori;
gulivideo_user_ori:
load data inpath "/guliData/input/user/2008/0903" into table gulivideo_user_ori;
10.3.3 向ORC表插入數據
gulivideo_orc:
insert into table gulivideo_orc select * from gulivideo_ori;
gulivideo_user_orc:
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
10.4 業務分析
10.4.1 統計視頻觀看數Top10
思路:使用order by按照 views 字段做一個全局排序即可,同時我們設置只顯示前10條。為了便於顯示,我們顯示的字段不包含每個視頻對應的關聯視頻字段。
最終代碼:
select
videoId,
uploader,
age,
category,
length,
views,
rate,
ratings,
comments
from
gulivideo_orc
order by
views desc
limit
10;
10.4.2 統計視頻類別熱度Top10
思路:炸開數組【視頻類別】字段,然后按照類別分組,最后按照熱度(視頻個數)排序。
1) 即統計每個類別有多少個視頻,顯示出包含視頻最多的前10個類別。
2) 我們需要按照類別 group by 聚合,然后count組內的videoId個數即可。
3) 因為當前表結構為:一個視頻對應一個或多個類別。所以如果要 group by 類別,需要先將類別進行列轉行(展開),然后再進行count即可。
4) 最后按照熱度排序,顯示前10條。
最終代碼:
第1步:炸裂視頻類別
select
videoId, category_name
from
gulivideo_orc lateral view explode(category) category_t as category_name
limit
100; t1
------------------------------------------------------------------------------------
第2步:統計每種視頻類別下的視頻數
select
category_name, count(*) hot
from
(select
videoId, category_name
from
gulivideo_orc lateral view explode(category) category_t as category_name
limit
100) t1
group by
category_name; t2
------------------------------------------------------------------------------------
第3步:視頻類別熱度Top10
select
category_name, hot
from
(select
category_name, count(*) hot
from
(select
videoId, category_name
from
gulivideo_orc lateral view explode(category) category_t as category_name) t1
group by
category_name) t2
order by
hot desc
limit
10;
+----------------+---------+--+
| category_name | hot |
+----------------+---------+--+
| Music | 179049 |
| Entertainment | 127674 |
| Comedy | 87818 |
| Animation | 73293 |
| Film | 73293 |
| Sports | 67329 |
| Gadgets | 59817 |
| Games | 59817 |
| Blogs | 48890 |
| People | 48890 |
+----------------+---------+--+
注意:第1步和第2步測試先使用100條數據,測試通過后第3步使用全部數據。
10.4.3 統計出視頻觀看數最高的20個視頻的所屬視頻類別以及對應視頻類別的個數
思路:
1) 先找到觀看數最高的20個視頻所屬條目的所有信息,降序排列
2) 把這20條信息中的category分裂出來(列轉行)
3) 最后查詢視頻分類名稱和該分類下有多少個Top20的視頻
最終代碼:
統計出視頻觀看數最高的20個視頻的所屬類別
第1步:統計出視頻觀看數最高的20個視頻
select
*
from
gulivideo_orc
order by
views desc
limit
20; t1
------------------------------------------------------------------------------------
第2步:把這20條信息中的category分裂出來(列轉行)
select
videoId,
category_name
from
(select
*
from
gulivideo_orc
order by
views desc
limit
20) t1 lateral view explode(category) category_t as category_name; t2
+--------------+----------------+--+
| videoid | category_name |
+--------------+----------------+--+
| dMH0bHeiRNg | Comedy |
| 0XxI-hvPRRA | Comedy |
| 1dmVU08zVpA | Entertainment |
| RB-wUgnyGv0 | Entertainment |
| QjA5faZF1A8 | Music |
| -_CSo1gOd48 | People |
| -_CSo1gOd48 | Blogs |
| 49IDp76kjPw | Comedy |
| tYnn51C3X_w | Music |
| pv5zWaTEVkI | Music |
| D2kJZOfq7zk | People |
| D2kJZOfq7zk | Blogs |
| vr3x_RRJdd4 | Entertainment |
| lsO6D1rwrKc | Entertainment |
| 5P6UU6m3cqk | Comedy |
| 8bbTtPL1jRs | Music |
| _BuRwH59oAo | Comedy |
| aRNzWyD7C9o | UNA |
| UMf40daefsI | Music |
| ixsZy2425eY | Entertainment |
| MNxwAU_xAMk | Comedy |
| RUCZJVJ_M8o | Entertainment |
+--------------+----------------+--+
------------------------------------------------------------------------------------
第3步:根據視頻分類名稱進行去重
select
distinct category_name
from
t2;
-------------------------------------------
完整板
select
distinct category_name
from
(select
videoId,
category_name
from
(select
*
from
gulivideo_orc
order by
views desc
limit
20) t1 lateral view explode(category) category_t as category_name) t2;
-------------------------------------------
簡易版
select
distinct category_name
from
(select
*
from
gulivideo_orc
order by
views desc
limit
20) t1 lateral view explode(category) category_t as category_name;
+----------------+--+
| category_name |
+----------------+--+
| Blogs |
| Comedy |
| Entertainment |
| Music |
| People |
| UNA |
+----------------+--+
------------------------------------------------------------------------------------
類別包含Top20視頻的個數
select
category_name,
count(t2.videoId) as hot_with_views
from
(select
videoId,
category_name
from
(select
*
from
gulivideo_orc
order by
views desc
limit
20) t1 lateral view explode(category) category_t as category_name) t2
group by
category_name
order by
hot_with_views desc;
+----------------+-----------------+--+
| category_name | hot_with_views |
+----------------+-----------------+--+
| Entertainment | 6 |
| Comedy | 6 |
| Music | 5 |
| People | 2 |
| Blogs | 2 |
| UNA | 1 |
+----------------+-----------------+--+
10.4.4 統計視頻觀看數Top50所關聯視頻的所屬類別rank
思路分析如下圖所示:
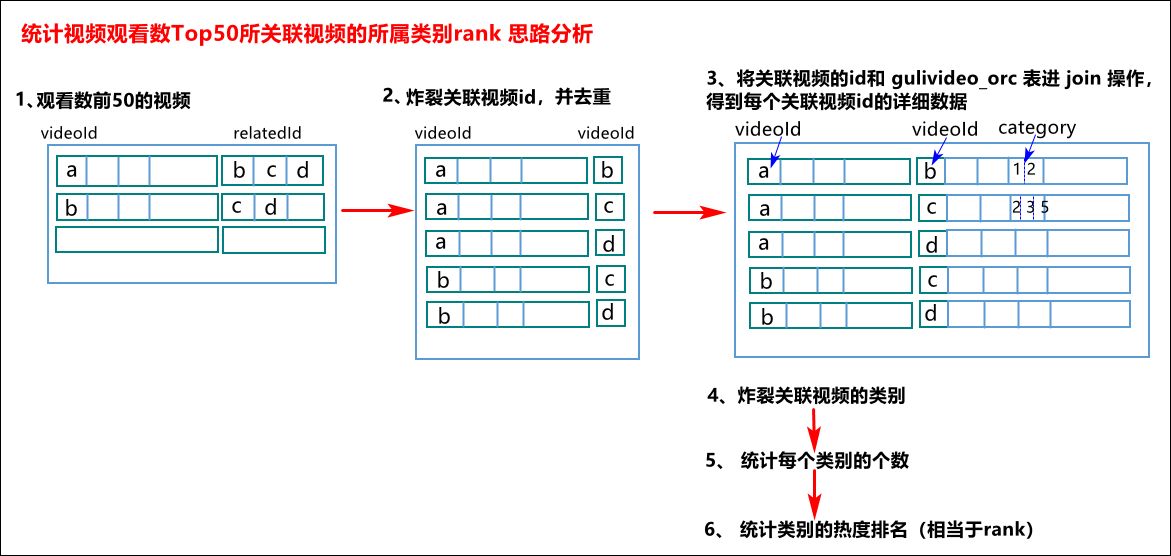
思路:
1) 查詢出觀看數最多的前50個視頻的所有信息(當然
包含了每個視頻對應的關聯視頻),記為臨時表t1
t1:觀看數前50的視頻
select
videoId, views, category, relatedId
from
gulivideo_orc
order by
views desc
limit
50; t1
2) 將找到的50條視頻信息的相關視頻relatedId列轉行,記為臨時表t2
t2:將相關視頻的id進行列轉行操作
炸裂關聯視頻id
select
explode(relatedId) as videoId
from
t1; t2
或者
select
distinct videoId
from
t1 lateral view explode(relatedId) relatedId_t as videoId; t2
3) 將關聯視頻的id和gulivideo_orc表進行inner join操作,得到每個關聯視頻id的詳細數據
select
*
from
t2
inner join
gulivideo_orc t3 on t2.videoId=t3.videoId; t4
4) 炸裂關聯視頻的類別
select
*
from
t4 lateral view explode(category) category_t as category_name; t5
5) 統計類別個數
select
category_name,
count(*) hot
from
t5
group by
category_name; t6
6) 統計類別的熱度排名(即rank)
select
*
from
t6
order by
hot desc;
10.4.5 統計每個類別中的視頻熱度Top10,以Music為例
思路:
1) 要想統計Music類別中的視頻熱度Top10,需要先找到Music類別,那么就需要將category展開,所以可以創建一張表用於存放categoryId展開的數據。
2) 向category展開的表中插入數據。
3) 統計對應類別(Music)中的視頻熱度。
最終代碼:
創建表--類別表:
create table gulivideo_category(
videoId string,
uploader string,
age int,
categoryId string,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc;
向類別表中插入數據:
insert into table
gulivideo_category
select
videoId,
uploader,
age,
categoryId,
length,
views,
rate,
ratings,
comments,
relatedId
from
gulivideo_orc lateral view explode(category) catetory_t as categoryId;
統計Music類別的Top10(也可以統計其他)
select
videoId,
views
from
gulivideo_category
where
categoryId="Music"
order by
views desc
limit
10;
10.4.6 統計每個類別中視頻流量Top10,以Music為例
思路:
1) 創建視頻類別展開表(categoryId列轉行后的表)
2) 按照ratings排序即可
最終代碼:
select
videoId,
views
from
gulivideo_category
where
categoryId="Music"
order by
ratings desc
limit
10;
10.4.7 統計上傳視頻最多的用戶Top10以及他們上傳的觀看次數在前20的視頻
思路:
1) 先找到上傳視頻最多的10個用戶的用戶信息
select
*
from
gulivideo_user_orc
order by
videos desc
limit
10; t1
2) 通過uploader字段與gulivideo_orc表進行join,得到的信息按照views觀看次數進行排序即可。
最終代碼:
select
t2.videoId,
t2.views,
t2.ratings,
t1.videos,
t1.friends
from
t1
join
gulivideo_orc t2
on
t1.uploader=t2.uploader
order by
t2.views desc
limit
20;
10.4.8 統計每個類別視頻觀看數Top10
思路:
1) 先得到categoryId展開的表數據。
2) 子查詢按照categoryId進行分區,然后分區內排序降序,並生成遞增數字,該遞增數字這一列起名為rank列。
3) 通過子查詢產生的臨時表,查詢rank值小於等於10的數據行即可。
最終代碼:
創建表--類別表:
create table gulivideo_category(
videoId string,
uploader string,
age int,
categoryId string,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>
)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc;
向類別表中插入數據:
insert into table
gulivideo_category
select
videoId,
uploader,
age,
categoryId,
length,
views,
rate,
ratings,
comments,
relatedId
from
gulivideo_orc lateral view explode(category) catetory_t as categoryId;
代碼:
第1步:
select
videoId,
categoryId,
views,
row_number() over(partition by categoryId order by views desc) rank
from
gulivideo_category; t1
第2步:
select
t1.*
from
t1
where
rank<=10;
第11章 常見錯誤及解決方案
1)SecureCRT 7.3 出現亂碼或者刪除不掉數據,免安裝版的 SecureCRT 卸載或者用虛擬機直接操作或者換安裝版的SecureCRT。
2)連接不上mysql數據庫
(1)導錯驅動包,應該把 mysql-connector-java-5.1.27-bin.jar 導入 /opt/module/hive/lib 的不是這個包。錯把 mysql-connector-java-5.1.27.tar.gz 導入 hive/lib 包下。
(2)修改user表中的主機名稱沒有都修改為%,而是修改為 localhost。
3)hive默認的輸入格式處理是 CombineHiveInputFormat,會對小文件進行合並。
hive (default)> set hive.input.format;
hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
可以采用 HiveInputFormat 就會根據分區數輸出相應的文件。
hive (default)> set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
4)不能執行mapreduce程序
可能是hadoop的yarn沒開啟。
5)啟動mysql服務時,報 MySQL server PID file could not be found! 異常。
在 /var/lock/subsys/mysql 路徑下創建 hadoop102.pid,並在文件中添加內容:4396
6)報 service mysql status MySQL is not running, but lock file (/var/lock/subsys/mysql[失敗])異常。
解決方案:在/var/lib/mysql 目錄下創建:
-rw-rw----. 1 mysql mysql 5 12月 22 16:41 hadoop102.pid
文件,並修改權限為 777。
7)JVM堆內存溢出

描述:java.lang.OutOfMemoryError: Java heap space
解決:在yarn-site.xml中加入如下代碼后,進行分發,重啟yarn。
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx1024m</value>
</property>