FCN 全卷積網絡 Fully Convolutional Networks for Semantic Segmentation
今天實驗室停電,無聊把原來的一個分享PPT發上來
語義分割
語義分割是計算機視覺中的基本任務,也是計算機視覺的熱點,在語義分割中我們需要將視覺輸入分為不同的語義可解釋類別,「語義Semantic Segmentation的可解釋性」即分類類別在真實世界中是有意義的。
例如,我們可能需要區分圖像中屬於汽車的所有像素,並把這些像素塗成藍色。與圖像分類,語義分割使我們對圖像有更加細致的了解。說白了,就是將圖片上所有的像素點進行分類。


CNN與FCN
CNN這幾年一直在驅動着圖像識別領域的進步。無論是整張圖片的分類,還是物體檢測,關鍵點檢測等都在CNN的幫助下得到了非常大的發展。

但是圖像語義分割不同於以上任務,前面說了,需要預測一幅圖像中所有像素點的類別,這是個空間密集型的預測任務。
傳統用CNN進行語義分割的方法是“將像素周圍一個小區域作為CNN輸入,做訓練和預測。這樣做
- 存儲開銷大
- 計算效率低下,過多的重復計算
- 如何來確定區域大小,這也限制了感知區域的大小
而FCN能夠對圖像進行像素級的分類,與經典的CNN在卷積層之后使用全連接層得到固定長度的特征向量進行分類不同,FCN可以接受任意尺寸的輸入圖像,采用反卷積層對最后一個卷積層的feature map進行上采樣,使它恢復到輸入圖像相同的尺寸,從而可以對每個像素都產生了一個預測, 同時保留了原始輸入圖像中的空間信息, 最后在上采樣的特征圖上進行逐像素分類,從而解決語義分割問題。

FCN的幾大關鍵技術
卷積化
經典的CNN分類所使用的網絡通常會在最后連接全連接層,它會將原來二維的矩陣壓縮成一維的,從而丟失了空間信息,最后訓練輸出一個向量,這就是我們的分類標簽。
而圖像語義分割的輸出則需要是個分割圖,且不論尺寸大小,但是至少是二維的。所以,我們丟棄全連接層,換上卷積層,而這就是所謂的卷積化了。

上采樣 Upsampling
上采樣也就是對應於上圖中最后生成heatmap的過程。
上面采用的網絡經過5次卷積+池化后,圖像尺寸依次縮小了 2、4、8、16、32倍,對最后一層做32倍上采樣,就可以得到與原圖一樣的大小,現在我們需要將卷積層輸出的圖片大小還原成原始圖片大小,在FCN中就設計了一種方式,叫做上采樣,具體實現就是反卷積。

上采樣圖示
- 卷積
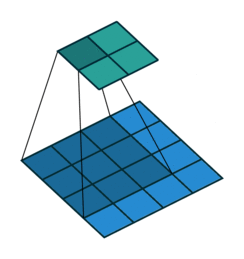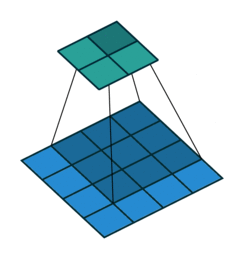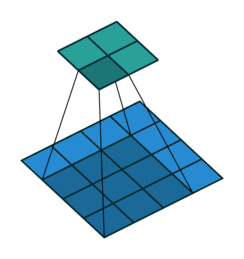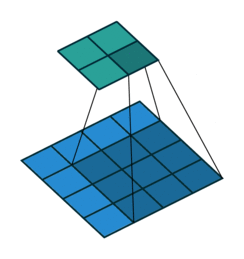
- 反卷積
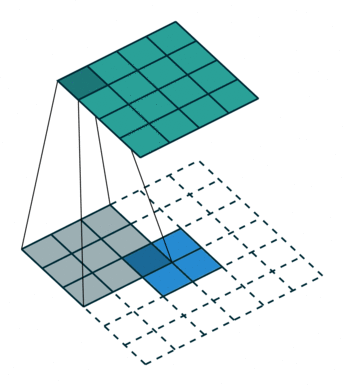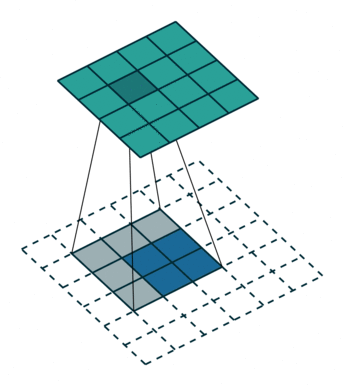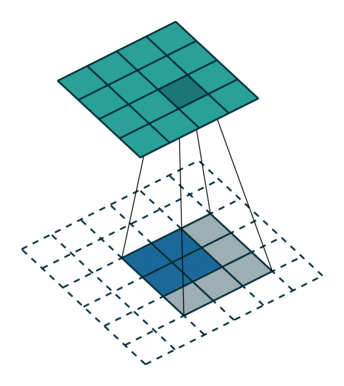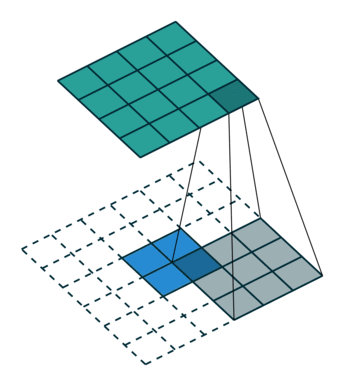
在文章中,作者發現直接做32倍反卷積,結果不精確,所以設計了一種方式來解決這個問題。
FCN結構設計

現在文章有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap進行upsampling操作之后,因為這樣的操作還原的圖片僅僅是conv5中的卷積核中的特征,限於精度問題不能夠很好地還原圖像當中的特征,因此在這里向前迭代。把conv4中的卷積核對上一次upsampling之后的圖進行反卷積補充細節(相當於一個差值過程),最后把conv3中的卷積核對剛才upsampling之后的圖像進行再次反卷積補充細節,最后就完成了整個圖像的還原。
效果
幾個指標
- pixel accuracy
- mean accuracy
- mean IU: IU(region intersection over union)
- frequency weighted IU

