模型的優化目標如下:
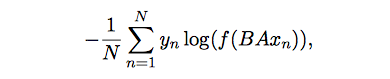

與Word2Vec的區別:
相似的地方:
- 圖模型結構很像,都是采用embedding向量的形式,得到word的隱向量表達。
- 都采用很多相似的優化方法,比如使用Hierarchical softmax優化訓練和預測中的打分速度。
不同的地方:
- word2vec是一個無監督算法,而fasttext是一個有監督算法。word2vec的學習目標是skip的word,而fasttext的學習目標是人工標注的分類結果。
word2vec treats each word in corpus like an atomic entity and generates a vector for each word(word2vec中每個Word對應一個詞向量,fasttext中每個Word可以產生多個character字符ngrams,每個ngram對應一個詞向量,word的詞向量是所有ngrams的詞向量的和,需要指定ngrams的長度范圍). Fasttext (which is essentially an extension of word2vec model), treats each word as composed of character ngrams. So the vector for a word is made of the sum of this character n grams. For example the word vector “apple” is a sum of the vectors of the n-grams “<ap”, “app”, ”appl”, ”apple”, ”apple>”, “ppl”, “pple”, ”pple>”, “ple”, ”ple>”, ”le>” (assuming hyperparameters for smallest ngram[minn] is 3 and largest ngram[maxn] is 6). This difference manifests as follows.
- Generate better word embeddings for rare words ( even if words are rare their character n grams are still shared with other words - hence the embeddings can still be good).
- Out of vocabulary words(即使不在訓練集語料中的Word也能得到詞向量) - they can construct the vector for a word from its character n grams even if word doesn't appear in training corpus.
- From a practical usage standpoint, the choice of hyperparamters for generating fasttext embeddings becomes key:since the training is at character n-gram level, it takes longer to generate fasttext embeddings compared to word2vec - the choice of hyper parameters controlling the minimum and maximum n-gram sizes has a direct bearing on this time.
- The usage of character embeddings (individual characters as opposed to n-grams) for downstream tasks have recently shown to boost the performance of those tasks compared to using word embeddings like word2vec or Glove.
https://heleifz.github.io/14732610572844.html
https://arxiv.org/pdf/1607.04606v1.pdf
http://www.jianshu.com/p/b7ede4e842f1
https://www.quora.com/What-is-the-main-difference-between-word2vec-and-fastText