寫在前面
准備近期將微軟的machinelearning-samples翻譯成中文,水平有限,如有錯漏,請大家多多指正。
如果有朋友對此感興趣,可以加入我:https://github.com/feiyun0112/machinelearning-samples.zh-cn
圖像分類 - 評分示例
問題
圖像分類是許多業務場景中的常見情況。 對於這些情況,您可以使用預先訓練的模型或訓練自己的模型來對特定於自定義域的圖像進行分類。
數據集
有兩個數據源:tsv文件和圖像文件。tsv 文件 包含2列:第一個定義為ImagePath,第二個定義為對應於圖像的Label。正如你所看到的,文件沒有標題行,看起來像這樣:
broccoli.jpg broccoli
broccoli.png broccoli
canoe2.jpg canoe
canoe3.jpg canoe
canoe4.jpg canoe
coffeepot.jpg coffeepot
coffeepot2.jpg coffeepot
coffeepot3.jpg coffeepot
coffeepot4.jpg coffeepot
pizza.jpg pizza
pizza2.jpg pizza
pizza3.jpg pizza
teddy1.jpg teddy bear
teddy2.jpg teddy bear
teddy3.jpg teddy bear
teddy4.jpg teddy bear
teddy6.jpg teddy bear
toaster.jpg toaster
toaster2.png toaster
toaster3.jpg toaster
訓練和測試圖像位於assets文件夾中。這些圖像屬於維基共享資源。
維基共享資源, 免費媒體存儲庫。 於 10:48, October 17, 2018 檢索自:
https://commons.wikimedia.org/wiki/Pizza
https://commons.wikimedia.org/wiki/Coffee_pot
https://commons.wikimedia.org/wiki/Toaster
https://commons.wikimedia.org/wiki/Category:Canoes
https://commons.wikimedia.org/wiki/Teddy_bear
預訓練模型
有多個模型被預先訓練用於圖像分類。在本例中,我們將使用基於Inception拓撲的模型,並用來自Image.Net的圖像進行訓練。這個模型可以從 https://storage.googleapis.com/download.tensorflow.org/models/inception5h.zip 下載, 也可以在 / src / ImageClassification / assets /inputs / inception / tensorflow_inception_graph.pb 找到。
解決方案
控制台應用程序項目ImageClassification.Score可用於基於預先訓練的Inception-v3 TensorFlow模型對樣本圖像進行分類。
再次注意,此示例僅使用預先訓練的TensorFlow模型和ML.NET API。 因此,它不會訓練任何ML.NET模型。 目前,在ML.NET中僅支持使用現有的TensorFlow訓練模型進行評分/預測。
您需要按照以下步驟執行分類測試:
- 設置VS默認啟動項目: 將
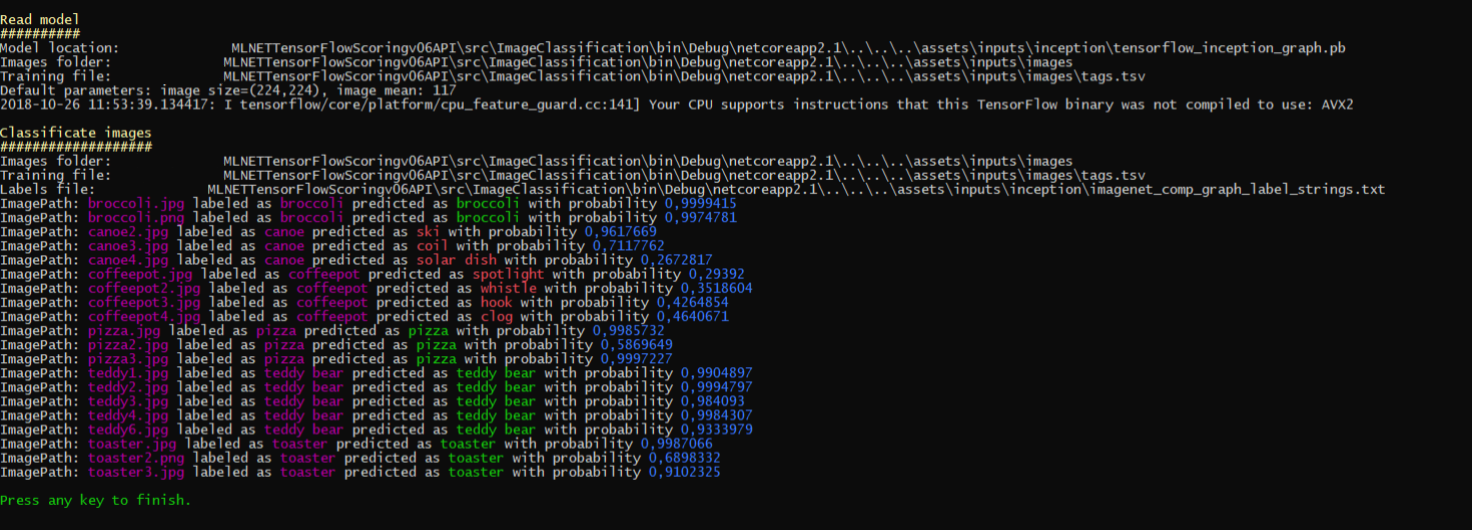
ImageClassification.Score設置為Visual Studio中的啟動項目。 - 運行訓練模型控制台應用程序: 在Visual Studio中按F5。 在執行結束時,輸出將類似於此屏幕截圖:
代碼演練
解決方案中有一個名為ImageClassification.Score的項目,它負責以TensorFlow格式加載模型,然后對圖像進行分類。
ML.NET:模型評分
TextLoader.CreateReader()用於定義將用於在ML.NET模型中加載圖像的文本文件的模式。
var loader = new TextLoader(env,
new TextLoader.Arguments
{
Column = new[] {
new TextLoader.Column("ImagePath", DataKind.Text, 0)
}
});
var data = loader.Read(new MultiFileSource(dataLocation));
用於加載圖像的圖像文件有兩列:第一列定義為ImagePath ,第二列是與圖像對應的Label。
需要強調的是,在使用TensorFlow模型進行評分時,這里並沒有真正使用標簽。該文件僅作為測試預測時的參考,以便您可以將每個樣本數據的實際標簽與TensorFlow模型提供的預測標簽進行比較。這就是為什么當使用上面的'TextLoader'加載文件時,您只需要獲取ImagePath或文件的名稱,但不需要獲取標簽。
broccoli.jpg broccoli
bucket.png bucket
canoe.jpg canoe
snail.jpg snail
teddy1.jpg teddy bear
正如您所看到的,文件沒有標題行。
第二步是定義估計器流水線。通常,在處理深度神經網絡時,必須使圖像適應網絡期望的格式。這就是為什么圖像被調整大小然后被轉換的原因(主要是,像素值在所有R、G、B通道上被標准化)。
var pipeline = new ImageLoaderEstimator(env, imagesFolder, ("ImagePath", "ImageReal"))
.Append(new ImageResizerEstimator(env, "ImageReal", "ImageReal", ImageNetSettings.imageHeight, ImageNetSettings.imageWidth))
.Append(new ImagePixelExtractorEstimator(env, new[] { new ImagePixelExtractorTransform.ColumnInfo("ImageReal", "input", interleave: ImageNetSettings.channelsLast, offset: ImageNetSettings.mean) }))
.Append(new TensorFlowEstimator(env, modelLocation, new[] { "input" }, new[] { "softmax2" }));
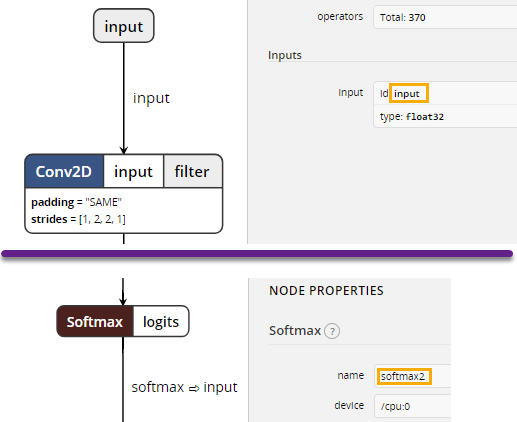
您還需要檢查神經網絡,並檢查輸入/輸出節點的名稱。為了檢查模型,可以使用Netron,它會隨Visual Studio Tools for AI一起安裝。
這些名稱稍后在評估器管道的定義中使用:在初始網絡的情況下,輸入張量被命名為“input”,輸出被命名為“softmax2”。
最后,我們在擬合評估器管道之后提取預測函數。 預測函數接收類型為ImageNetData的對象(包含2個屬性:ImagePath和Label)作為參數,然后返回類型為ImagePrediction的對象。
var modeld = pipeline.Fit(data);
var predictionFunction = modeld.MakePredictionFunction<ImageNetData, ImageNetPrediction>(env);
在獲得預測時,我們得到屬性PredictedLabels中的浮點數數組。數組中的每個位置都被分配給一個標簽,例如,如果模型有5個不同的標簽,那么數組長度將等於5。數組中的每個位置的值表示標簽在該位置上的概率;所有數組值(概率)的總和等於1。然后,您需要選擇最大值(概率)並檢查指定給該位置的標簽。
引用
訓練和預測圖像
維基共享資源, 免費媒體存儲庫。 於 10:48, October 17, 2018 檢索自 https://commons.wikimedia.org/w/index.php?title=Main_Page&oldid=313158208.