整兩天再看調優分析的部分,發現實際運行環境下,還是要考慮配置垃圾回收器,所以這里就加一小章介紹一下。
首先來看一下HotSpot所支持回收期的關系圖:
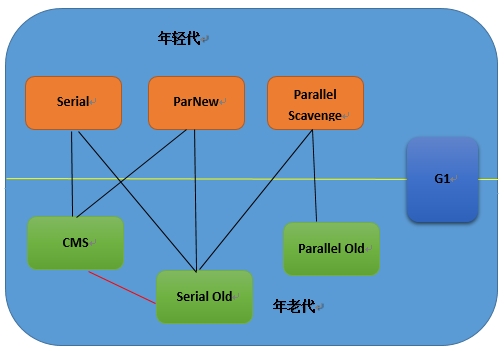
圖中可以看到一共有7中垃圾回收器,以中間綠線為界,上邊三個用於年輕代,下邊三個用在年老代,而G1則老少通吃,黑線線表示兩個回收器可搭配使用,紅線則表示兩者可以在同一區域交替使用。由於G1在JDK1.7才達到商用級別,而且目前線上環境也很少使用,在此不再介紹。下面我們來介紹一下其他六種:
Serial:從名字就能看出是串行的意思,該回收器是最早實現的,基於單線程,實現簡單且效率高,但是進行垃圾回收是會造成“Stop-the-World”(STW),當回收內存區域較大時,就會造成程序響應時間變長。
ParNew:全名Parallel New Generation,也就是並行新生代垃圾回收期,該回收器實現與Serial基本上一樣,只是采用多線程執行回收。
Parallel Scavenge:並行清理,也就是並行垃圾回收器。該回收器與ParNew的最大區別在於ParNew通常與CMS搭配,一般注重於減少垃圾回收的停頓時間,提高響應速度,而Parallel Scavenge則側重於吞吐量的控制,又名"吞吐量優先"回收器(吞吐量 = 運行用戶代碼時間 /(運行用戶代碼時間 + 垃圾收集時間);響應時間影響用戶體驗,而吞吐量則影響CPU利用率,進而影響程序程序運算效率)。此外需注意,該回收器不能夠和CMS搭配使用。
CMS:Concurrent Mark Sweep,是一個並發回收器,旨在減少垃圾回收的停頓時間。我們可以從其處理過程分析一下:
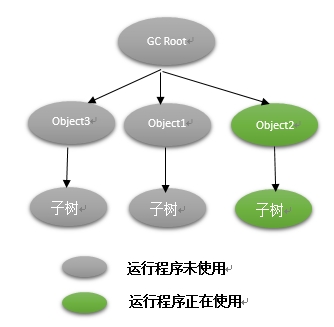
- 初始標記:該階段只標記GC Root節點(見上一篇)直接引用的節點,會造成STW,但是時間很短。圖中該階段Object1、Object3、Object2標記
- 並發標記:該階段是整個回收過程最耗時階段,對於程序正在使用的對象,程序運行和標記交替進行,而程序未占用的則可以直接標記,這樣程序整體對外停頓時間縮短(可以了解下並發的概念),減少了響應時間。該階段圖中Object1、Object3子樹正常標記,而Object2子樹並發標記。
- 重新標記:由於被程序占用的對象在一段時間后可能死掉,因此在並發標記結束后,可能有新對象死掉而未被標記,因此需要對這一部分重新標記。該階段圖中Object2子樹需要重新標記。
- 並發清理:該階段過程與並發標記類似。
CMS回收器的缺點主要在三方面:1、占用一部分CPU資源,導致吞吐量下降;2、由於並發過程是回收和程序運行交替進行,會產生一些新垃圾進入年老代而未被清理 ,當年老代滿時引起Full GC(因此一般年老代要預留一部分空間供程序使用);3、標記-清理的缺點——空間碎片,因此要適時進行壓縮。
Serial Old:沒啥好說Serial的年老代版。
Parallel Old:Parallel Scavenge的年老代版。
下邊我們來看一下幾個垃圾回收器的各方面對比:
| 名稱 | |
區域 | 算法 | 適用情況 |
| Serial |
串行 | 年輕代 | 復制 |
單CPU(或CPU較少)、小型客戶端應用 |
| Parallel Scavenge |
並行 | 年輕代 |
復制 |
多CPU、吞吐量優先(后台處理、科學計算) |
| ParNew | 並行 |
年輕代 |
復制 |
多CPU、響應優先(web服務器等) |
| CMS | 並發 | 年老代 | 標記-清除 | 響應優先(web服務器等) |
| Serial Old |
串行 |
年老代 |
標記-整理 |
單CPU、小型客戶端應用 |
| Parallel Old |
並行 |
年老代 |
標記-整理 |
多CPU、吞吐量優先(后台處理、科學計算) |
從上表我們可以總結:對於小型應用或是單CPU機上跑的應用,可采用Serial+Serial Old;對於web服務器等響應優先的應用:ParNew(Serial)+CMS;對於后台處理、科學運算之類的,可采用Parallel Scavenge+Parallel Old;當然,具體采用什么樣的搭配,還是要結合具體使用環境確定。
到此結束,睡覺嘍!