最近開始打ctf了,發現好多sql注入都忘了,最近要好好復習一下。
基礎知識:
floor(): 返回<=某數的最大整數 rand(): 產生隨機數 rand(x): 每個x對應一個固定的值,但是如果連續執行多次值會變化,不過也是可預測的 floor報錯payload: select count(*), floor(rand(0)*2) as a from information_schema.tables group by a;原理:
這個payload的重點在group by a,也就是group by floor(rand(0)*2)。首先,floor(rand(0)*2)的意思是隨機產生0或1。雖說是隨機,但是它是有規律可循的。看看上面解釋的rand(x),對於rand(0)而言,雖說是隨機數,但是它的值與執行rand(0)的次數是意義對應的,即每一次執行rand(0)得到的結果都是固定的。基本是011011...這個序列。 那它為什么會報錯呢?先來解釋一下count(*)與group by是如何共同工作的。首先,系統會建立一個虛擬表: 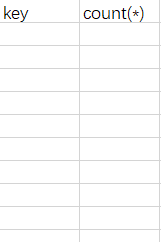假設有表:

執行count(*) from ... group by age的過程中,會形成這樣的虛擬表:

它是如何一步步形成這張表的呢?看上上圖。由於group by的是age,第一次讀取的就是18,在虛擬表中尋找是否已經存在18,由於表是空的,直接插入一條新數據,這時虛擬表變成這樣:

繼續。下一個是19,由於虛擬表中依舊沒有key為19的字段,故插入。再下一個是20,繼續插入。再下一個又是20。由於已經有了20,故將key為20的字段的count(*)的值加1,變為了2。剩下的以此類推,最后形成了這個虛擬表:

好了,現在group by原理講完了。那究竟是如何將其與floor聯合起來,進行floor報錯呢?
先來回顧一下payload: select count(), floor(rand(0)2) as a from information_schema.tables group by a;
總體是一個group by語句,只不過這里group by的是floor(rand(0)2)。這是一個表達式,每次運算的值都是隨機的。還記得我剛剛說的floor(rand(0)2)的值序列開頭是011011...吧?ok,下面開始運算。
首先,建立一張虛擬表:

接着,進行group by floor(rand(0)2)。floor表達式第一次運算的值為0,在表中沒有找到key為0的數據,故插入,在插入的過程中需要再取一次group by后面的值(即再進行一次floor運算,結果為1),取到了1,將之插入,並將count()置1。

繼續,再進行group by floor(rand(0)2)。進行floor表達式運算,由於這是第三次運算了,故值為1。剛好表中有了key為1的數據,故直接將其對應的count()加1即可。

繼續進行group by。這是第四次floor運算了,根據剛剛那個011011序列,這次的值為0,在表中找是否有key為0的數據。當然沒有,故應當插入一條新記錄。在插入時進行floor運算(就像第一次group by那樣),這時的值為1,並將count(*)置1。可是你會說,虛擬表中已經有了key為1的數據了啊。對,這就是問題所在了。此時就會拋出主鍵冗余的異常,也就是所謂的floor報錯。
利用:select count(), concat((select database()), '-', floor(rand(0)2)) as a from information_schema.tables group by a; #將select database()換成你想要的東西!~