問題描述
- 應用收到頻繁Full GC告警
問題排查
- 登錄到對應機器上去,查看GC日志,發現YGC一分鍾已經達到了15次,比Full GC還要頻繁一些,其中Full GC平均10分鍾超過了4次,如下圖
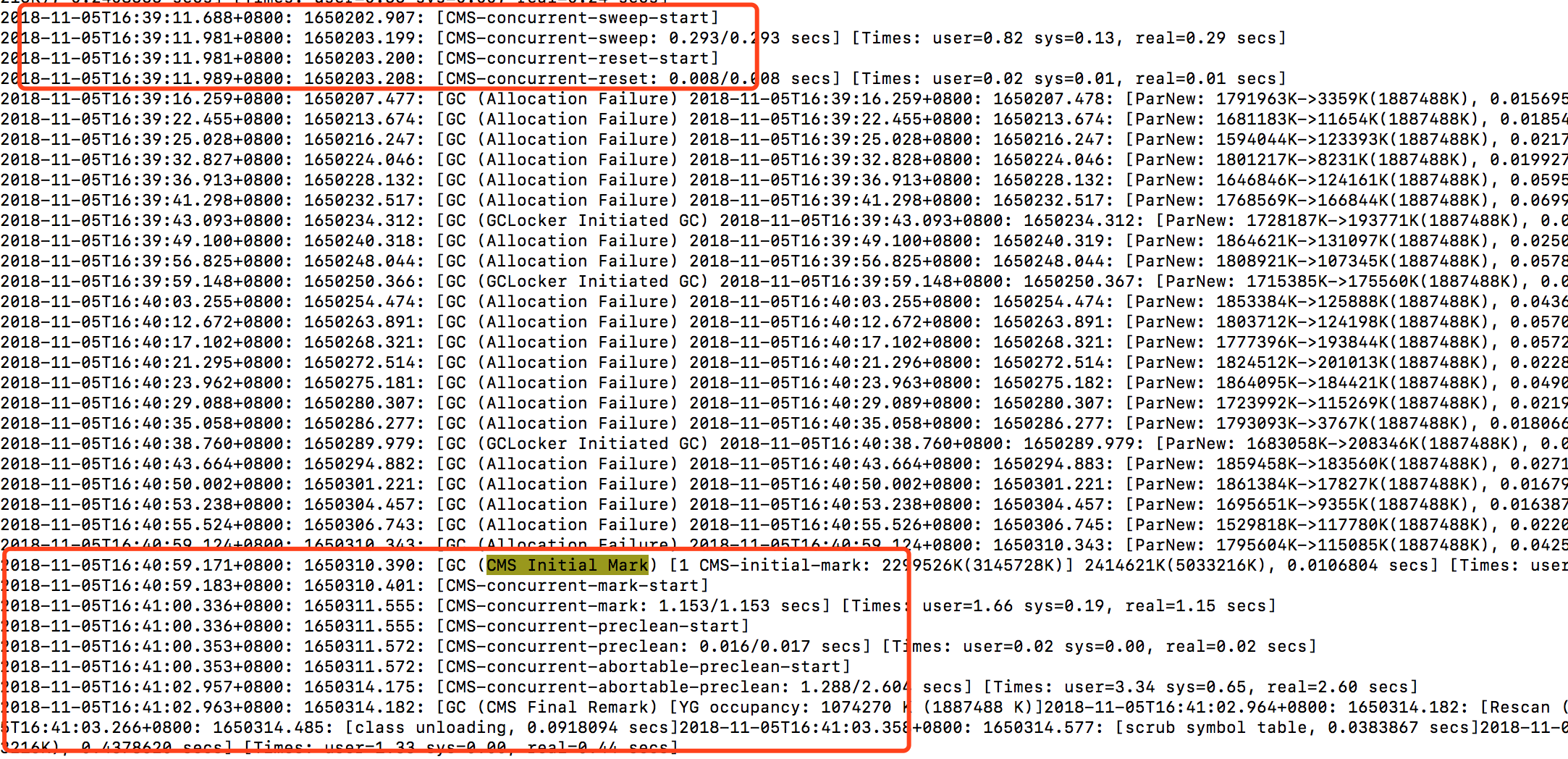
- 使用jstat -gcutil 5280 1000查看實時GC情況,年老代采用的是CMS收集器,發現觸發Full GC的原因是年老代占用空間達到指定閾值70%(-XX:CMSInitiatingOccupancyFraction=70)。
- 這時候猜測是某個地方頻繁創建對象導致,通過
jmap -dump:format=b,file=temp.dump 5280dump文件,然后下載到本地通過jvisualvm分析對象的引用鏈的方式來定位具體頻繁創建對象的地方,dump文件下載下來有5G多,整個導入過程都花了10多分鍾。想查看所占空間較多對象的引用鏈,直接OOM了,dump對象太大了。這時候就換了種思路,查看占用空間比較大的一系列對象,看能不能找出什么端倪。占用空間最大的幾類對象如下圖
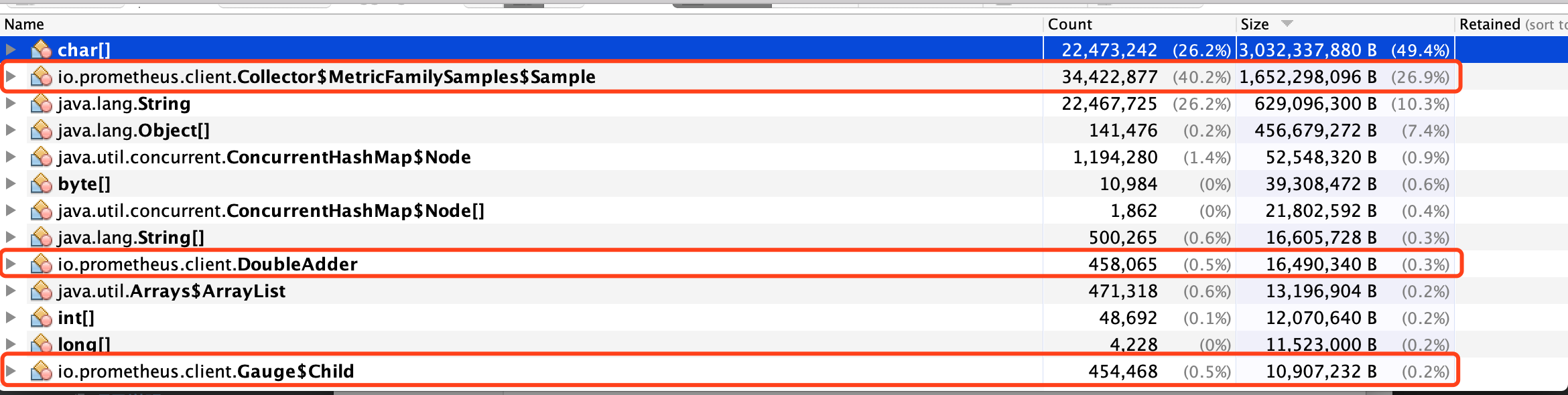
發現排第一的chart[]對象里面,存在一些metrics監控的具體指標的相關內容,排第二的io.prometheus.client.Collector$MetricFamilySample$Sample和排第9和第13對象都是spring boot中metrics指標監控相關的對象,所以此時懷疑metrics監控的某個地方在頻繁創建對象,首先考慮的是否因為metrics指標太多導致的,於是登錄線上機器curl localhost:8080/mertrics > metrics.log,發現響應內容有50多M,參考其他相關的正常應用,指標總共內容也就10多M左右,打開指標內容發現了很多類似如下圖的指標
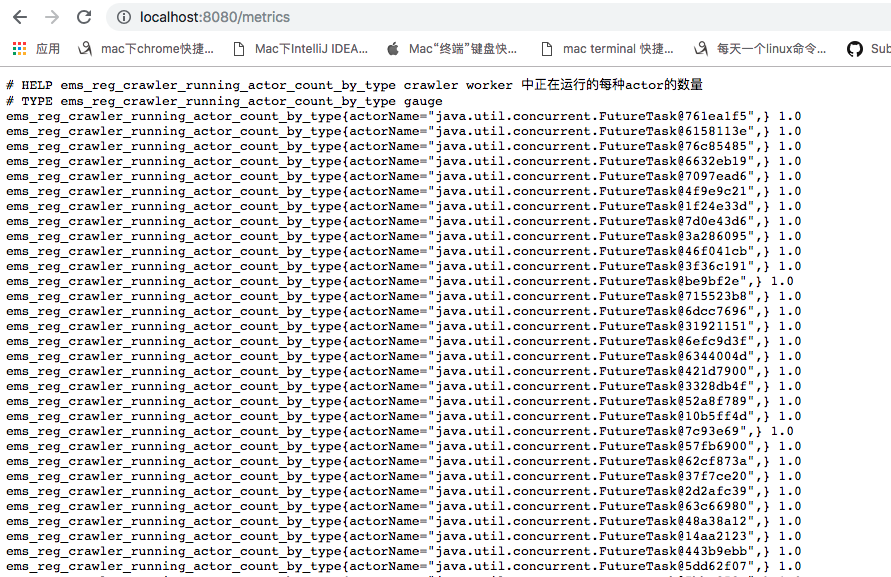
看到了這里已經可以確定代碼中上報這個指標是存在問題的,並沒有達到我們想要的效果,所以也懷疑也是這個地方導致的Full GC頻繁。
問題初步解決
- 由於這個指標也無關緊要,初步解決方案就把上報該指標的代碼給干掉。上線后看下Full GC問題是否會得到改善,果然,上線后Full GC告警問題已經解決。
初步解決后的思考,為什么會有這個問題?
- 外部監控系統,每25s會來調用metrics這個接口,這個接口會把所有的metrics指標轉成字符串然后作為http響應內容響應。監控每來調用一次就會產生一個50多M的字符串,導致了頻繁YGC,進而導致了晉升至年老代的對象也多了起來,最終年老代內存占用達到70%觸發了Full GC。
根源問題重現
- 此處采用metrics的作用:統計線程池執行各類任務的數量。為了簡化代碼,用一個map來統計,重現代碼如下
import java.util.Map;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 線程池通過submit方式提交任務,會把Runnable封裝成FutureTask。
* 直接導致了Runnable重寫的toString方法在afterExecute統計的時候沒有起到我們想要的作用,
* 最終導致幾乎每一個任務(除非hashCode相同)就按照一類任務進行統計。所以這個metricsMap會越來越大,調用metrics接口的時候,會把該map轉成一個字符返回
*/
public class GCTest {
/**
* 統計各類任務已經執行的數量
* 此處為了簡化代碼,只用map來代替metrics統計
*/
private static Map<String, AtomicInteger> metricsMap = new ConcurrentHashMap<>();
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>()){
/**
* 統計各類任務執行的數量
* @param r
* @param t
*/
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
metricsMap.compute(r.toString(), (s, atomicInteger) ->
new AtomicInteger(atomicInteger == null ? 0 : atomicInteger.incrementAndGet()));
}
};
/**
* 源源不斷的任務添加進線程池被執行
*/
for (int i =0; i < 1000; i++) {
threadPoolExecutor.submit(new SimpleRunnable());
}
Thread.sleep(1000 * 2);
System.out.println(metricsMap);
threadPoolExecutor.shutdownNow();
}
static class SimpleRunnable implements Runnable{
@Override
public void run() {
System.out.println("SimpleRunnable execute success");
}
/**
* 重寫toString用於統計任務數
* @return
*/
@Override
public String toString(){
return this.getClass().getSimpleName();
}
}
}
最終解決
- 可以把submit改成execute即可
總結
- 以上重顯代碼可以看出metricsMap中的元素是會越來越多的。如果就這樣下去,最終的結果也會出現OOM。
- 根本原因還是對ThreadPoolExecutor不夠熟悉,所以出現了這次問題。
- 個人感覺Full GC類問題是比較讓人頭疼的。這些問題並不會想代碼語法問題一樣,ide會提示我們具體錯在哪里,我們只要修改對應地方基本都能解決。造成Full GC頻繁的原因也有很多,比如可能是jvm參數設置不合理、Metaspace空間觸發、頻繁創建對象觸發等等。
- 如果確定了是頻繁創建對象導致,那么接下來的目的就是確定頻繁創建對象的對應代碼處,這時候可以選擇通過dump線上堆棧,然后下載到本地。選擇一些可視化分析工具進行分析。最終定位到出問題的代碼處,然后解決問題。
版權聲明
作者:wycm
出處:https://www.cnblogs.com/w-y-c-m/p/9919717.html
您的支持是對博主最大的鼓勵,感謝您的認真閱讀。
本文版權歸作者所有,歡迎轉載,但未經作者同意必須保留此段聲明,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利。
