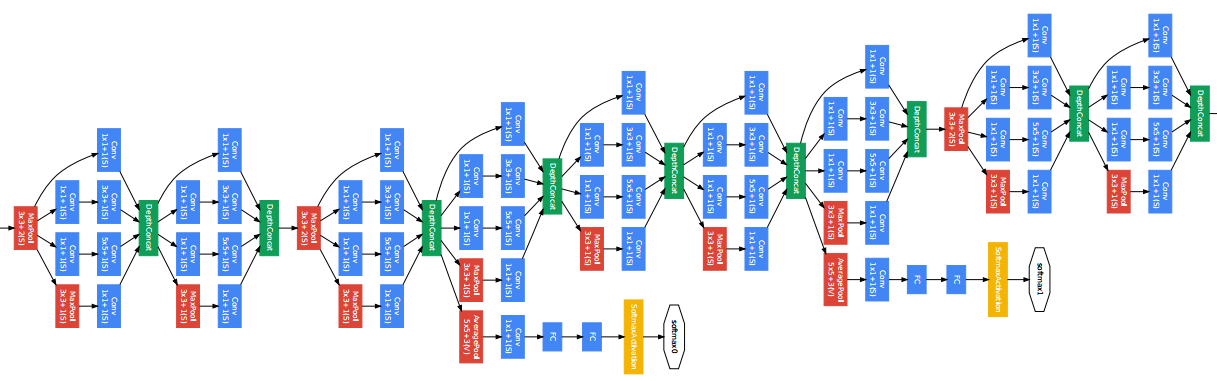

其中:
1、
VGG 網絡以及從 2012 年以來的 AlexNet 都遵循現在的基本卷積網絡的原型布局:一系列卷積層、最大池化層和激活層,最后還有一些全連接的分類層。
2、
ResNet 的作者將這些問題歸結成了一個單一的假設:直接映射是難以學習的。而且他們提出了一種修正方法:不再學習從 x 到 H(x) 的基本映射關系,而是學習這兩者之間的差異,也就是「殘差(residual)」。然后,為了計算 H(x),我們只需要將這個殘差加到輸入上即可。
假設殘差為 F(x)=H(x)-x,那么現在我們的網絡不會直接學習 H(x) 了,而是學習 F(x)+x。
這就帶來了你可能已經見過的著名 ResNet(殘差網絡)模塊

3、Inception 的作者使用了 1×1 卷積來「過濾」輸出的深度。一個 1×1 卷積一次僅查看一個值,但在多個通道上,它可以提取空間信息並將其壓縮到更低的維度。比如,使用 20 個 1×1 過濾器,一個大小為 64×64×100(具有 100 個特征映射)的輸入可以被壓縮到 64×64×20。通過減少輸入映射的數量,Inception 可以將不同的層變換並行地堆疊到一起,從而得到既深又寬(很多並行操作)的網絡。
4、Xception 更進一步。不再只是將輸入數據分割成幾個壓縮的數據塊,而是為每個輸出通道單獨映射空間相關性,然后再執行 1×1 的深度方面的卷積來獲取跨通道的相關性。從而獲得較好的效率。並且這個架構已經在通過 MobileNet 助力谷歌的移動視覺應用了。
最后,
遷移學習是一種機器學習技術,即我們可以將一個領域的知識(比如 ImageNet)應用到目標領域,從而可以極大減少所需要的數據點。在實踐中,這通常涉及到使用來自 ResNet、Inception 等的預訓練的權重初始化模型,然后要么將其用作特征提取器,要么就在一個新數據集上對最后幾層進行微調。使用遷移學習,這些模型可以在任何我們想要執行的相關任務上得到重新利用,從自動駕駛汽車的目標檢測到為視頻片段生成描述。
深度學習需要大量數據才能訓練處一個較好的模型。但是,有時候我們很難獲取大量數據,因為得到足夠大樣本量的特定領域的數據集並不是那么容易,這是否就意味着我們不能使用上深度學習這一黑科技啦?我很高興的告訴大家,事實並非如此。遷移學習就可以幫助我們使用上深度學習這一高大上的技術。
何為遷移學習?遷移學習是指使用一個預訓練的網絡:比如 VGG16 。VGG16 是基於大量真實圖像的 ImageNet 圖像庫預訓練的網絡。我們將學習的 VGG16 的權重遷移(transfer)到自己的卷積神經網絡上作為網絡的初始權重,然后微調(fine-tune)這些預訓練的通用網絡使它們能夠識別出人的activities圖像,從而提高對HAR的預測效果。
5、直接使用vgg來預測
這里我使用了一些小技巧。
from keras.applications.resnet50
import ResNet50
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
from keras.utils.data_utils import get_file
model = ResNet50(weights = 'imagenet')
path = '1.jpg'
img_path = get_file(path,origin = 'http://pic.qiantucdn.com/58pic/26/23/18/58c959d01a57d_1024.jpg')
print(img_path)
img = image.load_img(img_path, target_size =( 224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis = 0)
x = preprocess_input(x)
preds = model.predict(x)
print( 'Predicted:', decode_predictions(preds, top = 3)[ 0])
# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]
from keras.preprocessing import image
from keras.applications.resnet50 import preprocess_input, decode_predictions
import numpy as np
from keras.utils.data_utils import get_file
model = ResNet50(weights = 'imagenet')
path = '1.jpg'
img_path = get_file(path,origin = 'http://pic.qiantucdn.com/58pic/26/23/18/58c959d01a57d_1024.jpg')
print(img_path)
img = image.load_img(img_path, target_size =( 224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis = 0)
x = preprocess_input(x)
preds = model.predict(x)
print( 'Predicted:', decode_predictions(preds, top = 3)[ 0])
# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]

6、遷移學習
為了對遷移學習產生一個直觀的認識,不妨拿老師與學生之間的關系做類比。




一位老師通常在ta所教授的領域有着多年豐富的經驗,在這些積累的基礎上,老師們能夠在課堂上教授給學生們該領域最簡明扼要的內容。這個過程可以看做是老手與新手之間的“信息遷移”。
這個過程在神經網絡中也適用。
我們知道,神經網絡需要用數據來訓練,它從數據中獲得信息,進而把它們轉換成相應的權重。這些權重能夠被提取出來,遷移到其他的神經網絡中,我們“遷移”了這些學來的特征,就不需要從零開始訓練一個神經網絡了 。
簡單來說,預訓練模型(pre-trained model)是前人為了解決類似問題所創造出來的模型。你在解決問題的時候,不用從零開始訓練一個新模型,可以從在類似問題中訓練過的模型入手。
場景一:數據集小,數據相似度高(與pre-trained model的訓練數據相比而言)
在這種情況下,因為數據與預訓練模型的訓練數據相似度很高,因此我們不需要重新訓練模型。我們只需要將輸出層改制成符合問題情境下的結構就好。
我們使用預處理模型作為模式提取器。
比如說我們使用在ImageNet上訓練的模型來辨認一組新照片中的小貓小狗。在這里,需要被辨認的圖片與ImageNet庫中的圖片類似,但是我們的輸出結果中只需要兩項——貓或者狗。
在這個例子中,我們需要做的就是把dense layer和最終softmax layer的輸出從1000個類別改為2個類別。
場景二:數據集小,數據相似度不高
在這種情況下,我們可以凍結預訓練模型中的前k個層中的權重,然后重新訓練后面的n-k個層,當然最后一層也需要根據相應的輸出格式來進行修改。
因為數據的相似度不高,重新訓練的過程就變得非常關鍵。而新數據集大小的不足,則是通過凍結預訓練模型的前k層進行彌補。
場景三:數據集大,數據相似度不高
在這種情況下,因為我們有一個很大的數據集,所以神經網絡的訓練過程將會比較有效率。然而,因為實際數據與預訓練模型的訓練數據之間存在很大差異,采用預訓練模型將不會是一種高效的方式。
因此最好的方法還是將預處理模型中的權重全都初始化后在新數據集的基礎上重頭開始訓練。
場景四:數據集大,數據相似度高
這就是最理想的情況,采用預訓練模型會變得非常高效。最好的運用方式是保持模型原有的結構和初始權重不變,隨后在新數據集的基礎上重新訓練。
去模型訓練要消耗更多資源,也是 我目前的設備所不能支持的。所以在這段時間里面,主要 做的就是遷移學習,這一點是新的課題。
7、使用vgg16作為預訓練的模型結構,並把它應用到手寫數字識別上
對於imagenet來說,mnist顯而易見屬於小數據,所以是1/2類的。分別來看一下
凍結凍結部分參數
import numpy as np
from keras.datasets import mnist
import gc
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.applications.vgg16 import VGG16
from keras.optimizers import SGD
import cv2
import h5py as h5py
import numpy as np
def tran_y(y) :
y_ohe = np.zeros( 10)
y_ohe[y] = 1
return y_ohe
# 如果硬件配置較高,比如主機具備32GB以上內存,GPU具備8GB以上顯存,可以適當增大這個值。VGG要求至少48像素
ishape = 48
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_train]
X_train = np.concatenate([arr[np.newaxis] for arr in X_train]).astype( 'float32')
X_train /= 255. 0
X_test = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_test]
X_test = np.concatenate([arr[np.newaxis] for arr in X_test]).astype( 'float32')
X_test /= 255. 0
y_train_ohe = np. array([tran_y(y_train[i]) for i in range( len(y_train))])
y_test_ohe = np. array([tran_y(y_test[i]) for i in range( len(y_test))])
y_train_ohe = y_train_ohe.astype( 'float32')
y_test_ohe = y_test_ohe.astype( 'float32')
model_vgg = VGG16(include_top = False, weights = 'imagenet', input_shape = (ishape, ishape, 3))
#for i, layer in enumerate(model_vgg.layers):
# if i<20:
for layer in model_vgg.layers :
layer.trainable = False
model = Flatten()(model_vgg.output)
model = Dense( 4096, activation = 'relu', name = 'fc1')(model)
model = Dense( 4096, activation = 'relu', name = 'fc2')(model)
model = Dropout( 0. 5)(model)
model = Dense( 10, activation = 'softmax', name = 'prediction')(model)
model_vgg_mnist_pretrain = Model(model_vgg. input, model, name = 'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd = SGD(lr = 0. 05, decay = 1e - 5)
model_vgg_mnist_pretrain. compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = [ 'accuracy'])
model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data = (X_test, y_test_ohe), epochs = 10, batch_size = 64)
#del(model_vgg_mnist_pretrain, model_vgg, model)
for i in range( 100) :
gc.collect() _________________________________________________________________
from keras.datasets import mnist
import gc
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.applications.vgg16 import VGG16
from keras.optimizers import SGD
import cv2
import h5py as h5py
import numpy as np
def tran_y(y) :
y_ohe = np.zeros( 10)
y_ohe[y] = 1
return y_ohe
# 如果硬件配置較高,比如主機具備32GB以上內存,GPU具備8GB以上顯存,可以適當增大這個值。VGG要求至少48像素
ishape = 48
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_train]
X_train = np.concatenate([arr[np.newaxis] for arr in X_train]).astype( 'float32')
X_train /= 255. 0
X_test = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_test]
X_test = np.concatenate([arr[np.newaxis] for arr in X_test]).astype( 'float32')
X_test /= 255. 0
y_train_ohe = np. array([tran_y(y_train[i]) for i in range( len(y_train))])
y_test_ohe = np. array([tran_y(y_test[i]) for i in range( len(y_test))])
y_train_ohe = y_train_ohe.astype( 'float32')
y_test_ohe = y_test_ohe.astype( 'float32')
model_vgg = VGG16(include_top = False, weights = 'imagenet', input_shape = (ishape, ishape, 3))
#for i, layer in enumerate(model_vgg.layers):
# if i<20:
for layer in model_vgg.layers :
layer.trainable = False
model = Flatten()(model_vgg.output)
model = Dense( 4096, activation = 'relu', name = 'fc1')(model)
model = Dense( 4096, activation = 'relu', name = 'fc2')(model)
model = Dropout( 0. 5)(model)
model = Dense( 10, activation = 'softmax', name = 'prediction')(model)
model_vgg_mnist_pretrain = Model(model_vgg. input, model, name = 'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd = SGD(lr = 0. 05, decay = 1e - 5)
model_vgg_mnist_pretrain. compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = [ 'accuracy'])
model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data = (X_test, y_test_ohe), epochs = 10, batch_size = 64)
#del(model_vgg_mnist_pretrain, model_vgg, model)
for i in range( 100) :
gc.collect() _________________________________________________________________
某種程度上,這段代碼就是語法正確、資源消耗不是非常大的基於vgg的遷移學習算法。那么基於此作一些實驗
修改了一下,添加更多內容,主要是數據顯示這塊import numpy as np
from keras.datasets
import mnist
import gc
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.applications.vgg16 import VGG16
from keras.optimizers import SGD
import matplotlib.pyplot as plt
import os
import cv2
import h5py as h5py
import numpy as np
def tran_y(y) :
y_ohe = np.zeros( 10)
y_ohe[y] = 1
return y_ohe
# 如果硬件配置較高,比如主機具備32GB以上內存,GPU具備8GB以上顯存,可以適當增大這個值。VGG要求至少48像素
ishape = 48
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_train]
X_train = np.concatenate([arr[np.newaxis] for arr in X_train]).astype( 'float32')
X_train /= 255. 0
X_test = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_test]
X_test = np.concatenate([arr[np.newaxis] for arr in X_test]).astype( 'float32')
X_test /= 255. 0
y_train_ohe = np. array([tran_y(y_train[i]) for i in range( len(y_train))])
y_test_ohe = np. array([tran_y(y_test[i]) for i in range( len(y_test))])
y_train_ohe = y_train_ohe.astype( 'float32')
y_test_ohe = y_test_ohe.astype( 'float32')
model_vgg = VGG16(include_top = False, weights = 'imagenet', input_shape = (ishape, ishape, 3))
for layer in model_vgg.layers :
layer.trainable = False
model = Flatten()(model_vgg.output)
model = Dense( 4096, activation = 'relu', name = 'fc1')(model)
model = Dense( 4096, activation = 'relu', name = 'fc2')(model)
model = Dropout( 0. 5)(model)
model = Dense( 10, activation = 'softmax', name = 'prediction')(model)
model_vgg_mnist_pretrain = Model(model_vgg. input, model, name = 'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd = SGD(lr = 0. 05, decay = 1e - 5)
model_vgg_mnist_pretrain. compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = [ 'accuracy'])
log = model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data = (X_test, y_test_ohe), epochs = 10, batch_size = 64)
score = model_vgg_mnist_pretrain.evaluate(x_test, y_test, verbose = 0)
print( 'Test loss:', score[ 0])
print( 'Test accuracy:', score[ 1])
plt.figure( 'acc')
plt.subplot( 2, 1, 1)
plt.plot(log.history[ 'acc'], 'r--',label = 'Training Accuracy')
plt.plot(log.history[ 'val_acc'], 'r-',label = 'Validation Accuracy')
plt.legend(loc = 'best')
plt.xlabel( 'Epochs')
plt.axis([ 0, epochs, 0. 9, 1])
plt.figure( 'loss')
plt.subplot( 2, 1, 2)
plt.plot(log.history[ 'loss'], 'b--',label = 'Training Loss')
plt.plot(log.history[ 'val_loss'], 'b-',label = 'Validation Loss')
plt.legend(loc = 'best')
plt.xlabel( 'Epochs')
plt.axis([ 0, epochs, 0, 1])
plt.show()
os.system( "pause")
import gc
from keras.models import Sequential, Model
from keras.layers import Input, Dense, Dropout, Flatten
from keras.layers.convolutional import Conv2D, MaxPooling2D
from keras.applications.vgg16 import VGG16
from keras.optimizers import SGD
import matplotlib.pyplot as plt
import os
import cv2
import h5py as h5py
import numpy as np
def tran_y(y) :
y_ohe = np.zeros( 10)
y_ohe[y] = 1
return y_ohe
# 如果硬件配置較高,比如主機具備32GB以上內存,GPU具備8GB以上顯存,可以適當增大這個值。VGG要求至少48像素
ishape = 48
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_train]
X_train = np.concatenate([arr[np.newaxis] for arr in X_train]).astype( 'float32')
X_train /= 255. 0
X_test = [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR) for i in X_test]
X_test = np.concatenate([arr[np.newaxis] for arr in X_test]).astype( 'float32')
X_test /= 255. 0
y_train_ohe = np. array([tran_y(y_train[i]) for i in range( len(y_train))])
y_test_ohe = np. array([tran_y(y_test[i]) for i in range( len(y_test))])
y_train_ohe = y_train_ohe.astype( 'float32')
y_test_ohe = y_test_ohe.astype( 'float32')
model_vgg = VGG16(include_top = False, weights = 'imagenet', input_shape = (ishape, ishape, 3))
for layer in model_vgg.layers :
layer.trainable = False
model = Flatten()(model_vgg.output)
model = Dense( 4096, activation = 'relu', name = 'fc1')(model)
model = Dense( 4096, activation = 'relu', name = 'fc2')(model)
model = Dropout( 0. 5)(model)
model = Dense( 10, activation = 'softmax', name = 'prediction')(model)
model_vgg_mnist_pretrain = Model(model_vgg. input, model, name = 'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd = SGD(lr = 0. 05, decay = 1e - 5)
model_vgg_mnist_pretrain. compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = [ 'accuracy'])
log = model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data = (X_test, y_test_ohe), epochs = 10, batch_size = 64)
score = model_vgg_mnist_pretrain.evaluate(x_test, y_test, verbose = 0)
print( 'Test loss:', score[ 0])
print( 'Test accuracy:', score[ 1])
plt.figure( 'acc')
plt.subplot( 2, 1, 1)
plt.plot(log.history[ 'acc'], 'r--',label = 'Training Accuracy')
plt.plot(log.history[ 'val_acc'], 'r-',label = 'Validation Accuracy')
plt.legend(loc = 'best')
plt.xlabel( 'Epochs')
plt.axis([ 0, epochs, 0. 9, 1])
plt.figure( 'loss')
plt.subplot( 2, 1, 2)
plt.plot(log.history[ 'loss'], 'b--',label = 'Training Loss')
plt.plot(log.history[ 'val_loss'], 'b-',label = 'Validation Loss')
plt.legend(loc = 'best')
plt.xlabel( 'Epochs')
plt.axis([ 0, epochs, 0, 1])
plt.show()
os.system( "pause")
在實際操作 的過程中,非常注意可能出現。這也證明如果自己配置機器,內存至少要32GB.