源文件放在github,隨着理解的深入,不斷更新,如有謬誤之處,歡迎指正。原文鏈接https://github.com/jacksu/utils4s/blob/master/spark-knowledge/md/spark_streaming使用kafka保證數據零丟失.md
spark streaming從1.2開始提供了數據的零丟失,想享受這個特性,需要滿足如下條件:
1.數據輸入需要可靠的sources和可靠的receivers
2.應用metadata必須通過應用driver checkpoint
3.WAL(write ahead log)
可靠的sources和receivers
spark streaming可以通過多種方式作為數據sources(包括kafka),輸入數據通過receivers接收,通過replication存儲於spark中(為了faultolerance,默認復制到兩個spark executors),如果數據復制完成,receivers可以知道(例如kafka中更新offsets到zookeeper中)。這樣當receivers在接收數據過程中crash掉,不會有數據丟失,receivers沒有復制的數據,當receiver恢復后重新接收。

metadata checkpoint
可靠的sources和receivers,可以使數據在receivers失敗后恢復,然而在driver失敗后恢復是比較復雜的,一種方法是通過checkpoint metadata到HDFS或者S3。metadata包括:
- configuration
- code
- 一些排隊等待處理但沒有完成的RDD(僅僅是metadata,而不是data)
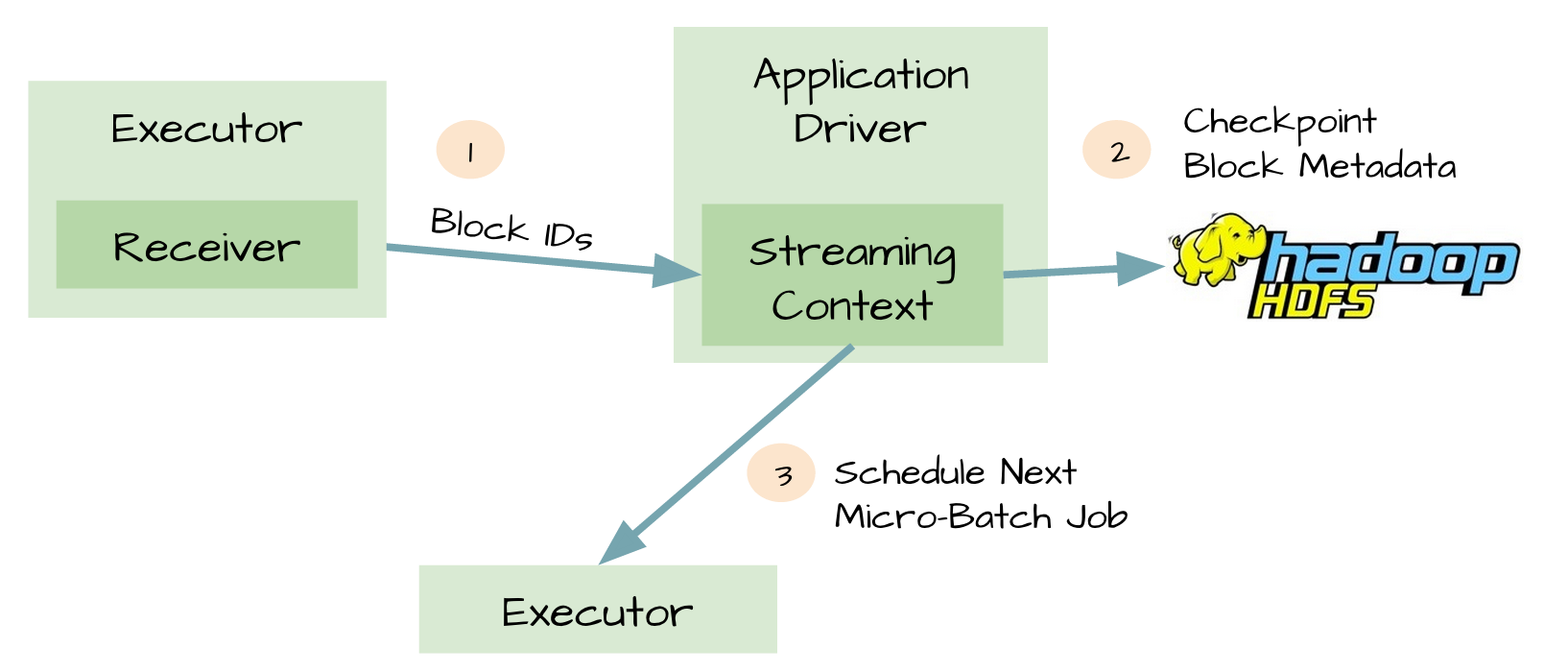
這樣當driver失敗時,可以通過metadata checkpoint,重構應用程序並知道執行到那個地方。
數據可能丟失的場景
可靠的sources和receivers,以及metadata checkpoint也不可以保證數據的不丟失,例如:
- 兩個executor得到計算數據,並保存在他們的內存中
- receivers知道數據已經輸入
- executors開始計算數據
- driver突然失敗
- driver失敗,那么executors都會被kill掉
- 因為executor被kill掉,那么他們內存中得數據都會丟失,但是這些數據不再被處理
- executor中的數據不可恢復
WAL
為了避免上面情景的出現,spark streaming 1.2引入了WAL。所有接收的數據通過receivers寫入HDFS或者S3中checkpoint目錄,這樣當driver失敗后,executor中數據丟失后,可以通過checkpoint恢復。
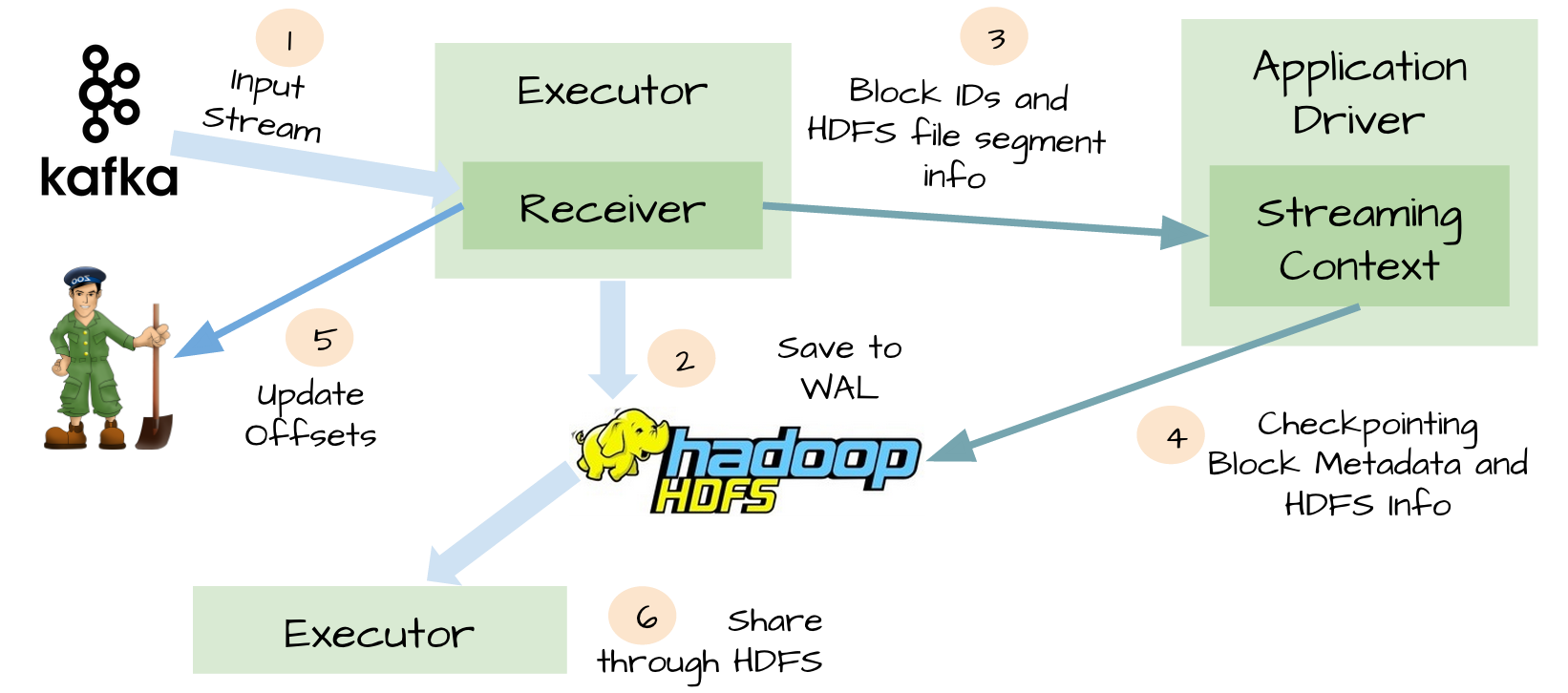
At-Least-Once
盡管WAL可以保證數據零丟失,但是不能保證exactly-once,例如下面場景:
-
Receivers接收完數據並保存到HDFS或S3
-
在更新offset前,receivers失敗了
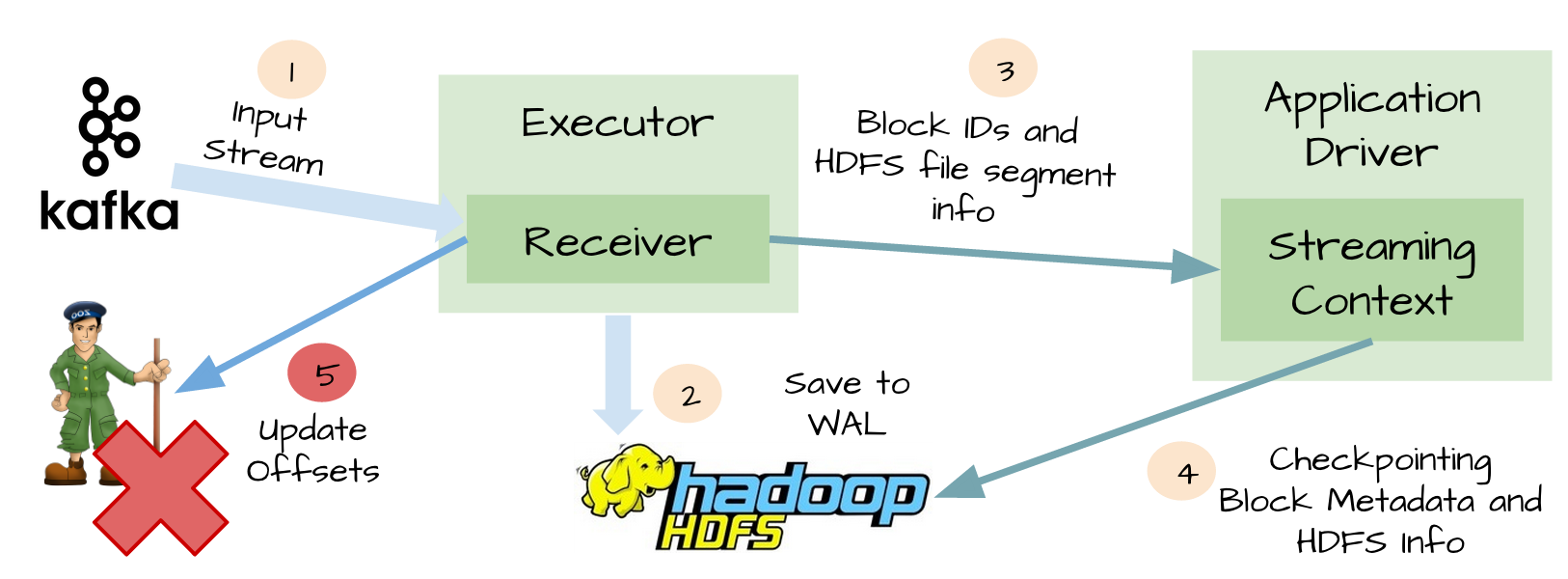
-
Spark Streaming以為數據接收成功,但是Kafka以為數據沒有接收成功,因為offset沒有更新到zookeeper
-
隨后receiver恢復了
-
從WAL可以讀取的數據重新消費一次,因為使用的kafka High-Level消費API,從zookeeper中保存的offsets開始消費
WAL的缺點
通過上面描述,WAL有兩個缺點:
- 降低了receivers的性能,因為數據還要存儲到HDFS等分布式文件系統
- 對於一些resources,可能存在重復的數據,比如Kafka,在Kafka中存在一份數據,在Spark Streaming也存在一份(以WAL的形式存儲在hadoop API兼容的文件系統中)
Kafka direct API
為了WAL的性能損失和exactly-once,spark streaming1.3中使用Kafka direct API。非常巧妙,Spark driver計算下個batch的offsets,指導executor消費對應的topics和partitions。消費Kafka消息,就像消費文件系統文件一樣。
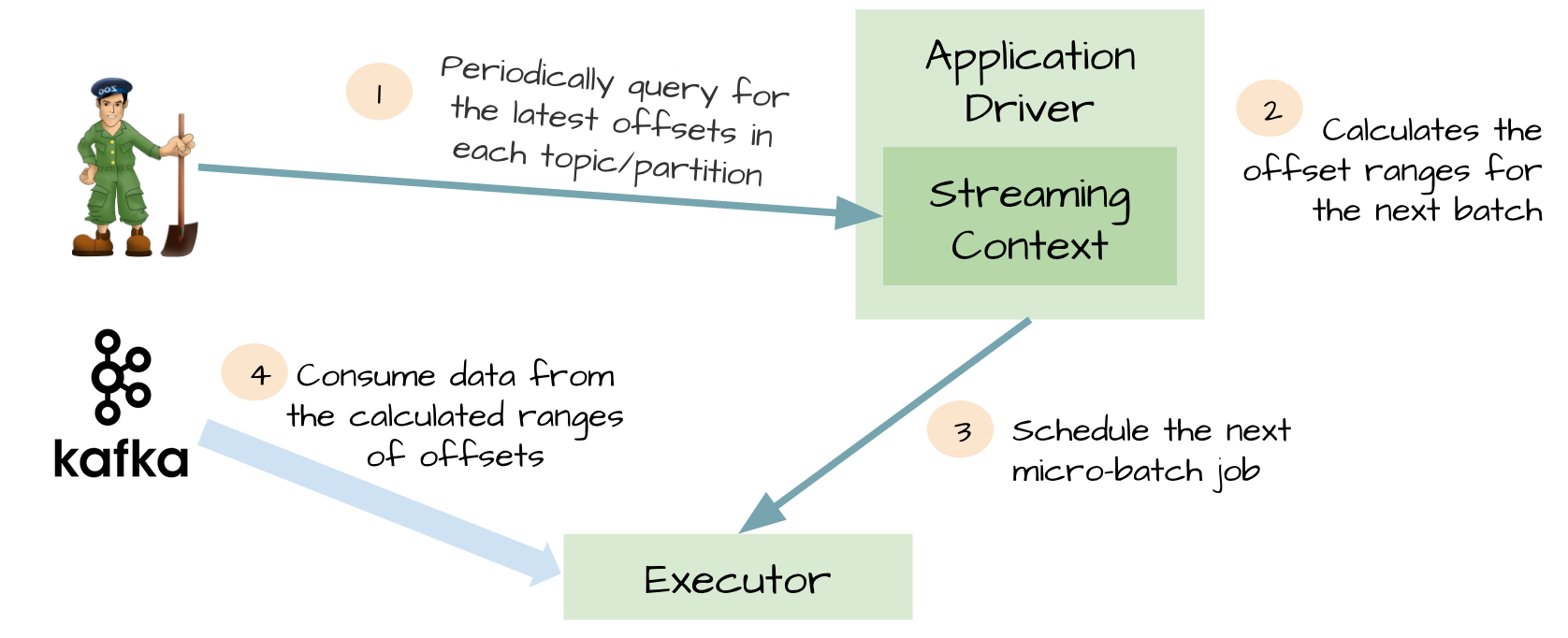
1.不再需要kafka receivers,executor直接通過Kafka API消費數據
2.WAL不再需要,如果從失敗恢復,可以重新消費
3.exactly-once得到了保證,不會再從WAL中重復讀取數據
總結
主要說的是spark streaming通過各種方式來保證數據不丟失,並保證exactly-once,每個版本都是spark streaming越來越穩定,越來越向生產環境使用發展。
參考
spark-streaming
Recent Evolution of Zero Data Loss Guarantee in Spark Streaming With Kafka