一、介紹
在傳統的分類模型中,為了解決多分類問題(例如三個類別:貓、狗和豬),就需要提供大量的貓、狗和豬的圖片用以模型訓練,然后給定一張新的圖片,就能判定屬於貓、狗或豬的其中哪一類。但是對於之前訓練圖片未出現的類別(例如牛),這個模型便無法將牛識別出來,而ZSL就是為了解決這種問題。在ZSL中,某一類別在訓練樣本中未出現,但是我們知道這個類別的特征,然后通過語料知識庫,便可以將這個類別識別出來。
zero-shot learning的一個重要理論基礎就是利用高維語義特征代替樣本的低維特征,使得訓練出來的模型具有遷移性。語義向量就是高維語義特征,比如一個物體的高維語義為“四條腿,有尾巴,會汪汪叫,寵物的一種”,那我們就可以判斷它是狗,高維語義對它沒有細節描述,但是能夠很好的對其分類,分類是我們的目的,所以可以舍去低維特征,不需要“全面”。
二、DAP模型
《Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer》
DAP可以理解為一個三層模型:第一層是原始輸入層,例如一張電子圖片(可以用像素的方式進行描述);第二層是p維特征空間,每一維代表一個特征(例如是否有尾巴、是否有毛等等);第三層是輸出層,輸出模型對輸出樣本的類別判斷。在第一層和第二層中間,訓練p個分類器,用於對一張圖片判斷是否符合p維特征空間各個維度所對應的特征;在第二層和第三層間,有一個語料知識庫,用於保存p維特征空間和輸出y的對應關系,這個語料知識庫是事先人為設定的(暫時理解是這樣?)。
假設我們已經訓練好了一個DAP模型,第一層和第二層間的分類器可以判斷 是否黑眼圈、是否喜歡吃竹子 之類的特征,然后在語料知識庫里面包含一個映射:黑眼圈 喜歡吃竹子--> 熊貓,那么即使我們的模型在訓練時沒有見過熊貓的圖片,在遇到熊貓的圖片時,我們可以直接通過對圖片的特征進行分析,然后結合知識語料庫判斷出這張圖片是熊貓。假設即使語料知識庫里面不包含 黑眼圈 喜歡吃竹子--> 熊貓 的映射,我們也可以通過計算熊貓圖片的特征與其他訓練樣本的特征的漢明距離度量,得到熊貓和什么動物比較類似的信息。整個DAP的運作思想就是類似於上述過程。
缺點
- 算法引入了中間層,核心在於盡可能得判定好每幅圖像所對應的特征,而不是直接去預測出類別;因此DAP模型在判定屬性時可能會做得很好,但是在預測類別時卻不一定;
- 無法利用新的樣本逐步改善分類器的功能;
- 無法利用額外的屬性信息(如Wordnet等)
三、ALE模型
概要
在分類問題中,每個類別被映射到屬性空間中,即每個類別可用一個屬性向量來表示(例如:熊貓—>(黑眼圈,愛吃竹子,貓科動物......))。ALE模型即學習一個函數F,該函數用於衡量每一幅圖像和每個屬性向量之間的匹配度. ALE模型確保對於每幅圖像,和分類正確的類別的相容性比和其他類別的匹配度高。通過在AWA和CUB數據集上的實驗表明,ALE模型比DAP等模型在ZSL問題上的表現更好,而且ALE可以利用額外的類別信息來提高模型表現,以及可以從零樣本學習遷移到其他擁有大量數據的學習問題中。
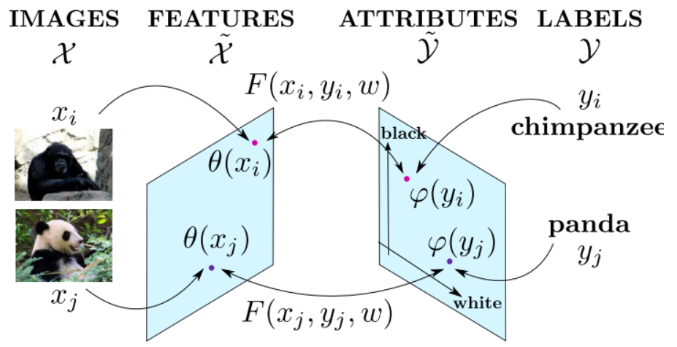
在CV領域,大部分的工作都集中與如何從一幅圖像里抽取出合適的特征信息(即上圖左側),而在ALE中,研究的重心在於如何把一個類別映射到合適的歐幾里得屬性空間。
模型推導
定義f(x; w)為預測函數,定義F(x, y; w)為輸入x和類別y之間的匹配度。則當給定一個需要預測類別的數據x時,預測函數f所做的便是從所有類別y中,找到一個類別y使得F(x, y; w)的值最大。
對於模型的參數w的求解過程為:對於所有樣本(x, y),盡可能得最大化 \(\frac{1}{n} \sum_{n=1}^{N}{F(x,y;\omega)}\) ,但是對於這個目標函數,在圖像分類問題中無法直接優化得出我們的最終目標(具體為什么我也不知道。。。)因此作者從WSABIE算法中得到靈感,並借此來實現ALE算法。
Zero-shot learning:
文中借鑒WSABIE算法,得到我們的目標函數為:\(\frac {1}{N} \sum_{n=1}^{N} \max_{y∈Y}l(x_n, y_n, y)\).該目標函數和SSVM很類似,對此解釋如下:
- 對於每一個樣本,計算對應每個類別的得分。然后從其他所有不是正確類別的得分中找出最大的得分;
- 逐樣本累加后即得到損失函數的值,然后利用SGD等方法對參數進行更新即可;
- 算法的核心思想和SVM很像,即讓錯誤分類的得分得盡可能得比正確分類的得分小。
Few-shots learning:
在上述的Zero-shot learning下對應的模型中,每個類別通過映射\(\phi(y)\)得到語義空間的值是實現通過先驗信息固定的,但是在使用模型預測的過程中,可能會逐步遇到之前訓練樣本中不存在對應類別的數據,那么ALE就具有能逐步利用新的訓練樣本來改善模型的作用。在此問題下,模型的目標函數變為:
在上述公式中,參數\(\Phi\)為在一定維度隨機初始化的參數。在使用SGD等方法進行參數更新的時候,為使該損失函數的值盡可能得小,顯然\(\Phi\)要盡可能得接近\(\Phi^{\Lambda}\),同時也利用了訓練樣本中存在的部分信息。從而使得AEL模型達到可以逐步利用新的訓練樣本(之前的訓練樣本中不存在的類別)的信息來改善模型。
ALE模型如何利用額外的屬性等信息來源?
DAP模型針對每一個屬性訓練一個分類器,再從屬性向量空間里面找到和測試樣本最接近的類別。然后ALE並沒有特別針對語義向量空間的每一個維度進行學習,ALE直接學習了從特征空間到語義向量空間的映射。其中\(\theta(x)\)表示從圖像得到的特征,\(\varphi (y)\)則是從類別到語義向量空間的映射。
因為\(\varphi (y)\)是獨立於訓練數據的,因此可以根據需要變換為其他種類的先驗信息,例如HLE模型,而在DAP模型中,因為模型限定了只能對單一屬性進行訓練,因為就無法利用其他種類的先驗信息了。
模型如何對ZS類進行預測
ALE模型利用屬性等語義信息,將每個類別標簽嵌入到維度為85的語義空間內(假設使用85個屬性描述類別)。ALE模型所做的就是學習到一個從特征空間到語義空間的映射,該映射確保得到語義空間內的點與正確類別的語義向量更近,盡可能得與錯誤類別的語義向量更遠。這樣,在對ZS進行預測時,映射所得到的在語義空間上的點與在訓練時出現過的那些類別所對應點會很遠,從而使得與正確的ZS類對應的語義向量更近,從而進行預測。
DAP與ALE
針對每個測試樣本,DAP利用分類器得到一個屬性向量,然后直接從預定義好的屬性空間里找到一個與該屬性向量最近的類別作為預測結果輸出。而ALE在訓練時利用映射函數衡量每個輸入與語義向量之間的得分,損失函數的訓練過程確保正確類別的得分都比錯誤類別的得分高出一定值(類似SVM),因此ALE的訓練過程是直接以類別預測為指導的。
DAP的模型結構其實和ALE模型的結構大體上是一致的,甚至連映射矩陣、語義空間的矩陣維度都是相同的,但是區別在於兩者的監督方式不同。DAP針對是在屬性上進行 監督學習的,針對每個屬性維度學習一個分類器;而ALE是針對類別進行監督學習的,從而導致映射層的參數不同。
DAP的監督方式沒有學習到屬性之間的相關性,而ALE訓練之后確保類別相似的在語義空間內都具有類似的分布,且類別相似大都具有相同的特征,導致了具有不同特征的類別在語義空間內具有不同的分布,從而學習到屬性間的相關性。
四、SAE模型
概要
傳統的ZSL問題,經常遇到映射領域漂移問題,在SAE模型中,為了解決這個問題,要求輸入x經過變換生成的屬性層S,擁有恢復到原來輸入層x的功能,並且添加了映射層必須具有具體的語義意思的限制,通過加入這個限制,確保了映射函數必須盡可能得保留原輸入層的所有信息。
映射領域漂移(Projection domain shift)
對於zero-shot learning問題,由於訓練模型時,對於測試數據類別是不可見的,因此,當訓練集和測試集的類別相差很大的時候,比如一個里面全是動物,另一個全是家具,在這種情況下,傳統zero-shot learning的效果將受到很大的影響。
為什么SAE模型可以解決映射領域漂移問題?
介紹
如今CV的研究方向已經逐步朝着大規模的分類問題發展了,但是由於在大數據集(如ImageNet)的21814個類別里,有296個類別的圖像僅僅只有一個圖像數據,因此可擴展性還是一個嚴峻的問題。
SAE模型的輸入特征空間是通過GoogleNet或則AlexNet從圖像數據里提取出來的特征,而輸出語義空間是頭ing過Skip-gram在Wikipedia訓練得到的word2vec向量。
問題
- SAE模型在預測的時候,是從unseen classes的語義空間向量里找到一個和當前測試樣本距離最近的作為預測結果。那么在實際應用中,當一個新的樣本進來,我們怎么確定這個樣本是屬於seen classes還是unseen classes的語義空間里進行預測呢?
五、SCoRE
《Semantically Consistent Regularization for Zero-Shot Recognition》
Deep-RIS
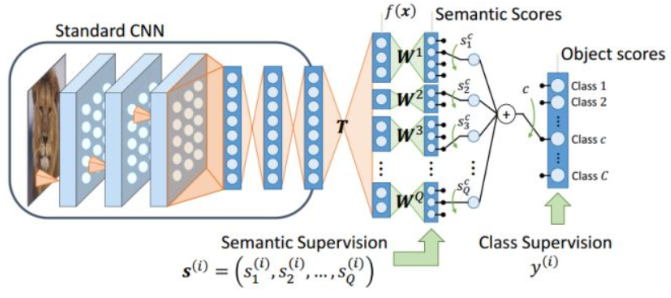
要學習樣本X到屬性向量S的映射W,設訓練集:
其中x為輸入樣本,y為樣本標簽;屬性集合為:
對於Q個屬性,為每個屬性建立一個CNN,作為屬性分類器:
其中, 為sigmoid函數。損失函數可以定義為交叉熵損失。
為sigmoid函數。損失函數可以定義為交叉熵損失。
Deep-RULE
假設有Q個屬性,用二值表示;有C個類別,則可以將每個類別轉換為one-hot的形式:
即為類別y的語義編碼,則分類器可以定義為:
其中 \(\theta(x; \Theta)\) 表示輸入圖片的特征表示;T為一個映射矩陣,\(\Theta^{T}\)表示類別的one-hot表示。若使用神經網絡結構實現上述目標函數,只需要先用CNN提取圖片的特征,通過一個全連接層將特征映射到語義空間中(也就是學習映射矩陣T),輸出時為類別y的形式即可。損失函數直接采用網絡輸出和真實樣本之間的交叉熵損失即可。
Deep-RIS和Deep-RULE之間的關系
可以從兩者的損失函數,來說明它們之間的關系。Deep-RIS對每一個單獨的屬性ak(x)進行了監督學習,這是一種很強的約束,它把屬性向量的表達限制在一個固定的范圍內;反觀Deep-RULE,它建立了一個語義空間SV,將樣本和類別屬性化之后,投影到該語義空間中。這樣做的結果是:屬性向量之間有了相關關系,使得屬性向量的表達更加豐富;但同時,會產生冗余空間,這個冗余空間的問題在於,它會加重semantic domain shift的問題。更詳細的解釋是:設訓練集中樣本的屬性向量所構成的語義空間XV的往往要小於SV,令NV=SV-XV,如果在測試集中,測試樣本的屬性向量處於NV中,則由訓練樣本訓練出來的分類器將無法對該測試樣本進行分類。在Deep-RIS中,對於樣本到屬性向量之間的映射有着非常強的約束,使得XV和SV相近。在同樣的屬性定義的前提下,由於NV的存在,使得Deep-RULE更有可能無法處理測試集中的類別。
論述:但同時,會產生冗余空間,這個冗余空間的問題在於,它會加重semantic domain shift的問題
解釋:假設有a b c d四個特征,訓練集的類別A和B分別具有ab和ac特征,即使測試集的類別是bc,也能進行預測,因為訓練時已經都對abc的語義空間進行了監督學習,但是如果測試集包含d特征,這是類別A和B都不具有的特征(領域漂移問題),這就會使得模型無法正常得進行預測。
通過上面的論述其實可以知道,如果NV很小,幾乎沒有測試集類別的屬性向量位於其中,則Deep-RULE的方法會取得更好的效果;如果NV很大,測試集中很多類別的屬性向量位於其中,則Deep-RIS的方法可能會更好。
通過對上述兩類方法的分析,可以發現,兩種方法存在互補性。如果能夠將Deep-RIS對於單個屬性的約束融入到Deep-RULE中,就可以一定程度上使得NV變小,從而得到更好的結果。
以DAP和ALE兩種典型的模型為例,當采用屬性作為語義空間的表達時,兩者屬性空間的構成基本是一致的,都是由一系列的屬性構成(例如有尾巴、會飛等)。最核心的不同在於DAP針對每一個屬性監督學習一個分類器(如SVM),因此訓練樣本所包含的屬性空間信息往往和整個屬性空間差別很小。DAP對於每一個測試類別,輸出一個維度為D(屬性的個數)的向量。且DAP沒有學習到屬性之間的依賴關系,比如“水中動物”和“有翅膀”這兩個屬性就有着很強的負相關,則表明了我們可以利用更少的屬性維度去表達和之前一樣的信息。
而ALE直接從輸入的特征空間學習一個到屬性空間的映射,在訓練過程中采用rank函數——確保所有正確類別的得分都比錯誤類別高。模型的輸出是一個維度為C(類別個數)的變量,表示測試數據在每一個類別上的得分情況。因此ALE是從類別C的維度去進行監督學習的。在ALE訓練完成后,訓練樣本里存在的類別在測試時對應的得分也會最大,但是對於訓練樣本中不存在的類別(ZS類),因為在訓練時沒有數據可以用於ZS類的監督學習,所有在測試時ZS類的得分表現就沒有那么好。
因為屬性空間是利用先驗知識對所有類別映射而成的,因此存在一些屬性只有在ZS類別里存在,而在訓練類別里不存在。
以googlenet、CUB、attribute為例。pool5的輸出是1024維,相當於visual feature;然后接一個312維的fc1,(fc1參數shape為1024 * 312,相當於公式中的T),fc1的輸出fc_sem,用來做屬性預測,也就是RIS; fc_sem再接一個150維的 fc2,(fc2參數shape為312*150,相當於公式中的W),fc2的輸出fc_obj,用來做類別預測,也就是RULE。fc2的參數,才是wc,用來跟事先定義好的codeword做L2約束。如果wc,直接使用事先定義好的codeword,W不學習,只學習T,那么這個流程將會是是經典的套路:visual space投影到semantic space,然后投影后的visual feature和semantic feature,使用dot product度量類別之間的相似性。根據Train set上的類別信息,使用分類loss,學習T。這篇工作相當於把用於dot product的codeword,也改成可以學習的了,放松了約束,可以看成是一種正則,用於增加模型在測試集上的泛化能力。
問題
- Abstract: The latter addresses this issue but leaves part of the semantic space unsupervised.
- ALE和DAP中兩個參數W之間的區別?
六、遷移學習
參考
目前ZSL還是不能擺脫對其他模態信息的依賴:比如標注的屬性,或者用wordvec去提語義特征,多數做法是將視覺特征嵌入到其他模態空間,或者將多個模態特征映射到一個公共latent空間,利用最近鄰思想實現對未見類的分類,本質上也是一種知識遷移。
Transfer Learning涉及的范圍就很大了,最近我也在看,涉及的細分領域比如Domain Adaptation等等,許多Transfer Learning中的技術也用於提高ZSL的性能,比如將Self-taughting Learning,Self-Paced Learning的思想可以用到Transductive ZSL中提高ZSL的算法性能。