利用kettle Spoon從oracle或mysql定時增量更新數據到Elasticsearch
https://blog.csdn.net/jin110502116/article/details/79690483
背景:
目前的業務數據數據已經很大了,關於查詢內的需求比較多,傳統數據庫已經不能滿足目前的需要。必須得使用全文檢索了,了解了相關資料,發現Elasticsearch這個工具比較強大。於是就開始新一段的爬坑之旅了...
Elasticsearch安裝什么的很方便,但是更新卻是個很大的問題。開始嘗試了Logstash這個工具,各種嘗試后,還是放棄了。主要原因是速度慢,數據源是oracle數據庫的時候,不能增量更新,生成的索引文檔id各種問題,果斷放棄...
后面嘗試了Kettle spoon,換了n多個版本,都沒有找到一個跟Elasticsearch兼容的比較好的版本。查了n多資料,發現沒一個能夠說清楚解決思路的。自己也想過放棄,但項目上有剛需,只得硬着頭皮弄了。功夫不負有心人,終於成功了...
分享:
寫在前面:第一篇博客,不喜勿噴哈。之前一直潛水,這次想奉獻一下~
目的:將mysql或oracle里面的數據定時增量抽取到ES。
思路:利用spoon發送http post請求,然后獲取索引中最大的時間,然后將數據庫中查出大於該時間的記錄,定時導入到ES即可。(還有一種常見的是,將每種類型的數據更新完后,存入到一張管理表總,下次抽取大於這個時間的)
工具下載鏈接:
Spoon 7.1修復版本:鏈接:https://pan.baidu.com/s/1bPAjMWt_ur7BqPI6zkkE4g 密碼:v1li
Elasticsearch2.3.2 : 鏈接:https://pan.baidu.com/s/1FlyvCCSjEIqZJB1F59qkzg 密碼:w49r
Elasticsearch-head : 鏈接:https://pan.baidu.com/s/1pCf9e-WH3N9b5JFSMFPpAg 密碼:1959
方案步驟(舉例):
1、新建索引,設置分片數,備份數
2、新建索引類型(舉個例子)
注意:需要使用統計功能的字段類型不能設置為String
請求地址:http://localhost:9200/gj_index/tx_type/_mapping/
請求類型:put
請求參數:
{
"tx_type": {
"properties": {
"ZBY": {
"type": "double"
},
"ZBX": {
"type": "double"
},
"DZ": {
"type": "string",
"index":"not_analyzed" //ES不分析這個字段,這樣只能進行精確查詢
},
"IMSI": {
"type": "string"
},
"TMSI": {
"type": "string"
},
"IMEI": {
"type": "string"
},
"JLSJ": {
"type": "long" //時間戳,不能使用String,否則無法統計。這邊轉成了秒
},
"SBID": {
"type": "string"
},
"LAC": {
"type": "string"
}
}
}}
截圖如下:

3、先模擬請求,找到索引中某類型(testtype)中最大的時間字段(endtime),如圖所示:

4、新建Spoon轉換、任務
獲取到索引中最大的時間戳(模擬請求,獲取該索引中endtime最大的那個值)
a、整體效果圖:

b、設置請求參數

c、發送post請求

d、獲取當前類型中最大的時間


新建插入索引轉換,將大於此時間的記錄獲取到,直接插入到ES中
a、整體效果圖

b、表輸入
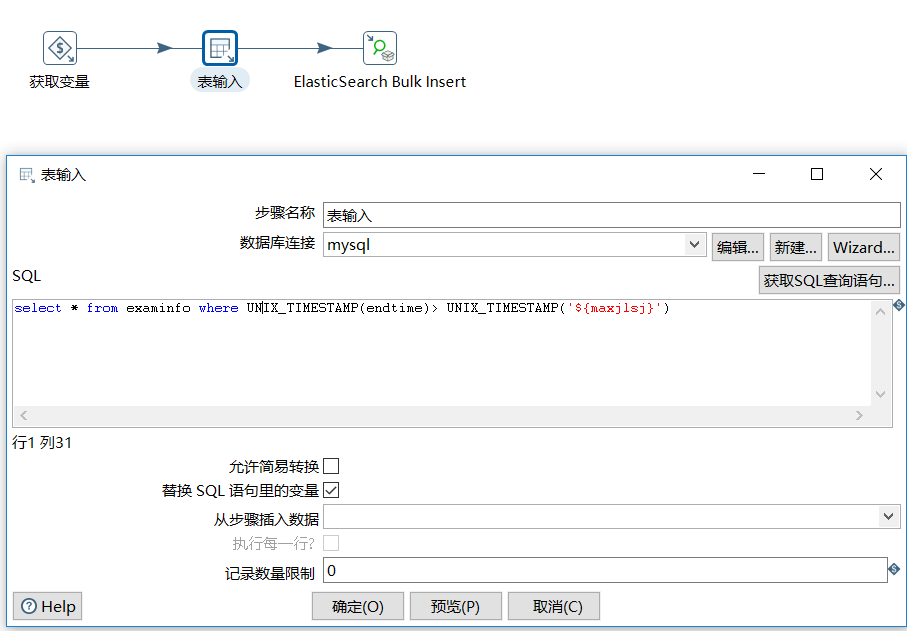

c、插入到索引


新建定時任務,定時增量抽取數據
a、 每隔5秒執行一次增量更新任務

b、設置job變量 maxjlsl

c、添加轉換(獲取索引中最大時間)

d、取得轉換任務中的最大時間,更新到 maxjlsj

e、添加轉換(插入數據到ES)

點擊運行,大功告成 ...