2017 SIGIR
簡單介紹
IRGAN將GAN用在信息檢索(Information Retrieval)領域,通過GAN的思想將生成檢索模型和判別檢索模型統一起來,對於生成器采用了基於策略梯度的強化學習來訓練,在三種典型的IR任務上(四個數據集)得到了更顯著的效果。
生成式和判別式的檢索模型
生成式檢索模型(query -> document)認為query和document之間存在潛在的生成過程,其缺點在於很難利用其它相關的信息,比如鏈接數,點擊數等document和document之間的相關數據。
判別式檢索模型(query+document -> relevance)同時考慮query和document作為特征,預測它們的相關性,其缺點在於缺乏獲取有用特征的方法。
GAN
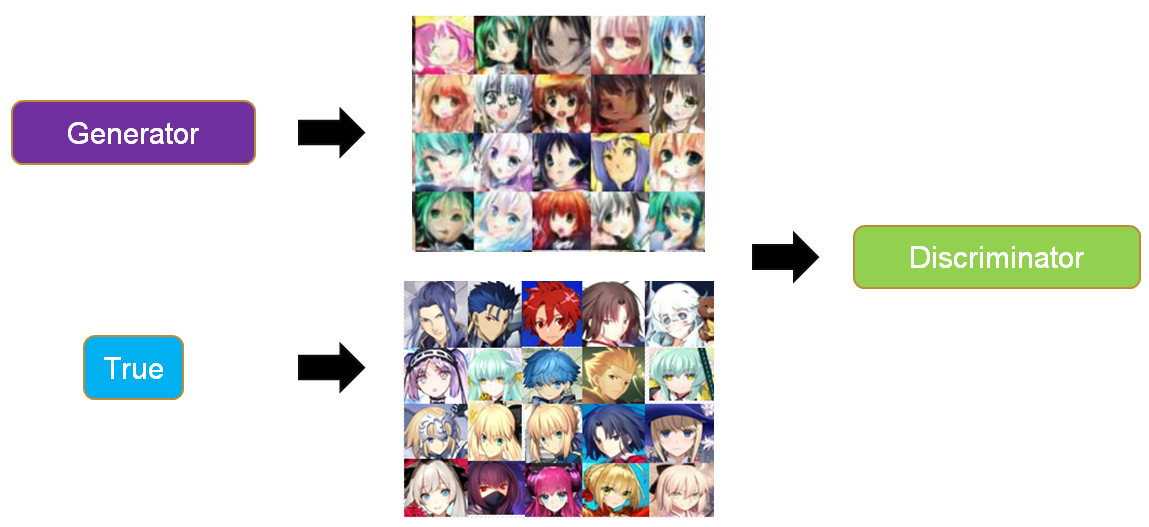
GAN里面的生成器和判別器通過相互博弈來完成工作,舉例來說,我們要生成動漫人物頭像,如下兩個圖所示。
- 訓練判別器:初代的生成器Generator0會生成很模糊的動漫頭像,這個時候我們把Generator0產生的頭像作為0標簽,真實的頭像作為1標簽丟入到初代的判別器Discriminator0中訓練,得到新一代判別器Discriminator1,這個判別器能夠辨認真實頭像和Generator0產生的假頭像,如果輸入是一個真實頭像,Discriminator1會輸出1,如果輸入是一個Generator0生成的頭像,Discriminator1會輸出0。
- 訓練生成器:然后,我們訓練Generator0,目標是使得Discriminator1判斷生成器生成的頭像為真實頭像(輸出標簽為1),以這個為目標訓練得到的Generator1能夠成功騙過Discriminator1。對於Discriminator1,如果輸入是一個Generator1生成的頭像,它會輸出1。
- 迭代博弈:上面兩個步驟就完成了一次博弈,接着會不斷迭代這個博弈,Discriminator1會進化成Discriminator2能夠成功分辨Generator1產生的是假頭像(輸出0標簽),然后Generator1為了騙過Discriminator2又會進化成Generator2。不斷迭代這個過程,最后就能生成一些逼真的動漫人物頭像。

IRGAN
- 可以利用GAN的思想,把兩種檢索模型結合起來,克服它們的缺點。如下圖所示。
- 以生成式檢索模型作為生成器,輸入query,我們選取相關的document,構成數據對,作為生成數據。
- 以判別式檢索模型作為判別器,用一個打分score來表示判別器的判別能力,判別器越能區分生成數據和真實數據(即輸入生成數據時輸出0,輸入真實數據時輸出1),則判別能力越強。
- 根據生成器生成的固定數據和真實數據,訓練判別器。然后固定判別器,訓練生成器使得判別器的判別能力最小化(即輸入生成數據時也輸出1)。這樣完成一次博弈,迭代多次博弈不斷訓練。

從極大似然法(MLE)到GAN再到IRGAN
- 傳統的生成問題:給定一個數據集D,我們構建一個模型,模型產生的數據分布q(x)可以擬合真實的數據分布p(x),我們希望真實的數據在我們學到的模型上有一個很高的概率密度。
- 最小化KL散度:如下式所示,其實這個過程就是在最小化交叉熵。因為真實數據分布不變,信息熵不變,可以看作是在最小化相對熵(KL散度)。這幾個熵我在另一篇博文信息熵,交叉熵和相對熵中有介紹。
\[\max_{q} \frac {1}{|D|} \sum_{x \in D} log \ q(x) \approx \max_{q} E_{x \sim q(x)} [log \ q(x)] = \min_q \int_{x} p(x) \ log \frac {1}{q(x)} \]
- 不對稱問題:這樣一個廣為使用方法有個不對稱的問題,對於KL散度,當p(x)>0而q(x)趨近於0時會產生一個高損失,這沒有問題,但是當q(x)>0而p(x)趨近於0時候,損失卻趨近於0,這與我們的目的不相符。
\[\underbrace{\int_{x} p(x) \ log \frac {1}{q(x)}}_{\text{交叉熵}} - \underbrace{\int_{x} p(x) \ log \frac {1}{p(x)}}_{\text{信息熵}} = \underbrace{\int_{x} p(x) \ log \frac {p(x)}{q(x)})}_{相對熵KL(p||q)} \]
- 不一致問題:還有一個缺點就是,我們實際做的事情和我們希望的事情並不一致,我們實際做的是讓真實的數據在我們學習的模型上有一個很高的概率密度,也就是\(\max_q E_{x \sim p(x)}[log \ q(x)]\)(實際的訓練評估中我們通過\(\max_{q} \frac {1}{|D|} \sum_{x \in D} log \ q(x)\) 來approximate這個式子)。但是我們希望做的事情是讓生成的數據接近真實數據,也就是生成的數據在真實的分布上有一個很高的概率密度,也就是\(\max_q E_{x \sim q(x)}[log \ p(x)]\),但是這件事情我們是做不到的,因為我們並不知道真實數據的分布,我們沒法計算p(x),如果知道真實數據的分布我們就不用做這件事了。當然,q(x)等於p(x)時這兩個式子就是一樣的。
- GAN:上面提到的一個難點是我們沒有辦法計算p(x),不知道真實數據的分布長什么樣,但是在GAN里面可以構建一個判別器來判別一個數據是真實的還是生成的。同時GAN最小化的不是KL散度,而是JS散度,這就解決了不對稱的問題。
- 從MLE到GAN:MLE就是模型已定,參數未知,找出一組參數使得模型產生出觀測數據的概率最大。用GAN里面的Generator(可以不局限於特定模型比如高斯分布)可以得到一個general的模型。利用GAN里面的Discriminator可以調整模型使得觀測數據的概率最大。
- 從GAN到IRGAN:IRGAN就是把GAN的技術用到信息檢索中,IRGAN和GAN的不同點在於IRGAN生成器是輸入query然后從已有的document中選取,而GAN是用隨機噪音進行生成的。因為IRGAN生成的數據是離散的(需要對documents進行采樣),所以需要使用基於策略梯度的強化學習來訓練生成器。
公式
- 最小化最大化:前面提到,整個訓練就是生成器和判別器博弈的過程,如下圖中的式子,先進行一個最大化訓練一個判別能力強的判別器,然后做一個最小化來訓練一個能騙過判別器的生成器。不斷迭代這個過程。

2. **JS散度**:對式子進行最大化后(訓練判別器)得到的這個式子其實是一個JS散度,衡量生成數據和真實數據的分布。然后對JS散度進行最小化(訓練生成器)就可以使生成數據逼近真實數據。 
3. **訓練判別器**:最大化這個式子,使用sample的方法,發現其實就是一個邏輯回歸的二分類問題。 
4. **訓練生成器**:因為IRGAN里面最后是從document池中進行采樣,可能softmax概率改變一點點,采樣的結果並不會產生變化,這樣難以進行梯度的傳遞更新,所以使用基於策略梯度的強化學習來訓練。 
5. **目標函數的改進**:訓練生成器的時候,考慮到目標函數在一開始下降地比較慢,做了一下修改。於是最后得到的策略梯度也發生了變化,獎賞項變成了判別器輸出的log,這也很直觀,強化學習要讓獎賞越來越大,這里剛好就是讓判別器的輸出越大越好(接近1,讓判別器以為生成的數據是真實的)。后面考慮到log使得訓練不穩定,於是把log也去掉了。最后為了讓獎賞有正有負,做了一個乘2減1的修正。 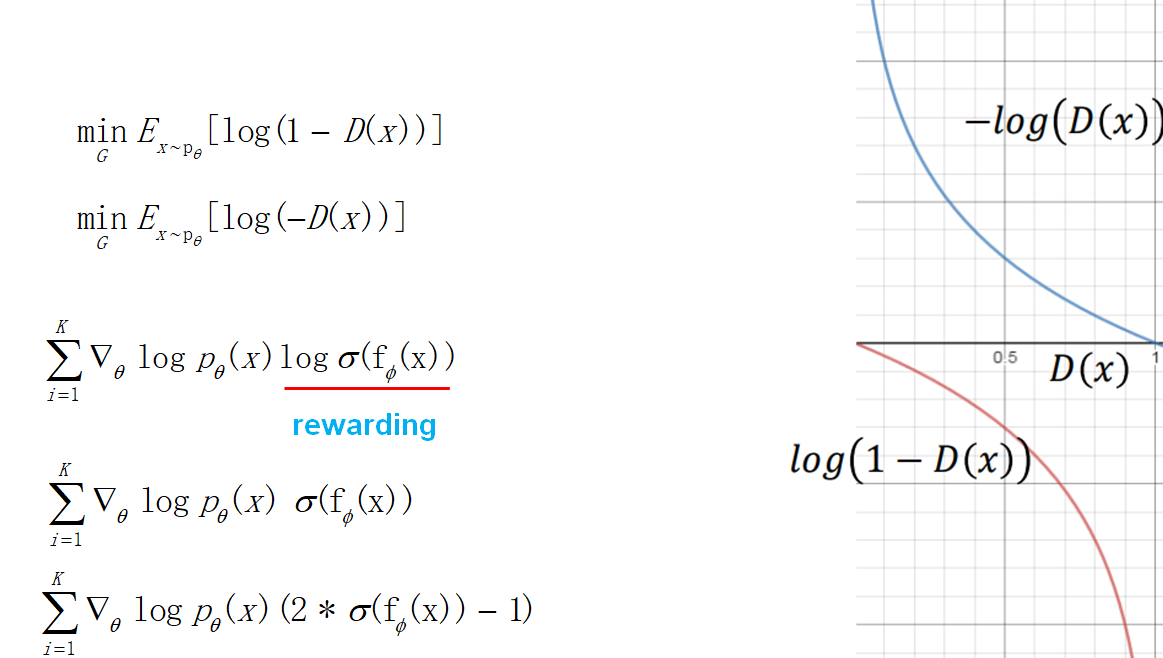
實驗
如下幾個圖所示,其中s(x)表示生成器和判別器的公式。


