一個請求的生命周期
前言:當我們從電腦上去訪問一個網址時,究竟發生了什么?這個問題可能是自己思考或者面試的時候問到,這里我們以訪問百度首頁為例,進行一個全面的HTTP請求分析。
核心概念
計算機網絡核心結構,就是TCP/IP五層網絡模型(OSI七層模型是將應用層分為了三層)

以及,每一層對應的協議

始於本地
鍵盤輸入:你要訪問www.baidu.com,自然需要在瀏覽器地址欄中使用鍵盤輸入(正常情況下),這個過程就涉及到輸入設備與計算機的交互了,這個屬於物理層,這里就不探討了(==其實是我不會)
請求域名:首先你訪問的是www.baidu.com,並不帶域名,所以瀏覽器會自動補全協議頭。但是我們知道,很多時候域名會有http和https,它倆的默認端口一個是80,一個是443,在這里,一般都是對應域名的網站做了端口轉發,http協議實現了HSTS機制來使得重定向到HTTPS下的域名。所以HTTP到HTTPS這個過程是服務器來完成的,至於瀏覽器的默認端口一直是80端口
路由轉發
IP查找:目前我們只知道了帶協議類型的域名,那么是如何到具體的服務器的呢?我們知道,對於因特網內每個公有地址IP都是唯一的(局域網內不一定),域名相當於IP的別名,因為我們無法去記住一大堆無意義的IP地址,但如果用一堆有意義的字母組成,大家就能快速訪問對應網站。
DNS解析:通過域名去查找IP,先從本地緩存查找,其中本地的hosts文件也綁定了對應IP,若在本機中無法查到,那么就會去請求本地區域的域名服務器(通常是你對應的網絡運營商如移動),這個通過網絡設置中的LDNS去查找,如果還是沒有命中的話,那么就去根域名服務器查找,這里有所有因特網上可訪問的域名和IP對應信息(根域名服務器全球共13台)。至少到了這里,我們肯定能查找對應的IP了,要不就是這個域名不對。
路由轉發:然后我們通過網卡、路由器、交換機等設備,實現兩個IP地址之間的通信。這里用到的主要就是路由轉發技術,根據路由表去轉發報文。。。還有子網掩碼、IP廣播等等知識點。這里就不多做介紹了,計算機網絡里有詳細准確的概念~~
連接建立
三次握手:HTTP的底層基於TCP/IP協議,TCP連接的建立過程少不了三次握手。

第一次握手:客戶端主動發送SYN包到服務器,並進入SYN_SEND狀態,等待服務器確認
第二次握手:服務器收到SYN包並確認,發送SYN+ACK到客戶端,服務器進入SYN_RECV狀態
第三次握手:客戶端收到SYN+ACK包,發送ACK確認連接,發送完畢后客戶端和服務端進入ESTABLISHED狀態,完成三次握手
數據發送:建立完連接后,TCP才能真正的開始傳輸數據==。TCP會依次、有序的發送一定大小的報文,其中包括了超時重傳、擁塞窗口、慢開始快重傳等等概念。總之加了很多機制,用來保證數據包的完整、有序。當然以上都只是傳輸層中TCP做的事,實現上在應用層也加了很多機制。
HTTPS:

大家請看這張圖,一個完整的HTTPS由以上眾多模塊組成。
a. Queueing:請求等待時間
b. Stalled: 從TCP建立連接耗時
c. DNS Lookup:DNS解析
d. Initial connection:初始化連接
e. SSL:SSL就是HTTPS的重頭戲,相比於HTTP建立於TCP基礎上的明文傳輸,HTTPS基於SSL/TLS,而SSL/TLS又是基於TCP/IP,也就是說SSL/TLS基於TCP基礎上再做了一層封裝,對內容進行加密。對HTTPS如何實現加密感興趣的同學可以取看看相關的話題
f. TTFB:客戶端發起報文到服務器接收到第一個報文的耗時
g. Content Download:服務器響應網頁內容接收時間
GOOGLE原文解釋 文檔地址需翻牆
Queueing The browser queues requests when:
1There are higher priority requests.
2There are already six TCP connections open for this origin, which is the limit. Applies to HTTP/1.0 and HTTP/1.1 only.
3The browser is briefly allocating space in the disk cache
Stalled The request could be stalled for any of the reasons described in Queueing.
DNS Lookup The browser is resolving the request’s IP address.
Proxy negotiation The browser is negotiating the request with a proxy server.
Request sent The request is being sent.
ServiceWorker Preparation The browser is starting up the service worker.
Request to ServiceWorker The request is being sent to the service worker.
Waiting (TTFB) The browser is waiting for the first byte of a response. TTFB stands for Time To First Byte. This timing includes 1 round trip of latency and the time the server took to prepare the response.
Content Download The browser is receiving the response.
Receiving Push The browser is receiving data for this response via HTTP/2 Server Push.
Reading Push The browser is reading the local data previously received.
服務器處理
LVS架構:這個請求在到達某一個服務器前,可能還要經歷重重篩選==。反作弊判斷,網關過濾,CDN等等。其中大型網站最常見的是LVS架構。LVS分負載調度器,服務器池,共享存儲。主要就是為了分布式和高並發場景啦。
LVS文檔

代理服務器:接下來,這個請求總算到了服務器了。去監聽它的通常是代理服務器,如Nginx、Apache等。監聽到之后代理服務器會將請求轉發給對應的socket去處理。比如Nginx和PHP的交互就是Nginx將請求轉發給fastcgi_pass定義的socket(文件socket或IPsocket),然后通過fastcgi處理,才會真正將請求和參數丟給server,cgi-app。。。
程序處理
接下來就是代碼去處理具體的邏輯,然后通過response返回啦~~

在前兩篇文章中,我們完整的描述了計算機網絡 OSI 五層模型的相關內容。那么,本篇將會從一個實踐案例開始,帶你從整體上重新認識我們的計算機網絡。 
我們以訪問 Google 為例,當我們在瀏覽器地址欄中敲下回車鍵之后,整個計算機網絡將會發生什么呢?
本機的網絡相關參數如下: 
首先我們應用層的瀏覽器決定向 DNS 服務器請求解析域名「www.google.com」,那么就要遵循 DNS 協議。
DNS 運行在 53 號端口,於是瀏覽器會創建一個 UDP 套接字,標識該套接字的二元組分別是『目的 IP 地址』和『目的端口』。而套接字本質上就是為了唯一標識應用層進程,就是為了讓響應報文能夠找到目的地。
那么這里會創建一個 UDP 套接字,二元組為「本機 IP 地址 192.168.43.138」和「隨機產生一個未使用的端口號」。
接着,瀏覽器將 DNS 請求報文封裝好推入套接字,開始我們的 DNS 解析過程。
有關 DNS 的相關細節,這里不再贅述了,可以參考前面的文章,拿到 DNS 服務器的響應報文,運輸層拆開數據報,得到該報文的目的 IP 地址和目的端口號,於是對應着去找套接字交付報文即可。
最終我們會從『本地 DNS 服務器』得到 Google 的 IP 地址為:172.194.72.105。
整個 HTTP 請求可以說才剛剛開始:
應用層
瀏覽器封裝 HTTP 請求報文,然后創建一個 TCP 套接字,采用四元組標識,具體為「源 IP 地址:192.168.43.138」+「源端口號:隨機的,這里假設為 1234」+「目的 IP 地址:172.194.72.105」+「目的端口號:80」。
HTTP 報文也就是我們的應用層數據報,大致是這樣的: 
指定了一些請求參數與動作,以及一些要求響應報文的返回格式要求,具體的我們不細說了。
緊接着,這個報文會被推進 TCP 套接字中,等待運輸層來收取。
運輸層
運輸層收取了報文,並判斷與目的主機是否建立了 TCP 連接,這里假設沒有。
那么,運輸層將不急着發送應用層數據,得先判斷與目的主機之間能夠正常通訊,也就是需要『握手』打招呼。
『三次握手』的相關細節,我們這里也不再贅述了,上篇文章描述的很詳細了,通過『三次握手』,發送端和接收端確認過發送與確認序號,分配了相應的緩存資源等。
一切准備就緒之后,運輸層將應用層發過來的數據報又一層封裝,添加進『源端口號』和『目的端口號』以及相關差錯檢驗字段。
最后將 TCP 數據報向下傳遞到網絡層。
網絡層
網絡層其實很簡單,拿到數據報並封裝成 IP 數據報,即在原 TCP 報文的前提之上添加『源 IP 地址』和『目的 IP 地址』等字段信息。
然后交由數據鏈路層。
鏈路層
數據鏈路層拿到 IP 數據報,它需要封裝成以太網幀才能在網絡中傳輸,也就是它需要目的主機的 Mac 地址,然而我們只知道目的主機的 IP 地址。
所以,鏈路層有一個 ARP 協議,直接或間接的能夠根據目的 IP 地址獲得使用該 IP 地址的主機 Mac 地址。
當然,ARP 協議運行的前提是,目的 IP 地址和當前發送方主機處於同一子網絡中。如果不然,發送方將目的 Mac 地址填自己網關路由的 Mac 地址,然后通過物理層發送出去。
網關路由由於具有轉發表和路由選擇算法,所以它知道目的網絡該怎么到達,所以一路轉發,最終會發送到目的網絡的網關路由上。
最后,目的網絡的網關路由同樣會經由 ARP 協議,取得目的主機的 Mac 地址,然后廣播發送,最后被目的主機接受。
這樣谷歌的服務器就接受到一個 HTTP 請求,於是它解析這個請求,確定該請求的動作是什么,也就是它需要什么東西,並構建響應報文,以同樣的方式從網絡到達源主機。
最后你將看到你想要的谷歌搜索頁面: 
整體上我們自頂而下的描述了一個請求到達目的地的完整過程,旨在宏觀上建立完整的框架體系,相關細節之處可以參照前兩篇文章。
瀏覽器輸入網址到響應的整個過程-http 請求到響應詳解
這一過程詳細來講涉及到計算機的整個網絡架構系統,從應用層到物理層都可以講述。本講聚焦應用層發生了什么事。
在應用層,瀏覽器首先需要獲得將要訪問的網站的 IP 地址,因此首先需要進行域名解析,從網址提取出域名,然后進行 DNS 請求(UDP)。首先在本機的域名緩存中查詢,若查詢不到再到直連的路由器中查詢,還是沒有則到直連的網絡服務提供商的 DNS 服務器查詢,查詢不到則會有兩種方式繼續查詢一種是遞歸方式,即一級一級的往上一級 DNS 服務器查詢,直到根 DNS 服務器,此時基本能查到;
示例:
主機——>本地 DNS 服務器——>權限 DNS 服務器——>頂級 DNS 服務器——>根服務器。其結果是要么能查到要么報錯。
一種是非遞歸方式,即直接找根 DNS 服務器,然后由它指示要找哪一個根服務器的下一級 DNS 服務器。
當查到需要的 IP 地址后,地址中沒有端口的話則使用 HTTP 協議的默認短號,進行 TCP 的三次握手,與對端主機連接。
成功連接后,則可以向對端主機發送 HTTP 請求,成功收到響應則進行斷連,即 TCP 的四次揮手。若響應是重定向,則需要再一次發送 HTTP 請求到重定向的地址(是否需要重新 DNS 解析?)
最后瀏覽器解析服務器的響應內容,並顯示再瀏覽器頁面。
參考鏈接:
https://blog.csdn.net/lzghxjt/article/details/51458540
https://www.jianshu.com/p/aa97810e5fa4
在瀏覽器中輸入www.baidu.com后執行的全部過程
在瀏覽器中輸入www.baidu.com后執行的全部過程
1、客戶端瀏覽器通過DNS解析到www.baidu.com的IP地址220.181.27.48,通過這個IP地址找到客戶端到服務器的路徑。客戶端瀏覽器發起一個HTTP會話到220.161.27.48,然后通過TCP進行封裝數據包,輸入到網絡層。
2、在客戶端的傳輸層,把HTTP會話請求分成報文段,添加源和目的端口,如服務器使用80端口監聽客戶端的請求,客戶端由系統隨機選擇一個端口如5000,與服務器進行交換,服務器把相應的請求返回給客戶端的5000端口。然后使用IP層的IP地址查找目的端。
3、客戶端的網絡層不用關心應用層或者傳輸層的東西,主要做的是通過查找路由表確定如何到達服務器,期間可能經過多個路由器,這些都是由路由器來完成的工作,我不作過多的描述,無非就是通過查找路由表決定通過那個路徑到達服務器。
4、客戶端的鏈路層,包通過鏈路層發送到路由器,通過鄰居協議查找給定IP地址的MAC地址,然后發送ARP請求查找目的地址,如果得到回應后就可以使用ARP的請求應答交換的IP數據包現在就可以傳輸了,然后發送IP數據包到達服務器的地址。
事件順序
(1) 瀏覽器獲取輸入的域名www.baidu.com
(2) 瀏覽器向DNS請求解析www.baidu.com的IP地址
(3) 域名系統DNS解析出百度服務器的IP地址
(4) 瀏覽器與該服務器建立TCP連接(默認端口號80)
(5) 瀏覽器發出HTTP請求,請求百度首頁
(6) 服務器通過HTTP響應把首頁文件發送給瀏覽器
(7) TCP連接釋放
(8) 瀏覽器將首頁文件進行解析,並將Web頁顯示給用戶。
涉及到的協議
(1) 應用層:HTTP(WWW訪問協議),DNS(域名解析服務)
DNS解析域名為目的IP,通過IP找到服務器路徑,客戶端向服務器發起HTTP會話,然后通過運輸層TCP協議封裝數據包,在TCP協議基礎上進行傳輸
(2) 傳輸層:TCP(為HTTP提供可靠的數據傳輸),UDP(DNS使用UDP傳輸)
HTTP會話會被分成報文段,添加源、目的端口;TCP協議進行主要工作
(3)網絡層:IP(IP數據數據包傳輸和路由選擇),
為數據包選擇路由,IP協議進行主要工作
(4)數據鏈路層:ICMP(提供網絡傳輸過程中的差錯檢測),ARP(將本機的默認網關IP地址映射成物理MAC地址)
相鄰結點的可靠傳輸,ARP協議將IP地址轉成MAC地址。
作為一個軟件開發者,你一定會對網絡應用如何工作有一個完整的層次化的認知,同樣這里也包括這些應用所用到的技術:像瀏覽器,HTTP,HTML,網絡服務器,需求處理等等。
本文將更深入的研究當你輸入一個網址的時候,后台到底發生了一件件什么樣的事~
1. 首先嘛,你得在瀏覽器里輸入要網址:
2. 瀏覽器查找域名的IP地址
導航的第一步是通過訪問的域名找出其IP地址。DNS查找過程如下:
- 瀏覽器緩存 – 瀏覽器會緩存DNS記錄一段時間。 有趣的是,操作系統沒有告訴瀏覽器儲存DNS記錄的時間,這樣不同瀏覽器會儲存個自固定的一個時間(2分鍾到30分鍾不等)。
- 系統緩存 – 如果在瀏覽器緩存里沒有找到需要的記錄,瀏覽器會做一個系統調用(windows里是gethostbyname)。這樣便可獲得系統緩存中的記錄。
- 路由器緩存 – 接着,前面的查詢請求發向路由器,它一般會有自己的DNS緩存。
- ISP DNS 緩存 – 接下來要check的就是ISP緩存DNS的服務器。在這一般都能找到相應的緩存記錄。
- 遞歸搜索 – 你的ISP的DNS服務器從跟域名服務器開始進行遞歸搜索,從.com頂級域名服務器到Facebook的域名服務器。一般DNS服務器的緩存中會有.com域名服務器中的域名,所以到頂級服務器的匹配過程不是那么必要了。
DNS遞歸查找如下圖所示:
DNS有一點令人擔憂,這就是像wikipedia.org 或者 facebook.com這樣的整個域名看上去只是對應一個單獨的IP地址。還好,有幾種方法可以消除這個瓶頸:
- 循環 DNS 是DNS查找時返回多個IP時的解決方案。舉例來說,Facebook.com實際上就對應了四個IP地址。
- 負載平衡器 是以一個特定IP地址進行偵聽並將網絡請求轉發到集群服務器上的硬件設備。 一些大型的站點一般都會使用這種昂貴的高性能負載平衡器。
- 地理 DNS 根據用戶所處的地理位置,通過把域名映射到多個不同的IP地址提高可擴展性。這樣不同的服務器不能夠更新同步狀態,但映射靜態內容的話非常好。
- Anycast 是一個IP地址映射多個物理主機的路由技術。 美中不足,Anycast與TCP協議適應的不是很好,所以很少應用在那些方案中。
大多數DNS服務器使用Anycast來獲得高效低延遲的DNS查找。
3. 瀏覽器給web服務器發送一個HTTP請求
因為像Facebook主頁這樣的動態頁面,打開后在瀏覽器緩存中很快甚至馬上就會過期,毫無疑問他們不能從中讀取。
所以,瀏覽器將把一下請求發送到Facebook所在的服務器:
GET http://facebook.com/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Host: facebook.com Cookie: datr=1265876274-[...]; locale=en_US; lsd=WW[...]; c_user=2101[...]
GET 這個請求定義了要讀取的URL: “http://facebook.com/”。 瀏覽器自身定義 (User-Agent 頭), 和它希望接受什么類型的相應 (Accept and Accept-Encoding頭). Connection頭要求服務器為了后邊的請求不要關閉TCP連接。
請求中也包含瀏覽器存儲的該域名的cookies。可能你已經知道,在不同頁面請求當中,cookies是與跟蹤一個網站狀態相匹配的鍵值。這樣cookies會存儲登錄用戶名,服務器分配的密碼和一些用戶設置等。Cookies會以文本文檔形式存儲在客戶機里,每次請求時發送給服務器。
用來看原始HTTP請求及其相應的工具很多。作者比較喜歡使用fiddler,當然也有像FireBug這樣其他的工具。這些軟件在網站優化時會幫上很大忙。
除了獲取請求,還有一種是發送請求,它常在提交表單用到。發送請求通過URL傳遞其參數(e.g.: http://robozzle.com/puzzle.aspx?id=85)。發送請求在請求正文頭之后發送其參數。
像“http://facebook.com/”中的斜杠是至關重要的。這種情況下,瀏覽器能安全的添加斜杠。而像“http: //example.com/folderOrFile”這樣的地址,因為瀏覽器不清楚folderOrFile到底是文件夾還是文件,所以不能自動添加 斜杠。這時,瀏覽器就不加斜杠直接訪問地址,服務器會響應一個重定向,結果造成一次不必要的握手。
4. facebook服務的永久重定向響應
圖中所示為Facebook服務器發回給瀏覽器的響應:
HTTP/1.1 301 Moved Permanently Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT Location: http://www.facebook.com/ P3P: CP="DSP LAW" Pragma: no-cache Set-Cookie: made_write_conn=deleted; expires=Thu, 12-Feb-2009 05:09:50 GMT; path=/; domain=.facebook.com; httponly Content-Type: text/html; charset=utf-8 X-Cnection: close Date: Fri, 12 Feb 2010 05:09:51 GMT Content-Length: 0
服務器給瀏覽器響應一個301永久重定向響應,這樣瀏覽器就會訪問“http://www.facebook.com/” 而非“http://facebook.com/”。
為什么服務器一定要重定向而不是直接發會用戶想看的網頁內容呢?這個問題有好多有意思的答案。
其中一個原因跟搜索引擎排名有 關。你看,如果一個頁面有兩個地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎會認為它們是兩個網站,結果造成每一個的搜索鏈接都減少從而降低排名。而搜索引擎知道301永久重定向是 什么意思,這樣就會把訪問帶www的和不帶www的地址歸到同一個網站排名下。
還有一個是用不同的地址會造成緩存友好性變差。當一個頁面有好幾個名字時,它可能會在緩存里出現好幾次。
5. 瀏覽器跟蹤重定向地址
現在,瀏覽器知道了“http://www.facebook.com/”才是要訪問的正確地址,所以它會發送另一個獲取請求:
GET http://www.facebook.com/ HTTP/1.1 Accept: application/x-ms-application, image/jpeg, application/xaml+xml, [...] Accept-Language: en-US User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; [...] Accept-Encoding: gzip, deflate Connection: Keep-Alive Cookie: lsd=XW[...]; c_user=21[...]; x-referer=[...] Host: www.facebook.com
頭信息以之前請求中的意義相同。
6. 服務器“處理”請求
服務器接收到獲取請求,然后處理並返回一個響應。
這表面上看起來是一個順向的任務,但其實這中間發生了很多有意思的東西- 就像作者博客這樣簡單的網站,何況像facebook那樣訪問量大的網站呢!
- Web 服務器軟件
web服務器軟件(像IIS和阿帕奇)接收到HTTP請求,然后確定執行什么請求處理來處理它。請求處理就是一個能夠讀懂請求並且能生成HTML來進行響應的程序(像ASP.NET,PHP,RUBY...)。舉 個最簡單的例子,需求處理可以以映射網站地址結構的文件層次存儲。像http://example.com/folder1/page1.aspx這個地 址會映射/httpdocs/folder1/page1.aspx這個文件。web服務器軟件可以設置成為地址人工的對應請求處理,這樣 page1.aspx的發布地址就可以是http://example.com/folder1/page1。
- 請求處理
請求處理閱讀請求及它的參數和cookies。它會讀取也可能更新一些數據,並講數據存儲在服務器上。然后,需求處理會生成一個HTML響應。
所 有動態網站都面臨一個有意思的難點 -如何存儲數據。小網站一半都會有一個SQL數據庫來存儲數據,存儲大量數據和/或訪問量大的網站不得不找一些辦法把數據庫分配到多台機器上。解決方案 有:sharding (基於主鍵值講數據表分散到多個數據庫中),復制,利用弱語義一致性的簡化數據庫。
委 托工作給批處理是一個廉價保持數據更新的技術。舉例來講,Fackbook得及時更新新聞feed,但數據支持下的“你可能認識的人”功能只需要每晚更新 (作者猜測是這樣的,改功能如何完善不得而知)。批處理作業更新會導致一些不太重要的數據陳舊,但能使數據更新耕作更快更簡潔。
7. 服務器發回一個HTML響應
圖中為服務器生成並返回的響應:
HTTP/1.1 200 OK Cache-Control: private, no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Expires: Sat, 01 Jan 2000 00:00:00 GMT P3P: CP="DSP LAW" Pragma: no-cache Content-Encoding: gzip Content-Type: text/html; charset=utf-8 X-Cnection: close Transfer-Encoding: chunked Date: Fri, 12 Feb 2010 09:05:55 GMT 2b3Tn@[...]
整個響應大小為35kB,其中大部分在整理后以blob類型傳輸。
內容編碼頭告訴瀏覽器整個響應體用gzip算法進行壓縮。解壓blob塊后,你可以看到如下期望的HTML:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en" id="facebook" class=" no_js"> <head> <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> <meta http-equiv="Content-language" content="en" /> ...
關於壓縮,頭信息說明了是否緩存這個頁面,如果緩存的話如何去做,有什么cookies要去設置(前面這個響應里沒有這點)和隱私信息等等。
請注意報頭中把Content-type設置為“text/html”。報頭讓瀏覽器將該響應內容以HTML形式呈現,而不是以文件形式下載它。瀏覽器會根據報頭信息決定如何解釋該響應,不過同時也會考慮像URL擴展內容等其他因素。
8. 瀏覽器開始顯示HTML
在瀏覽器沒有完整接受全部HTML文檔時,它就已經開始顯示這個頁面了:
9. 瀏覽器發送獲取嵌入在HTML中的對象
在瀏覽器顯示HTML時,它會注意到需要獲取其他地址內容的標簽。這時,瀏覽器會發送一個獲取請求來重新獲得這些文件。
下面是幾個我們訪問facebook.com時需要重獲取的幾個URL:
- 圖片
http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
http://static.ak.fbcdn.net/rsrc.php/zBS5C/hash/7hwy7at6.gif
… - CSS 式樣表
http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
http://static.ak.fbcdn.net/rsrc.php/zANE1/hash/cvtutcee.css
… - JavaScript 文件
http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
http://static.ak.fbcdn.net/rsrc.php/z6R9L/hash/cq2lgbs8.js
…
這些地址都要經歷一個和HTML讀取類似的過程。所以瀏覽器會在DNS中查找這些域名,發送請求,重定向等等...
但 不像動態頁面那樣,靜態文件會允許瀏覽器對其進行緩存。有的文件可能會不需要與服務器通訊,而從緩存中直接讀取。服務器的響應中包含了靜態文件保存的期限 信息,所以瀏覽器知道要把它們緩存多長時間。還有,每個響應都可能包含像版本號一樣工作的ETag頭(被請求變量的實體值),如果瀏覽器觀察到文件的版本 ETag信息已經存在,就馬上停止這個文件的傳輸。
試着猜猜看“fbcdn.net”在地址中代表什么?聰明的答案是"Facebook內容分發網絡"。Facebook利用內容分發網絡(CDN)分發像圖片,CSS表和JavaScript文件這些靜態文件。所以,這些文件會在全球很多CDN的數據中心中留下備份。
靜態內容往往代表站點的帶寬大小,也能通過CDN輕松的復制。通常網站會使用第三方的CDN。例如,Facebook的靜態文件由最大的CDN提供商Akamai來托管。
舉例來講,當你試着ping static.ak.fbcdn.net的時候,可能會從某個akamai.net服務器上獲得響應。有意思的是,當你同樣再ping一次的時候,響應的服務器可能就不一樣,這說明幕后的負載平衡開始起作用了。
10. 瀏覽器發送異步(AJAX)請求
在Web 2.0偉大精神的指引下,頁面顯示完成后客戶端仍與服務器端保持着聯系。
以 Facebook聊天功能為例,它會持續與服務器保持聯系來及時更新你那些亮亮灰灰的好友狀態。為了更新這些頭像亮着的好友狀態,在瀏覽器中執行的 JavaScript代碼會給服務器發送異步請求。這個異步請求發送給特定的地址,它是一個按照程式構造的獲取或發送請求。還是在Facebook這個例 子中,客戶端發送給http://www.facebook.com/ajax/chat/buddy_list.php一個發布請求來獲取你好友里哪個 在線的狀態信息。
提起這個模式,就必須要講講"AJAX"-- “異步JavaScript 和 XML”,雖然服務器為什么用XML格式來進行響應也沒有個一清二白的原因。再舉個例子吧,對於異步請求,Facebook會返回一些JavaScript的代碼片段。
除了其他,fiddler這個工具能夠讓你看到瀏覽器發送的異步請求。事實上,你不僅可以被動的做為這些請求的看客,還能主動出擊修改和重新發送它們。AJAX請求這么容易被蒙,可着實讓那些計分的在線游戲開發者們郁悶的了。(當然,可別那樣騙人家~)
Facebook聊天功能提供了關於AJAX一個有意思的問題案例:把數據從服務器端推送到客戶端。因為HTTP是一個請求-響應協議,所以聊天服務器不能把新消息發給客戶。取而代之的是客戶端不得不隔幾秒就輪詢下服務器端看自己有沒有新消息。
這些情況發生時長輪詢是個減輕服務器負載挺有趣的技術。如果當被輪詢時服務器沒有新消息,它就不理這個客戶端。而當尚未超時的情況下收到了該客戶的新消息,服務器就會找到未完成的請求,把新消息做為響應返回給客戶端。
基於Web的HTTP請求/響應生命周期的關鍵點
路由
建立一個復雜將URL映射到函數的路由器。
函數執行
函數應該通過異步的方式執行,一旦函數執行完成,就應該執行一個回調函數。
響應/渲染
一旦執行完成,就應該通過異步的方式執行渲染。
序列化
在執行、渲染階段獲取和使用過的所有數據都應該成為服務器端響應的一部分。
反序列化
任何對象和數據都需要在客戶端重新創建,因為當用戶和應用進行交互時,客戶端運行時需要用到這些數據。
添加事件
應綁定事件處理器,以便應用可交互。
#目錄
##1、基本概念
* 什么是CGI?
* 部分專業術語解釋
* 圖解靜態請求和動態請求
* php組成
##2、PHP的生命周期
##3、PHP底層工作原理
###基本概念
####1.什么是CGI?
1)什么是cgi呢?
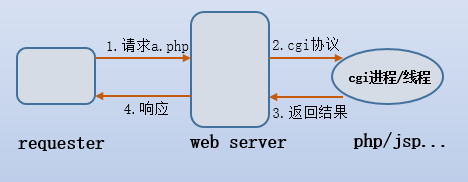
CGI是common gateway interface的縮寫,譯作通用網關接口,但很不幸,我們無法見名知意,我們知道,web服務器所處理的內容都是靜態的,要想處理動態內容,需要依賴於web應用程序,如php、jsp、python、perl等。但是web server如何將動態的請求傳遞給這些應用程序?它所依賴的就是cgi協議。沒錯,是協議,也就是web server和web應用程序交流時的規范。換句話說,通過cgi協議,再結合已搭建好的web應用程序,就可以讓web server也能"處理"動態請求,你肯定知道處理兩字為什么要加上雙引號。
簡單版的cgi工作方式如下:
***
####2.部分專業術語解釋
#####CGI:
**概念**:它是一種協議。通過cgi協議,web server可以將動態請求和相關參數發送給專門處理動態內容的應用程序。
**工作原理**:CGI方式在遇到連接請求(用戶請求)先要創建cgi的子進程,激活一個CGI進程,然后處理請求,處理完后結束這個子進程。這就是fork-and-execute模式。所以用cgi方式的服務器有多少連接請求就會有多少cgi子進程,子進程反復加載是cgi性能低下的主要原因。當用戶請求數量非常多時,會大量擠占系統的資源如內存,CPU時間等,造成效能低下。
***
#####2)FASTCGI:
**概念**:也是一種協議,只不過是cgi的優化版。cgi的性能較爛,fastcgi則在其基礎上進行了改進。FastCGI技術目前支持語言有:C/C++、Java、Perl、Tcl、Python、SmallTalk、Ruby等
**工作原理**:fast-cgi是cgi的升級版本,是一個進程可以處理多個請求,和上面的cgi協議完全不一樣,cgi是一個進程只能處理一個請求,這樣就會導致大量的cgi程序,因此會給服務器帶來負擔。FastCGI像是一個常駐型的CGI,它可以一直執行着,只要激活后,不會每次都要花費時間去fork一次
***
#####3)PHP-CGI:
**概念**:PHP-CGI是PHP自帶的FastCGI管理器。
**工作原理**:fastcgi是一種協議,而php-cgi實現了這種協議。不過這種實現比較爛。它是單進程的,一個進程處理一個請求,處理結束后進程就銷毀。
#####4)PHP-FPM:
**概念**:PHP-FPM是一個PHP FastCGI管理器,是只用於PHP的是對php-cgi的改進版,它直接管理多個php-cgi進程/線程。也就是說,php-fpm是php-cgi的進程管理器因此它也算是fastcgi協議的實現。
**工作原理**:php-fpm會開啟多個php-cgi程序,並且php-fpm常駐內存,每次web serve服務器發送連接過來的時候,php-fpm將連接信息分配給下面其中的一個子程序php-cgi進行處理,處理完畢這個php-cgi並不會關閉,而是繼續等待下一個連接(一個進程至少服務上萬次請求才退出),這也是fast-cgi加速的原理,但是由於php-fpm是多進程的,而一個php-cgi基本消耗7-25M內存,因此如果連接過多就會導致內存消耗過大,引發一些問題,例如nginx里的502錯誤。
**為什么一定要退出?**因為擔心RINIT->RSHUTDOWN循環,有哪個代碼寫的不好,變量一直沒釋放,內存泄露GC又回收不了。php-fpm里的pm.max_requests配置就是設置RINT循環多少次,退出進程。
**同時php-fpm還附帶一些其他的功能**:例如平滑過渡配置更改,普通的php-cgi在每次更改配置后,需要重新啟動才能初始化新的配置,而php-fpm是不需要,php-fpm分將新的連接發送給新的子程序php-cgi,這個時候加載的是新的配置,而原先**正在運行**的php-cgi還是使用的原先的配置,等到**這個連接后下一次連接**的時候會使用新的配置初始化,這就是**平滑過渡**。
***
#####5)CGI進程/線程
**概念**:在php上,就是php-cgi進程/線程。專門用於接收web server的動態請求,**調用並初始化zend虛擬機。**
***
#####6)CGI腳本:
**概念**:被執行的php源代碼文件。
***
#####7)ZEND虛擬機:
**概念**:對php文件做詞法分析、語法分析、編譯成opcode,並執行。最后關閉zend虛擬機。
**CGI進程/線程和ZEND虛擬機的關系**:cgi進程調用並初始化zend虛擬機的各種環境。
***
#####8)常見的SAPI
SAPI提供了一個和外部通信的接口,常見的SAPI有:cgi 、fast-cgi、cli、isapi、apache 模塊的 DLL
***
####3.圖解靜態請求和動態請求

***

###4.PHP的組成
**PHP總共有三個模塊:內核、Zend引擎、以及擴展層。**
**PHP內核**用來處理請求、文件流、錯誤處理等相關操作。
**Zend引擎**用以將源文件轉換成機器語言,然后在虛擬機上運行它。
**擴展層**是一組函數、類庫和流,PHP使用它們來執行一些特定的操作。
比如,我們需要mysql擴展來連接MySQL數據庫; 當ZE執行程序時可能會需要連接若干擴展,這時ZE將控制權交給擴展,等處理完特定任務后再返還;最后,ZE將程序運行結果返回給PHP內核,它再將結果傳送給SAPI層,最終輸出到瀏覽器上。
####5、WEB-SERVER和PHP-CGI的交互模式
web server和php-cgi有3種交互模式。
* **cgi模式**:httpd接收到一個動態請求就fork一個cgi進程,cgi進程返回結果給httpd進程后自我銷毀。
* **動態模塊模式**:將php-cgi的模塊編譯進httpd(Apache的方法)。在httpd啟動時會加載模塊,加載時也將對應的模塊激活,php-cgi也就啟動了。(注:糾正一個小小錯誤,很多人以為動態編譯的模塊是可以在需要的時候隨時加載調用,不需要的時候它們就停止了,實際上不是這樣的。和靜態編譯的模塊一樣,動態加載的模塊在被加載時就被加入到激活鏈表中,無論是否使用它,它都已經運行在apache httpd的內部)
* **php-fpm模式**:使用php-fpm管理php-cgi,此時httpd不再控制php-cgi進程的啟動。可以將php-fpm獨立運行在非web服務器上,實現所謂的動靜分離。
實際上,借助模塊mod_fastcgi還可以實現fastcgi模式。同cgi一樣,管理模式的先天缺陷決定了這並不是一種好方法。
###
###2、PHP的生命周期
####流程圖解:

####PHP開始和結束階段:

由上面的圖,我們能知道,SAPI運行PHP都經過下面幾個階段
* 模塊初始化階段(Module init):即調用每個拓展源碼中的的PHP\_MINIT\_FUNCTION中的方法初始化模塊,進行一些模塊所需變量的申請,內存分配等。
* 請求初始化階段(Request init):即接受到客戶端的請求后調用每個拓展的PHP\_RINIT\_FUNCTION中的方法,初始化PHP腳本的執行環境。
* 執行PHP腳本
* 請求結束(Request Shutdown):這時候調用每個拓展的PHP\_RSHUTDOWN\_FUNCTION方法清理請求現場,並且ZE開始回收變量和內存。
* 關閉模塊(Module shutdown): Web服務器退出或者命令行腳本執行完畢退出會調用拓展源碼中的PHP\_MSHUTDOWN\_FUNCTION 方法。
####我們具體來看看每一步都做了什么?
1)**模塊初始化階段**:
在整個SAPI生命周期內(例如Apache啟動以后的整個生命周期內或者命令行程序整個執行過程中), 該過程只進行一次,第一步的操作在任何請求到達之前就發生了。
PHP調用各個擴展的MINIT方法,從而使這些擴展切換到可用狀態。我們可以看看php.ini文件里打開了哪些擴展,這些擴展會在這個階段進行”模塊初始化“。 MINIT的意思是“模塊初始化”。各個模塊都定義了一組函數、類庫等用以處理其他請求。
2) **請求初始化**:
當一個頁面請求發生時,SAPI層將控制權交給PHP層。於是PHP設置了用於回復本次請求所需的環境變量。同時,它還建立一個變量表,用來存放執行過程 中產生的變量名和值。PHP調用各個模塊的RINIT方法,即“請求初始化”。一個經典的例子是Session模塊的RINIT,如果在php.ini中 啟用了Session模塊,那在調用該模塊的RINIT時就會初始化$_SESSION變量,並將相關內容讀入;RINIT方法可以看作是一個准備過程, 在程序執行之間就會自動啟動。
3)**執行腳本**
一旦請求被初始化了,ZE開始接管控制權,將PHP腳本翻譯成符號(OPcode),最終形成操作碼並逐步運行之。如任一操作碼需要調用擴展的函數,ZE將會把參數綁定到該函數,並且臨時交出控制權直到函數運行結束。
1. scanner
將PHP代碼轉換為Tokens,詳見代碼Zend/zend\_language\_scanner.l。
2. parser
將Tokens轉換成表達式,詳見代碼Zend/zend\_language\_parser.y。
3. compile
將表達式編譯成opcode。opcode存放在op\_array中。
4. execute
Zend Engine調用zend\_execute來執行op\_array,輸出結果。
4)**關閉第一步(請求關閉)**
如同PHP啟動一樣,PHP的關閉也分兩步。一旦頁面執行完畢(無論是執行到了文件末尾還是用exit或die函數中止),PHP就會啟動清理程序。它會按順序調用各個模塊的RSHUTDOWN方法。 RSHUTDOWN用以清除程序運行時產生的符號表,也就是對每個變量調用unset函數。
5)**關閉第二步(模塊關閉)**
所有的請求都已處理完畢,SAPI也准備關閉了,PHP開始執行第二步:PHP調用每個擴展的MSHUTDOWN方法,這是各個模塊最后一次釋放內存的機會。
**這樣,整個PHP生命周期就結束了。要注意的是,只有在服務器沒有請求的情況下才會執行“啟動第一步”和“關閉第二步”。**
###3、PHP底層工作原理
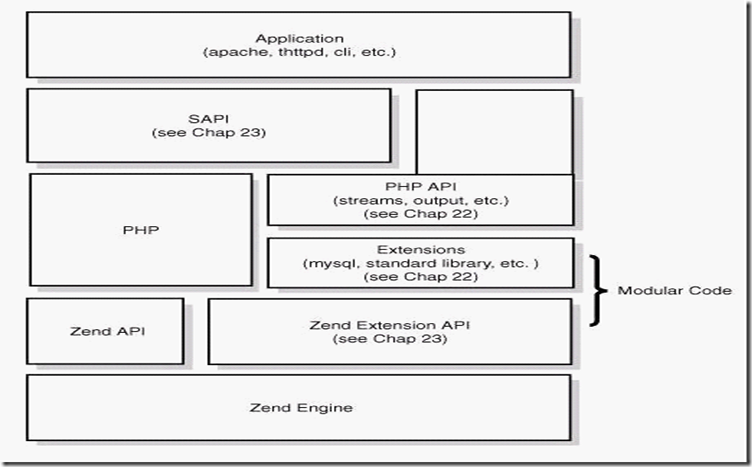
**從圖上可以看出,php從下到上是一個4層體系**
**①Zend引擎**
Zend整體用純c實現,是php的內核部分,它將php代碼翻譯(詞法、語法解析等一系列編譯過程)為可執行opcode的處理並實現相應的處理方法、實現了基本的數據結構(如hashtable、oo)、內存分配及管理、提供了相應的api方法供外部調用,是一切的核心,所有的外圍功能均圍繞zend實現。
**②Extensions**
圍繞着zend引擎,extensions通過組件式的方式提供各種基礎服務,我們常見的各種內置函數(如array系列)、標准庫等都是通過extension來實現,用戶也可以根據需要實現自己的extension以達到功能擴展、性能優化等目的(如貼吧正在使用的php中間層、富文本解析就是extension的典型應用)。
**③Sapi**
Sapi全稱是Server Application Programming Interface,也就是服務端應用編程接口,sapi通過一系列鈎子函數,使得php可以和外圍交互數據,這是php非常優雅和成功的一個設計,通過sapi成功的將php本身和上層應用解耦隔離,php可以不再考慮如何針對不同應用進行兼容,而應用本身也可以針對自己的特點實現不同的處理方式。后面將在sapi章節中介紹
**④上層應用**
這就是我們平時編寫的php程序,通過不同的sapi方式得到各種各樣的應用模式,如通過webserver實現web應用、在命令行下以腳本方式運行等等。
**構架思想:**
引擎(Zend)+組件(ext)的模式降低內部耦合
中間層(sapi)隔絕web server和php