保證系統能穩定地運行在生產環境是第一要務,就算是服務質量下降,只要仍在工作,那就是萬幸。
常見服務問題
-
服務超時
依賴的第三方服務因為某種不可抗力超時了?數據庫慢查詢拖垮了整個數據庫? -
服務錯誤
某個服務掛了? -
服務負載高
突然陡增的訪問量?
解決方法
-
限時
針對服務超時,可以通過超時控制保證接口的返回,可以通過設置超時時間為1s,盡快返回結果,因為大多數情況下,接口超時一方面影響用戶體驗,一方面可能是由於后端依賴出現了問題,如負載過高,機器故障等。某個互聯網公司曾經說,當系統故障時,fail fast。 -
fallback
有些情況下,即使服務出錯,對用戶而言,也希望是透明的,無感的,設置一些fallback,做一些服務降級,保證用戶的體驗,即使這個服務實際上是掛掉的,返回內容是空的或者是舊的,在此故障期間,程序員能趕緊修復,對用戶幾乎沒有造成不良體驗。 -
電路熔斷
這里的電路熔斷是對於后端服務的保護,當錯誤、超時、負載上升到一定的高度,那么負載再高下去,對后端來說肯定是無法承受,好像和電路熔斷一樣,這三個因素超過了閾值,客戶端就可以停止對后端服務的調用,這個保護的措施,幫助了運維人員能迅速通過增加機器和優化系統,幫助系統度過難關。
工具
Hystrix能保護客戶端,服務降級,它的dashboard上有一句標語,defend your app,確實,當后端程序能對異常,超時,錯誤等進行處理,那么客戶端能獲得的數據能更加穩定統一,同時它也是對后端服務的保護,hystrix有上述的電路熔斷機制和用戶可以自定義fallback,對服務限時等功能。
hystrix運行流程可見How it works
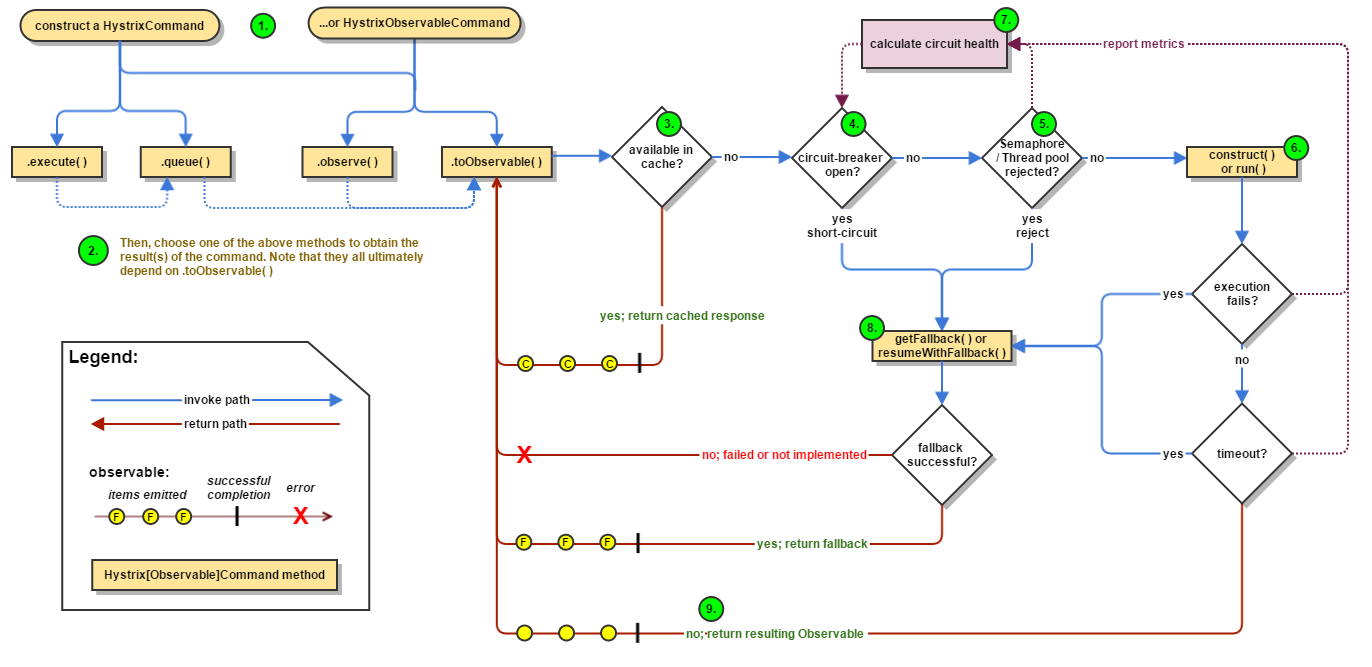
以構建一個對內部RPC調用的HystrixCommand為例:
- 構建一個HystrixCommand用於RPC調用,設置超時時間為1s,fallback為返回空數據
- 如果緩存打開,結果優先從緩存中獲取
- 如果電路被熔斷,嘗試fallback
- 如果並發量超過限制,嘗試fallback
- 不然,運行實際的RPC調用,如果調用失敗或者超時,嘗試fallback
根據實際情況設置
hystrix的超時時間,fallback,並發量都可以根據需要封裝的指令進行設置,可以說非常靈活,根據自己的具體業務進行合適的設置,能優化用戶體驗。
例如:文章列表API依賴的服務超時,可以通過服務降級拉取緩存中的舊數據進行返回,雖然即時性稍遜,但是起碼用戶能讀到幾分鍾前的文章,在此期間,趕緊修復問題。