轉載請注明出處:http://www.cnblogs.com/willnote/p/6912798.html
前言
深度學習的基本原理是基於人工神經網絡,信號從一個神經元進入,經過非線性的激活函數,傳入到下一層神經元;再經過該層神經元的激活,繼續往下傳遞,如此循環往復,直到輸出層。正是由於這些非線性函數的反復疊加,才使得神經網絡有足夠的能力來抓取復雜的模式,在各個領域取得不俗的表現。顯而易見,激活函數在深度學習中舉足輕重,也是很活躍的研究領域之一。目前來講,選擇怎樣的激活函數不在於它能否模擬真正的神經元,而在於能否便於優化整個深度神經網絡。
本文首先着重對Sigmoid函數的特點與其存在的梯度消失問題進行說明,之后再對其他常用的一些激活函數的特點進行對比介紹。
Sigmoid函數
Sigmoid函數是深度學習領域開始時使用頻率最高的激活函數。
函數形式
\[\sigma (x)=\frac{1}{1+e^{-x}} \]

梯度消失
- 梯度消失問題
首先,我們將一個使用Sigmoid作為激活函數的網絡,在初始化后的訓練初期結果進行可視化如下:
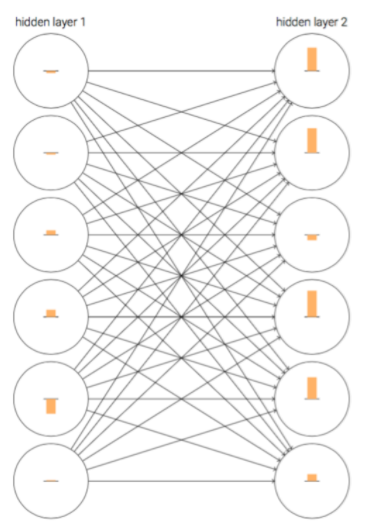
在上圖中,神經元上的橙色柱條可以理解為神經元的學習速率。雖然這個網絡是經過隨機初始化的,但是從上圖不難發現,第二層神經元上的柱條都要大於第一層對應神經元上的柱條,即第二層神經元的學習速率大於第一層神經元學習速率。那這可不可能是個巧合呢?其實不是的,Nielsen在《Neural Networks and Deep Learning》中通過實驗說明了這種現象是普遍存在的。
接下來我們再來看下對於一個具有四個隱層的神經網絡,各隱藏層的學習速率曲線如下:
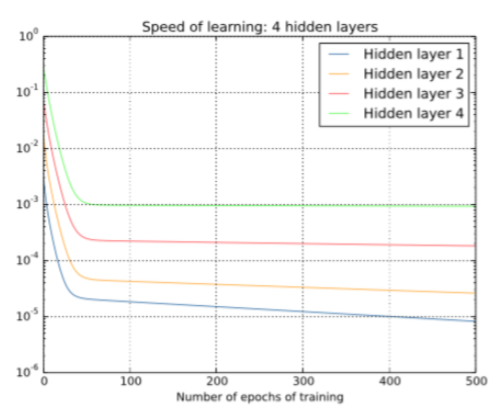
可以看出,第一層的學習速度和最后一層要差兩個數量級,也就是比第四層慢了100倍。 實際上,這個問題是可以避免的,盡管替代方法並不是那么有效,同樣會產生問題——在前面的層中的梯度會變得非常大!這也叫做梯度激增(exploding gradient problem),這也沒有比梯度消散問題更好處理。
更加一般地說,在深度神經網絡中的梯度是不穩定的,在前面的層中或會消失,或會激增,這種不穩定性才是深度神經網絡中基於梯度學習的根本原因。
- 梯度消散的產生原因
為了弄清楚為何會出現梯度消散問題,來看看一個簡單的深度神經網絡:每一層都只有一個單一的神經元。下面就是有三層隱藏層的神經網絡:

我們把梯度的整個表達式寫出來: $$\frac{\partial C }{\partial b_{1}}=\sigma^{'} (z_{1})w_{2}\sigma^{'} (z_{2})w_{3}\sigma^{'} (z_{3})w_{4}\sigma^{'} (z_{4})\frac{\partial C }{\partial a_{4}}$$ 我們再來看一下Sigmoid函數導數的曲線:
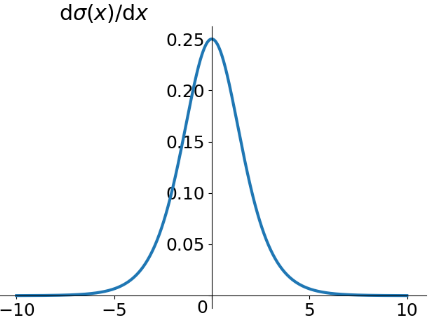
該導數在$\sigma^{'} (0)=\frac{1}{4}$時達到最高。現在,如果我們使用標准方法來初始化網絡中的權重,那么會使用一個均值為0標准差為1的高斯分布。因此所有的權重通常會滿足$|w_{j}|<1$。有了這些信息,我們發現會有$w_{j}\sigma^{'} (z_{j})<\frac{1}{4}$,並且在進行所有這些項的乘積時,最終結果肯定會指數級下降:項越多,乘積的下降也就越快。 下面我們從公式上比較一下第三層和第一層神經元的學習速率:

比較一下$\frac{\partial C }{\partial b_{1}}$和$\frac{\partial C }{\partial b_{3}}$可知,$\frac{\partial C }{\partial b_{1}}$要遠遠小於$\frac{\partial C }{\partial b_{3}}$。**因此,梯度消失的本質原因是:$w_{j}\sigma^{'} (z_{j})<\frac{1}{4}$的約束。**梯度激增問題:網絡的權重設置的比較大且偏置使得$\sigma^{'} (z_{j})$項不會太小。
- 不穩定的梯度問題
根本的問題其實並非是梯度消失問題或者梯度激增問題,而是在前面的層上的梯度是來自后面的層上項的乘積。當存在過多的層次時,就出現了內在本質上的不穩定場景。唯一讓所有層都接近相同的學習速度的方式是所有這些項的乘積都能得到一種平衡。如果沒有某種機制或者更加本質的保證來達成平衡,那網絡就很容易不穩定了。簡而言之,真實的問題就是神經網絡受限於不穩定梯度的問題。所以,如果我們使用標准的基於梯度的學習算法,在網絡中的不同層會出現按照不同學習速度學習的情況。
zero-centered
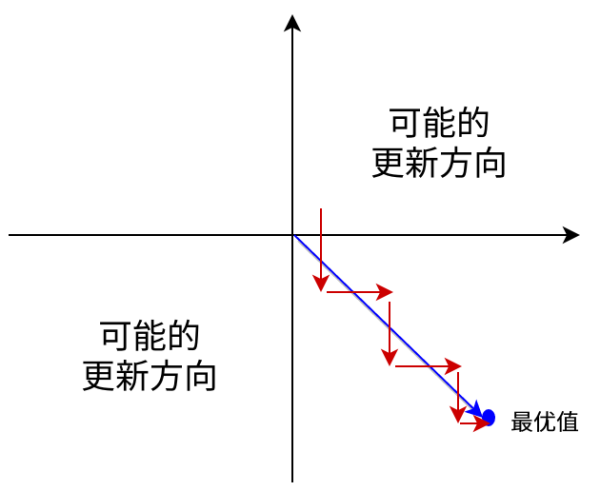
Sigmoid函數的輸出值恆大於0,這會導致模型訓練的收斂速度變慢。舉例來講,對\(\sigma (\sum w_{i}x{i}+b)\),如果所有\(x_{i}\)均為正數或負數,那么其對\(w_{i}\)的導數總是正數或負數,這會導致如下圖紅色箭頭所示的階梯式更新,這顯然並非一個好的優化路徑。深度學習往往需要大量時間來處理大量數據,模型的收斂速度是尤為重要的。所以,總體上來講,訓練深度學習網絡盡量使用zero-centered數據 (可以經過數據預處理實現) 和zero-centered輸出。
運算時耗
相對於前兩項,這其實並不是一個大問題,我們目前是具備相應計算能力的,但面對深度學習中龐大的計算量,最好是能省則省。之后我們會看到,在ReLU函數中,需要做的僅僅是一個thresholding,相對於冪運算來講會快很多。
tanh函數
tanh函數即雙曲正切函數(hyperbolic tangent)。
函數形式
\[tanh x=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} \]

評價
- 優點
解決了zero-centered的輸出問題。
- 缺點
梯度消失的問題和冪運算的問題仍然存在。
ReLU函數
ReLU函數(Rectified Linear Units)其實就是一個取最大值函數,注意這並不是全區間可導的,但是我們可以取次梯度(subgradient)。
函數形式
\[ReLU=max(0, x) \]
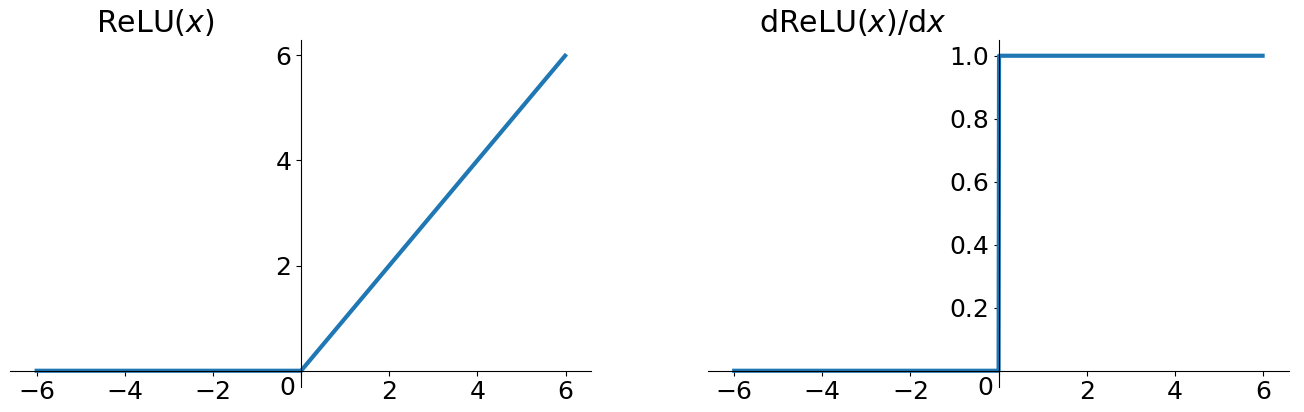
評價
- 優點
- 解決了梯度消失的問題 (在正區間)
- 計算速度非常快,只需要判斷輸入是否大於0
- 收斂速度遠快於sigmoid和tanh
- 缺點
- 輸出不是zero-centered
- Dead ReLU Problem
Dead ReLU Problem指的是某些神經元可能永遠不會被激活,導致相應的參數永遠不能被更新。有兩個主要原因可能導致這種情況產生: (1) 非常不幸的參數初始化,這種情況比較少見 (2) 學習速率太高導致在訓練過程中參數更新太大,不幸使網絡進入這種狀態。解決方法是可以采用Xavier初始化方法,以及避免將學習速率設置太大或使用adagrad等自動調節學習速率的算法。
盡管存在這兩個問題,ReLU目前仍是最常用的激活函數,在搭建神經網絡的時候推薦優先嘗試!
Leaky ReLU函數
為了解決ReLU函數的Dead ReLU Problem而提出的激活函數。
函數形式
\[f(x)=max(0.01x, x) \]
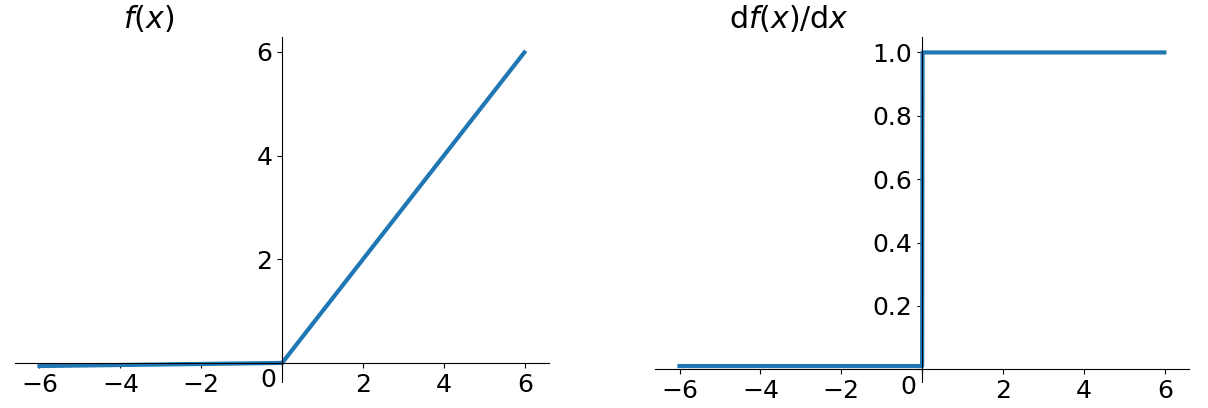
評價
為了解決Dead ReLU Problem,Leaky ReLU提出了將ReLU的前半段設為\(0.01x\)而非0。另外一種直觀的想法是基於參數的方法,即Parametric ReLU:
\[f(x)=max(\alpha x, x) \]
其中\(\alpha\)可由back propagation學出來。理論上來講,Leaky ReLU有ReLU的所有優點,外加不會有Dead ReLU問題,但是在實際操作當中,並沒有完全證明Leaky ReLU總是好於ReLU。
ELU函數
ELU(Exponential Linear Units)函數也是為了解決ReLU存在的問題而提出的激活函數。
函數形式
\[\left\{\begin{matrix}x,\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if\ x>0 \\ \alpha(e^{x}-1),\ \ \ \ \ \ otherwise \end{matrix}\right. \]
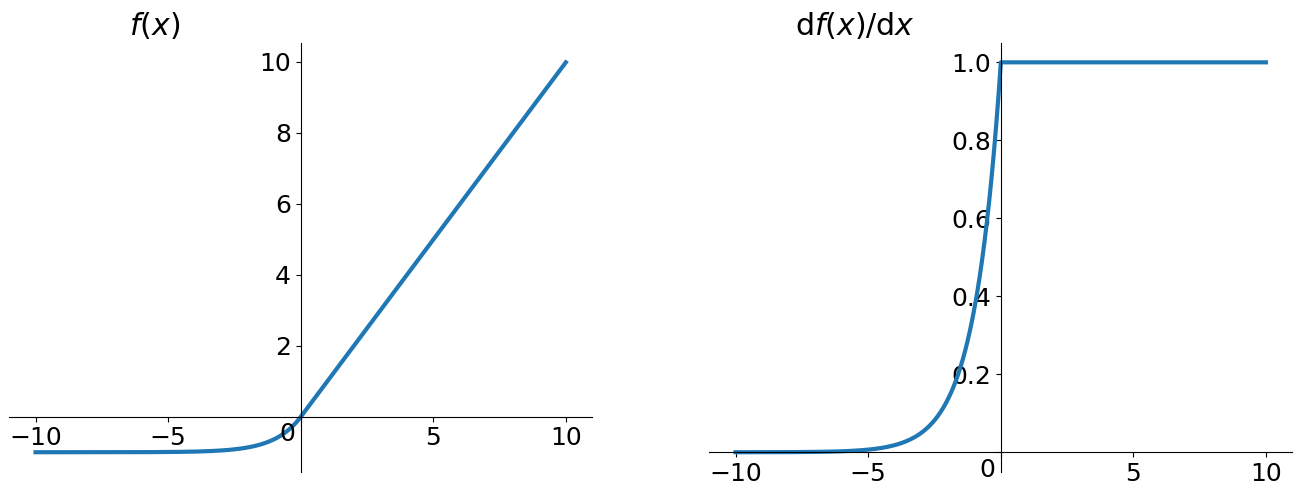
評價
ELU也是為解決ReLU存在的問題而提出,顯然,ELU有ReLU的基本所有優點,以及:
- 不會有Dead ReLU問題
- 輸出的均值接近0,zero-centered
它的一個小問題在於計算量稍大。類似於Leaky ReLU,理論上雖然好於ReLU,但在實際使用中目前並沒有好的證據ELU總是優於ReLU。
參考
- 深度學習中消失的梯度
- 聊一聊深度學習的activation function